问题动机
目前将Transformer架构从语言任务移植到视觉任务的过程中主要有两大难题,一是视觉实体的规模差距很大,而在传统NLP任务上,输入数据的规模都是固定的。二是图像分辨率极高,和文本段落中的单词相比,图像像素的数量级更高,Transformer难以处理,因为注意力机制的计算和序列长度成二次方。本文中,作者希望拓展Transformer的适用性,使其可以成为像ResNet一样的通用主干,提出了优化方法,让Transformer对图像拥有线性复杂度,因此可以高效的用在图像分类和目标检测这种密集的任务上。
简介
本文提出了Swin Transformer,和普通的ViT相比,可以合并更深层的图像块构建分层特征图。由于只在窗口内部的各个小块之间计算注意力,而不是所有小块之间,而窗口的尺寸是固定的,所以对于图像只具有线性复杂度。
以上的方法无法建立起窗口之间的联系,以前的方法是在同一张图上使用移动窗口,但是这样会导致计算量骤增,同时产生很多冗余。所以Swin Transformer的关键就在于它是在不同自注意力层之间移动窗口分区。移动的窗口提供不同的划分方式,由此同样可以连接之前各个窗口之间的信息,而且移动窗口对于减少硬件计算的延时有很大帮助,同时建模能力相似。
Swin Transformer架构在图像分类、目标识别、语义分割上取得了相当大的突破,并且因为和语言任务使用的是统一架构,可以促进跨领域联合建模。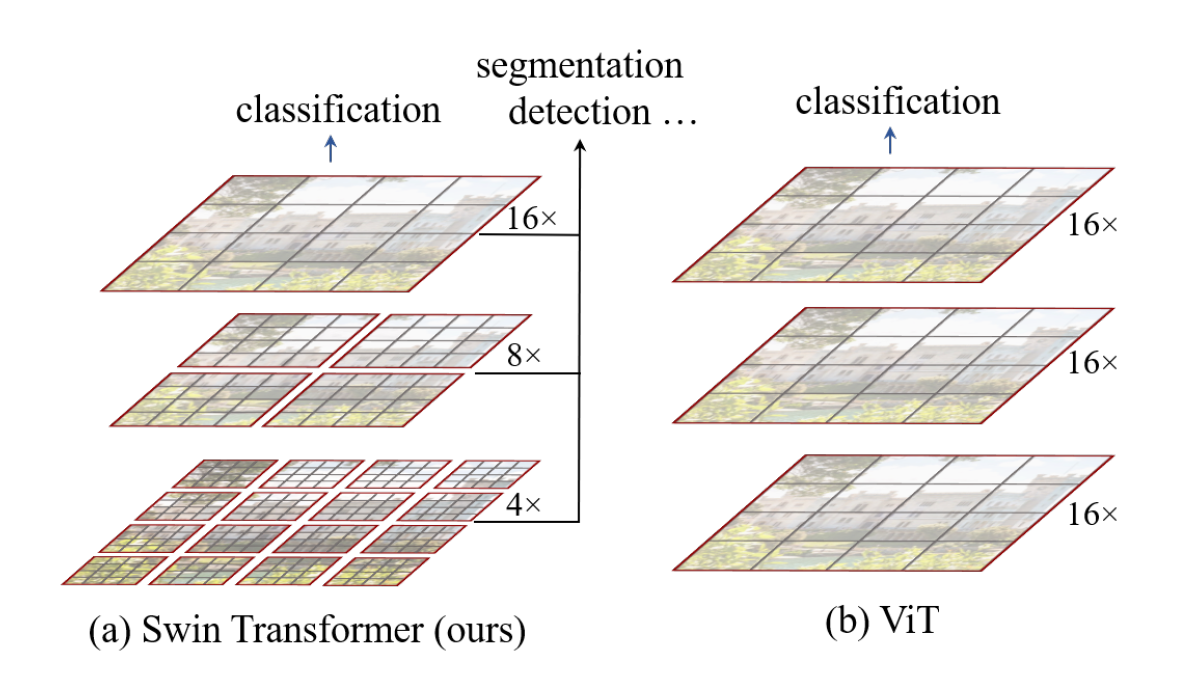
方法核心
总体架构
首先将图片拆分成若干个不重叠的小块,随后使用嵌入层投影到一个固定的维度C,然后应用若干个Swin Transformer模块,本架构将投影和应用模块的操作和CNN提取特征一样,成为一个阶段,在下一个阶段的嵌入层中,会将上一个阶段产生的小块按2×2一组进行拼接,然后重新投影到2×C维,以此类推。
这样方法的好处是,各个阶段输出的小块数量和传统CNN的特征图尺寸是相同的,因此可以很容易的替换掉现有架构中的主干网络,大幅度拓展了适用性。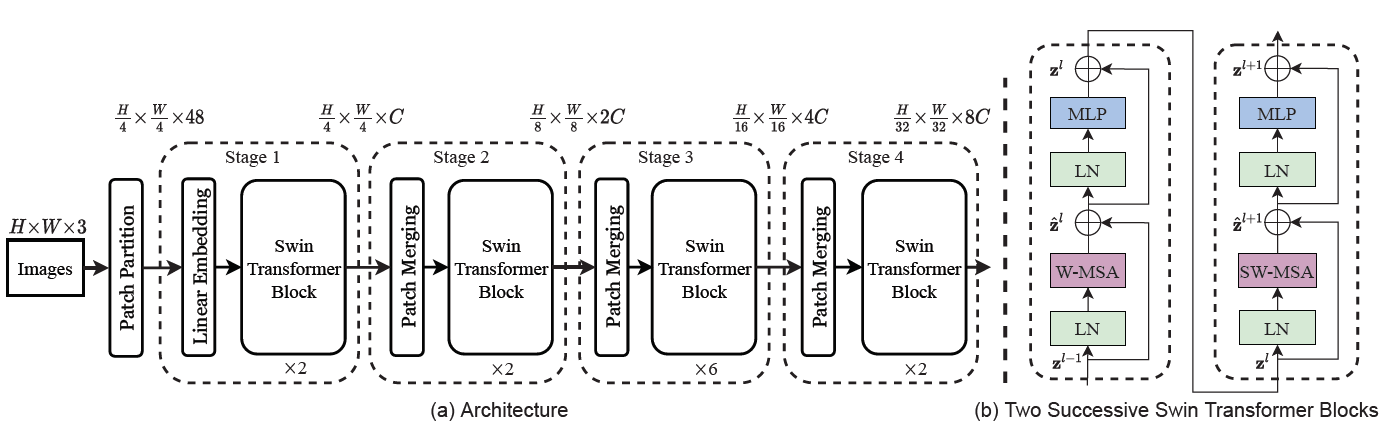
移动窗口
非重叠窗口内的自注意力
如果一个窗口中包含M×M个小块,只在窗口之间计算注意力,并且每次滑动一格,那么时间复杂度为,其中hw首次划分的小块总数,由于M是常数,所以时间复杂度被降到了和原始图总像素数的线性相关
层间窗口滑动
以上的方法无法连接窗口之间的信息,所以本文提出了一种新的方法,在Swin Transformer模块中包含了多个Transformer层,在每层里窗口的划分都不相同,首层以左上角为起始点划分,下一层则将划分的起始点向右下移动2个小块的位置 ,通过多次不同的滑动,可以融合不同窗口之间的信息,达到和传统ViT对所有小块计算自注意力相似的建模效果
但是这样带来一个问题,不均匀的拆分方式会导致拆分的窗口数量变多,会导致输入数据的维度不确定,同时过多的窗口带来额外的计算量。为了解决这个问题,可以将多出来的窗口填成M×M,但是这样做会进一步增加额外的计算量,特别是对于较小的窗口而言
于是本文提出了一种全新的高效计算方法。首先通过相对位置编码对每个窗口进行编号,再使用矩阵平移的功能,将零散的窗口拼接到一起,形成均匀拆分M×M的新窗口。对新窗口计算注意力时,会屏蔽掉编号不同的小块,只有具有编号的窗口之间的小块才会计算自注意力。
在具体实现时,进行注意力计算时需要用到softmax操作,这里可以将不同编号窗口的键值对的值-100,输出几乎为0的结果。
不使用相对位置偏差
作者发现如果对其加上传统的位置偏差矩阵B,性能没有额外的改进,由于在计算注意力机制时,已经附加了一个偏差B。
如果额外附加位置编码,性能反而会有下降,所以在文中,两种方法都没有使用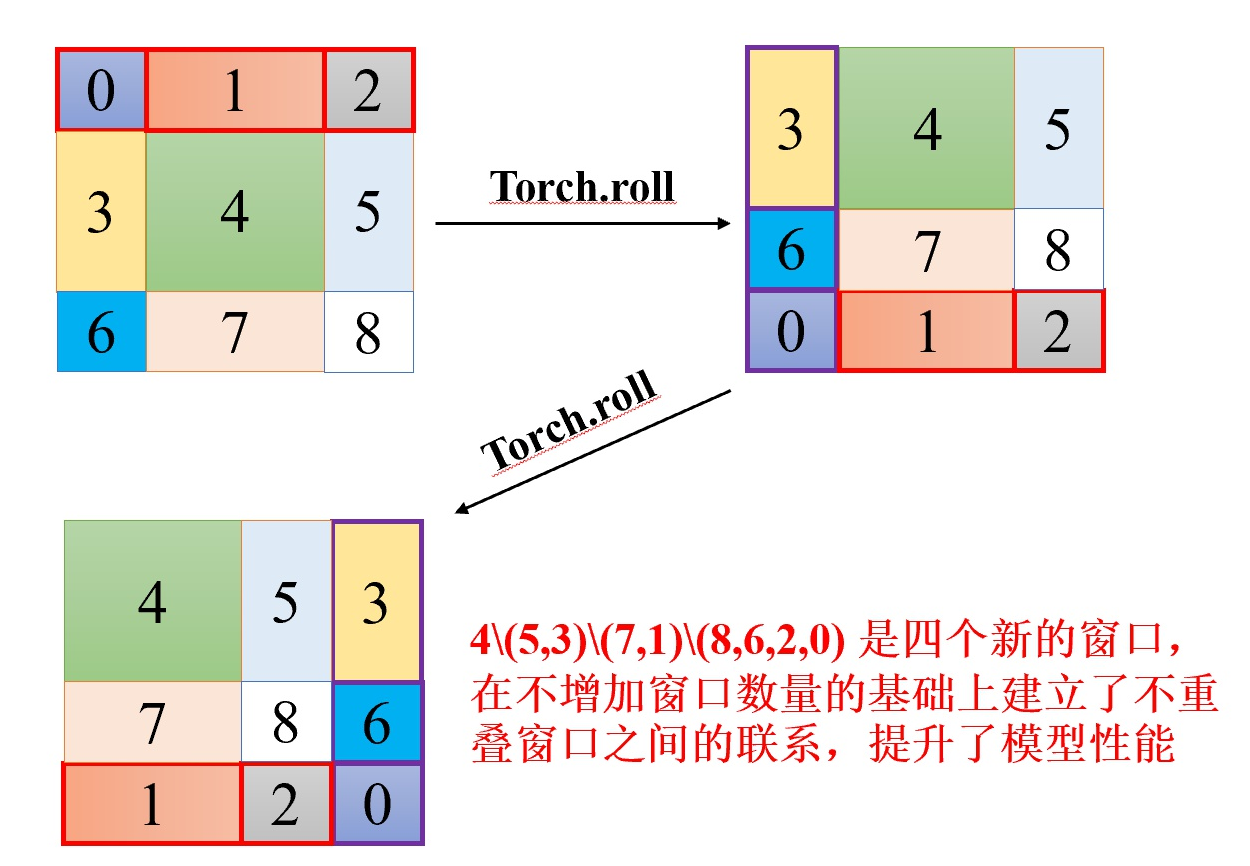
基础模型
作者按照不同的规模,构建了Swin Transformer模型,其中Swin-B是基础模型, 有着和ViTB/DeiT-B 的模型大小和计算复杂性。
实验
在ImageNet图像分类任务上,与目前最先进水平的Vision Transofrmer架构DeiT相比,Swin Transformer使用更小规模的网络,Swin-T仍然比DeiT-S精度高1.5%。在使用基础模型的情况下,使用不同尺寸的图像输入,精度分别比DeiT-B高1.5%和1.1%
与目前最先进水平的CNN架构相比,Swin Transformer实现了更好的速度/精度平衡。不过RegNet和EfficientNet使用了彻底的参数搜索/架构搜索,几乎没有继续改进的空间,而本文提出的Swin Transformer仍然具有强大的改进潜力
如果使用更大的数据集和进行预训练,并且使用更大规模的模型,在ImageNet1k上进行微调,比重头开始训练带来了1.8%的收益,和CNN的最佳预训练结果相比,本架构获得了相当好的性能精度比,和ViT最佳预训练相比,训练时间减少5倍的同时,精度有着1%左右的提升。
消融实验
移动窗口
作者在三个任务上进行了移动窗口方法的实验,和对所有小块统一计算相比,Swin-T在每个阶段的性能都优于传统方法,在ImageNet上精度提高了1.1%,同时移动窗口的计算延时也十分小,远远低于传统方法
位置信息
作者列出了多种嵌入位置信息的方法,和完全不嵌入信息相比,ImageNet获得了1.2%的精度提升,其余的方法比如同时嵌入位置信息和偏移矩阵、嵌入绝对位置信息反而会导致性能下降。作者发现,在使用绝对位置信息反而会导致目标检测性能下降,虽然最近的模型比如ViT和DeiT放弃了平移不变性,不过对于目标检测和语义分割人物而言,对平移不变性十分有效的归纳偏差仍然表现更好。
自注意力方法
和一般的自注意力方法,即填充法相比,作者所提出的拼接发带来了13%~18%的性能加做。和传统自注意力方法相比,作者提出的移动窗口法在网络的各个阶段,性能最高提高40%。
与素对最快的Transformer架构Performer相比,作者的计算速度仍然略快的同时带来了2.3%的精度提升。
总结
本文针对Vision Transformer的特性,提出了一种全新的对图像拆分的方法,这种方法很大程度上解决了ViT的计算量问题,将原本需要二次复杂度的自注意力算法降低到了线性复杂度,同时仍然可以保证各个小块之间获得完整的上下文信息,可以说是突破性的进展。
不过这样的拆分我个人认为仍然会出现一些问题,因为每次划分都会从左上角开始拆分,这样左上角的窗口,就很难联系到右下角窗口的信息,哪怕是在最后一个阶段,只有少数几个窗口时。为此,我认为可以在窗口之间重新应用另外一个Transformer架构,专门用来融合各个窗口之间的信息。同时,这样操作后,可以增加每次窗口划分时的步数。
每次合并窗口的时候,选择的是2×2相邻的四个窗口,是否可以有别的合并方法,比如交错,这样可以缓解跨区域信息的融合
同时针对细粒度问题,我认为可以调小各个小块的尺寸,防止窗口切割时将重要信息分割开来,同时因为细粒度图像识别更在意局部特征,TransFG找出的是最重要的小块,这里可以找出最重要的窗口。
Swin Transforemer大幅度优化了目标检测和语义分割的性能,那是否可以将其应用到细粒度任务中,先检测出目标或分割出实体以后,再进行细粒度分类。

若有收获,就点个赞吧
0 人点赞
