问题动机
本文发表在2017年,那时卷积神经网络仍是图像识别的主要工具,当前细粒度图像识别需要定位种属之间各个部件的视觉差异,主要依赖对各个部件进行边界框或者像素标注,然后对该部件进行专门的学习来解决细粒度图像分类的挑战。
后来使用卷积神经网络提取特征进行分类取得了一定成就,卷积神经网络不需要边界框,可以大大提高可用性和拓展性。卷积神经网络根据特征进行分类。但这样的架构完全没有用到部件标注信息,作者发现特征和部件是可以相互加强的,可以同时利用两类信息辅助学习。
简介
本文提出基于部件学习方法的多注意卷积神经网络(MA-CNN),用于没有边界框部件注释的细粒度识别任务。MA-CNN联合学习部件信息和特征信息,该架构可以从图像中识别出具有很强辨别能力的多个注意力区域。同时作者提出了用于让生成部件多样化的损失函数。
首先对卷积神经网络的特征通道分组,对于每个特征通道组,都可以通过聚类得到得到峰值区域的注意力图。将高响应区域构成注意力图的各个部分,再通过固定大小的剪裁提取多个部件区域。
一旦获得了部件区域,部件分类网络就会输入到每个部件各自专用的神经网络对基于部件的特征进行分类,并计算损失,这样的好处是不会受到其他部件的影响,可以特别优化各个部件相关的特征通道。
最后融合特征学习和部件学习的结果,并执行两个优化损失函数,用来指导特征通道和部件分类的学习,这促使MA-CNN从学习到更多不同的有判别作用的部件,并让部件和特征通道相互增强的方法学习到更多特征。具体来说,可以帮助网络学习到更多联系紧密和多样性丰富的部件。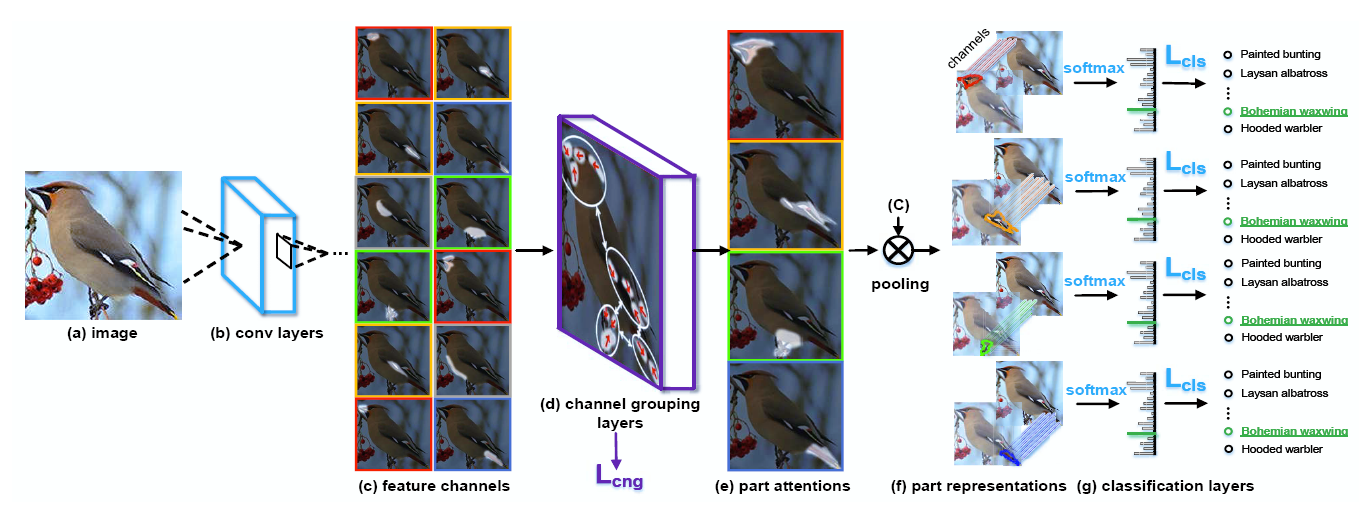
方法核心
传统基于部件的框架没有与学习到的特征相互增强。MA-CNN可以计算各个部件的注意力图,用于辅助图像分类。
部件定位
首先给定一个图像X,将其送入预训练的卷积神经网络中提取特征,得到的特征图的维度是(W,H,C),这样通道间的信息往往是独立的,很难表达丰富信息。于是作者提出一个通道分组加权子网络,将空间相关的各个通道信息聚合在一起,使部件内聚类紧密,部件间更有区分。该网络通过提取图片上的峰值区域,对每个组,作者使用了一个全连接层进行分类,将卷积特征输入,该全连接层将每个特征通道转换成一个向量,用于协助决定特征图的分组归属,再将特征图的各个通道分为N组。同时为了保证每个特征通道只属于一个组,作者还应用了后面提出的损失函数
对每个组应用sigmoid激活函数将特征图的权重和学习到的相乘,得到的矩阵表示一个部分的注意力图。
损失函数
作者为MA-CNN提出了两种损失函数,一种是部件分类损失和通道分组损失,总的损失函数就是分类损失和通道分组损失相加
分类损失
损失的前半部分是每个部件的分类损失函数,在部件融合了特征通道信息后,每个部件回单独进行一次分类,将每个部件的分类损失加起来。
分组损失
由于结果是由各个部件单独分类,所以获得高质量的部件至关重要,分组的目的是希望同组之间尽可能聚集,而不同组之间更加区分。所以分组损失也包含两部分。
其中表示同组内的损失函数,它会计算组间各点到其他点的l2距离总和。
表示组间损失,如果两组间的距离小于设定的边界,则会附加损失。由此,可以鼓励相似的视觉特征聚集在一起,而且尽可能捕捉到图中最有区分度的不同部件
优化策略
首先固定分类损失的权重矩阵,对分组损失应用分组损失进行优化,然后再固定分组损失,对分类损失的预测结果应用softmax,再根据类别标签进行优化,这种学习策略是可迭代的,对两类损失不再变化时停止
如图所示,对标-的区域进行优化,使之往标+的区域聚集,直到完成部件特征提取之后停止
联合部件和特征
由于部件的尺寸过小,不一定能有效表示局部的微小差异,所以需要对部件区域进行缩放,例如从448×448像素的图片找出N个96×96的部件,将其放大至224×224,再送入各自的神经网络进行分类。提取出N个部件以后,再在后面加上从图像整体中提取的特征,共N+1维,将其连接在一起后在送入softmax全连接层,用于最终分类。
实验
部件选择
作者比较了在数据集上不应用损失函数,单纯使用通道聚类,只是用通道分组损失函数,和一起使用的结果。作者发现,在只进行通道分组后,虽然可以准确框住部分部件,但是准确度并不高,并且有选择框有严重的重叠现象。在应用了通道分组损失函数以后,网络可以捕捉到多种不同的特征,但是仍然有选择框重叠的现象。在同时应用两种损失函数以后,各个选择框选择了不同的特征,而且框定的范围更加准确。
同时,作者将通道分组后注意力图可视化以后发现,在应用损失函数以前,注意力图在物体身上多个部位产生了峰值响应,倾向于将物体的所有特征全部覆盖;而在应用了损失函数以后,网络更倾向于将注意力集中一个特定的区域,可以表现出该损失函数显著的提高了部件分类能力。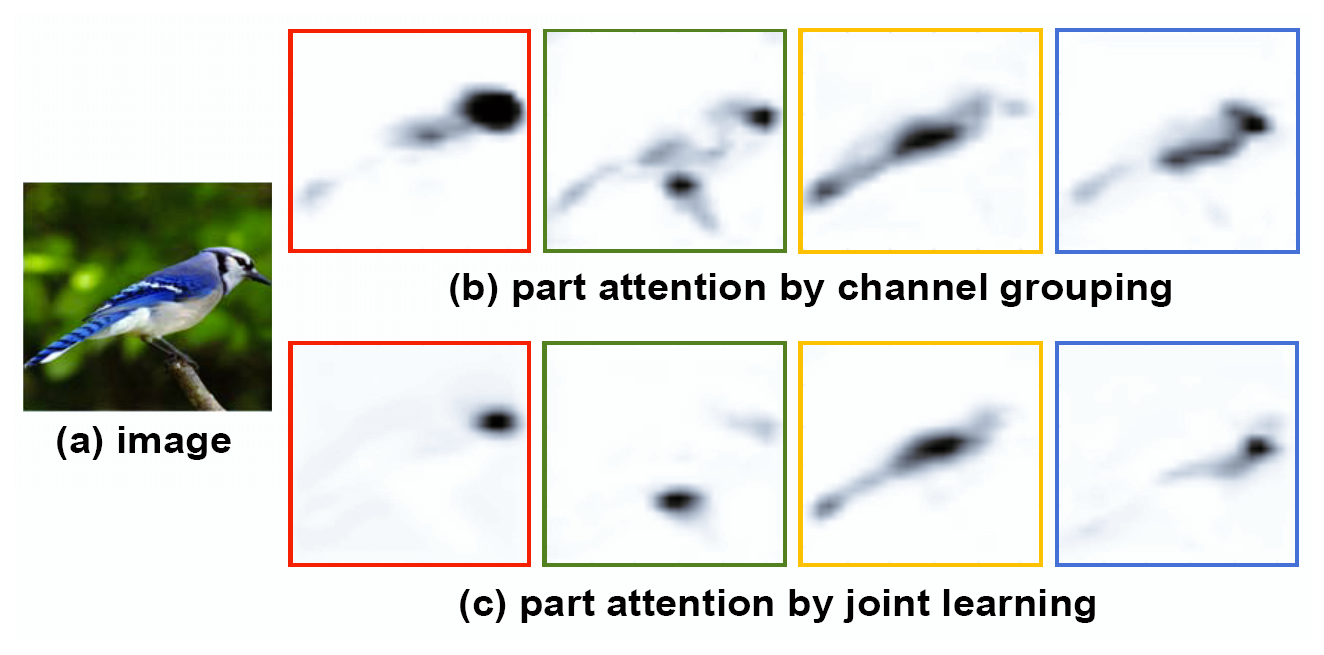
和只应用通道分组的分类精度进行了对比,应用通道分组损失函数后,精度提高了3.3%,在联合了部件和特征之后,精度进一步提高了1.2%
分类精度
MA-CNN不需要使用部件标注和边界框也可以获得相当优秀的精度,和Mask-CNN和B-CNN相比,在不实用部件标注和注释的情况下,达到了相同的精度。如果同时结合部件标注和边界框,在MA-CNN的基础精度上,可以再获得额外的1.4%的提升。这样的结果超过了使用更强预训练网络的其他模型。在融合了4个部件标注时效果提升最好,但当融合6个部件标注时性能饱和,因为4个部件对于判别鸟类已经绰绰有余
其他数据集
飞机数据集的背景相对来说更加清楚,作者使用4部件标注+原始图像获得的精度相对于原有基线B-CNN有了6.9%的大幅度提升。在汽车数据集上,汽车各个部件对分类精度的提升更加明显,比如某些车型可以通过车灯轻松识别。同时,MA-CNN提取到的判别性部件和人类看到的基本是一样的。作者使用无监督学习进行部分实验,提取的特征框精度和有监督使用边界框的其他架构相媲美。同时,哪怕多个部件区域过近,MA-CNN仍然可以区分。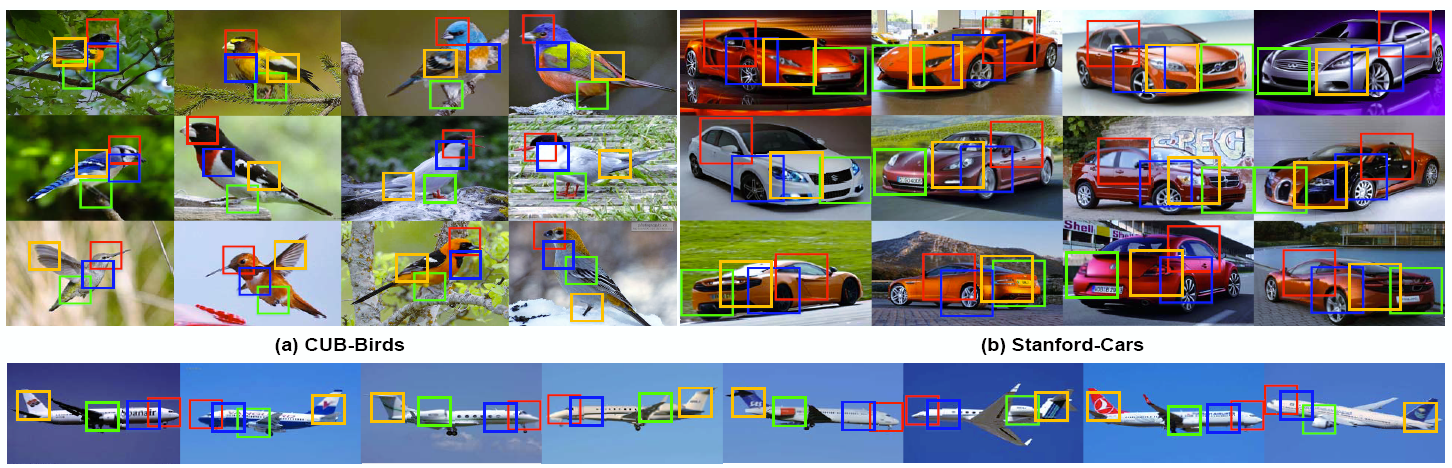
总结
作者在本文中对基于部件进行分类的卷积神经网络进行改进,使用特征通道分组的方法实现部件的聚类,再使用损失函数优化聚类结果。这和Transformer架构中的多头注意力十分相似,作者还将提取出的部件结果和卷积获得的特征信息相互融合增强,这也和注意力机制很像,在2017年Transformer还没有应用到计算机视觉领域,作者就已经提出了使用相关原理的方法。
在本文中,我觉得可以优化的地方就是分部件进行决策,各部件分别决策忽略了部件之间的联系,没有采取有效的方法将部件之间的关系相互融合。完全可以将各个部件的投影到一个多维向量,再将多个部件的信息连接起来,最后再连接上学习到的总体特征信息,将融合后的信息进行分类效果可能会更好,这就很类似于多头注意力的思想。不过本文的提出,对后来工作有着很大的启发。

若有收获,就点个赞吧
0 人点赞
