问题动机
过去的细粒度图像识别工作往往会明确选择判别部件,或者通过CNN的方法集成注意力机制来寻找判别性特征。不过这样的方法增加了计算复杂度,并且模型惠更倾向于关注包含整个对象区域。
Transformer使用全注意力机制来自动的搜索判别性部件特征,并且融合到类别标记上,不过深层的标记更关注全局信息,缺乏局部信息和低级特征,局部信息在细粒度图像识别中起着重要作用,因此ViT的缺陷限制了细粒度图像识别的性能。
简介
本文提出了一种新颖的完全基于Transformer的用于细粒度图像识别的框架,特征融合ViT(Feature Fusion Vision Transformer, FFVT),可以自动检测判别性区域,并且聚合来自低级、中级高级标记的本地信息,从而方便分类。具体来说,本文提出了一种重要的标记选择方法,称为注意力力权重选择(MAWS),选择每一层上的代表性标记,这些标记被添加到最后一层Transformer的输入中。
同时本文探索了本放在一个大规模和两个小规模数据集上的性能,都实现了最先进性能,和主干网络相比,本方法在鸟数据集上,性能提升了0.8%。
方法核心
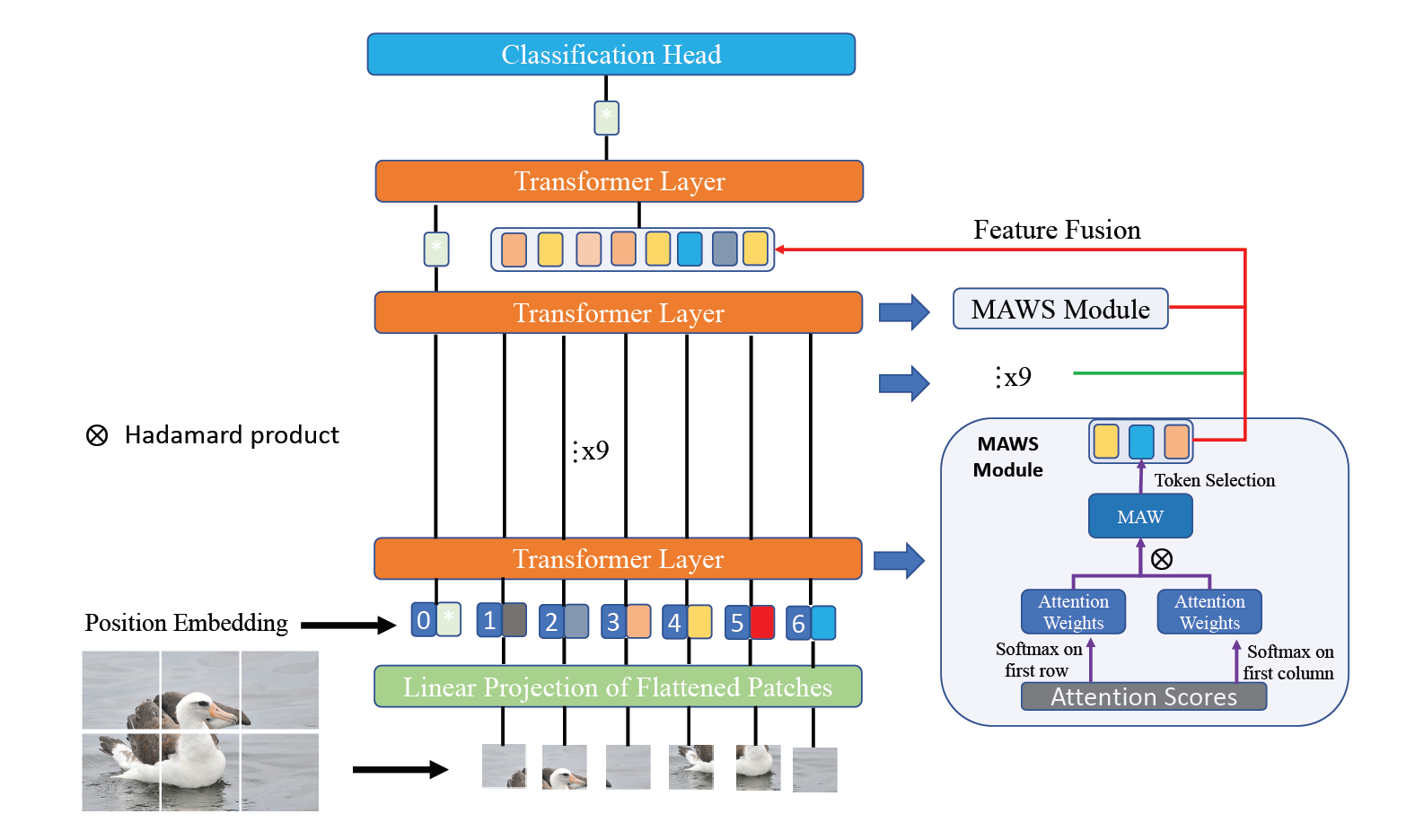
特征融合模块
由于深层的多头注意力机制更注重于全局特征的提取,所以本文和TransFG相似,在最后阶段只输入选择的标记进行最后分类结果的预测,对于每一层,选择K个,一共L-1层,将选择的标记连接成一个矩阵。所以和TransFG相比,本文相当于聚合了每一层的信息
相互注意力权重选择模块
由于每一层都有N个标记,如果重复选择了背景,则会增加输入的噪声,反之,如果频繁选择判别性部件的小块,则可以提高性能。所以本文提出一种利用多头自注意力模块生成注意力分数的标记选择方法。
注意力图的尺寸为(N,N),记录每一个标记对于其他各个标记的注意力分数,当然可以简单的选择较大的K个标记来选择小块,比如可以选择分类标记里注意力最大的K个标记,不过这样会引入嘈杂的信息,因为注意力机制的工作原理,每个标记都包含了大量的信息。
比如如下的三个标记的注意力得分矩阵,其中表示类别标记
虽然都有最大的注意力分数,不过标记都包含了噪声,于是本文提出了相互注意权重选择模块,他要求被选择的模块和分类标记相似,不光在上下文相似也要和标记本身相似。
具体来说,将注意力得分矩阵的第一列记为,表示在其他标记的上下文中,与分类标记的上下文中的相比,分类标记和其他标记之间的注意分数向量。所以指定标记和分类标记之间的相互注意力权重为,简单来说,就是计算第一行和第一列对应元素的指数乘积
对于多头注意力机制,首先平均所有头的注意力分数,得到相互注意里权重后,根据相互注意力权重选择重要的标记,本方法不会引入额外的学习参数,和TransFG的矩阵乘法相比,更加高效。
实验
分类精度
和目前最先进水平比起来,本文提出的FFVT达到了91.6%的精度,因为使用的是不重叠分割方法,所以本文大幅度减少了计算量。
消融实验
本文对鸟数据集进行了消融实验,对比了单一注意力选择方式,即TransFG的方式,可以将分类精度提高0.6%,而如果使用了本文提出的相互注意力权重选择模块,可以获得更大的改进,达到0.8%,充分证明其可以更好的利用注意力信息
因为相互注意力权重选择模块明确的选择了有用的标记,从而迫使模型冲这些信息中学习
总结
本文提出了一种新颖的小块选择方法,不本方法思路简单,在每一层选择小块时同时考虑类别标签上下文的信息,选择上下文信息乘积最大的若干个小块。通过实验来看,准确率大幅度提升,不过本文对多头的注意力图仅仅是做了简单相加,这样可能会影响各个注意力头寻找不同的区域。
我觉得可以对注意力图的处理方法进一步的改进,比如使用加权相加,或者乘积的方式,对更有判别力的注意力头给予更大的权重,具体来看,可以计算不同注意力头注意力的的分散程度,对于更加集中的注意力头给予更高权重。

若有收获,就点个赞吧
0 人点赞
