问题动机
Transformer最近在计算机视觉领域发展很快,他采用类似于自然语言处理(Natural Language Processing,NLP)下训练的策略,先进行大量数据集的预训练,在对目标数据集进行微调(Fine-Tune),其中Vision Transformer(ViT)在分类精度上非常有竞争力,但是需要巨量的训练数据和计算量,然而如果只将ViT只用作监督学习,除了精度高一点,ViT和其他架构比起来并没有突出的特性(Properties)。于是作者质疑ViT是否只能在比精度这条赛道上进行发展,在自然语言处理上是使用自监督预训练(Self-Supervised Pre-Trained),在视觉上能否可行呢。
简介
自然语言处理是先通过简单的单词、句子积累学习信息,而图像是通过将一张图的信息简化为一种分类,同时模型学到了图像纹理、颜色、形状等底层特征。
基于以上研究,作者设计了一种简单的自监督学习方法,可以从没有标签的图片中提取特征,作者将这种架构称之为DINO,该架构不光可以灵活应用在卷积神经网络和ViT中,通过研究 自监督预训练对ViT内部特征的影响,发现了该架构突破性新特性
- Vision Transformer通过自监督学习到的特征可以显式(explicitly)表示在场景布局上,特别是对象边界信息
- 自监督ViT在最基本的K近邻分类器上,且无需进行任何微调、数据增强,都可以有着出色的表现

DINO以ViT做主干网络时,在ImageNet上达到80.1%准确度,超越之前所有的自监督学习方法,在实际应用中,可以比自监督卷积神经网络有更高的精度,并显著降低计算量。同时该自监督架构可以应用在多个计算机视觉的领域上。
相关工作
视觉Transformer
Vision Transformer处理图像的主要思想是将每张图像拆分成多个长宽相等的小块,小块的尺寸一般是8×8或者14×14,将每个小块展平(Flatten),并加上位置编码,作为序列信息输入到Transformer的编码器中,在编码器的输出结果后,加入一个多层感知机输出分类结果。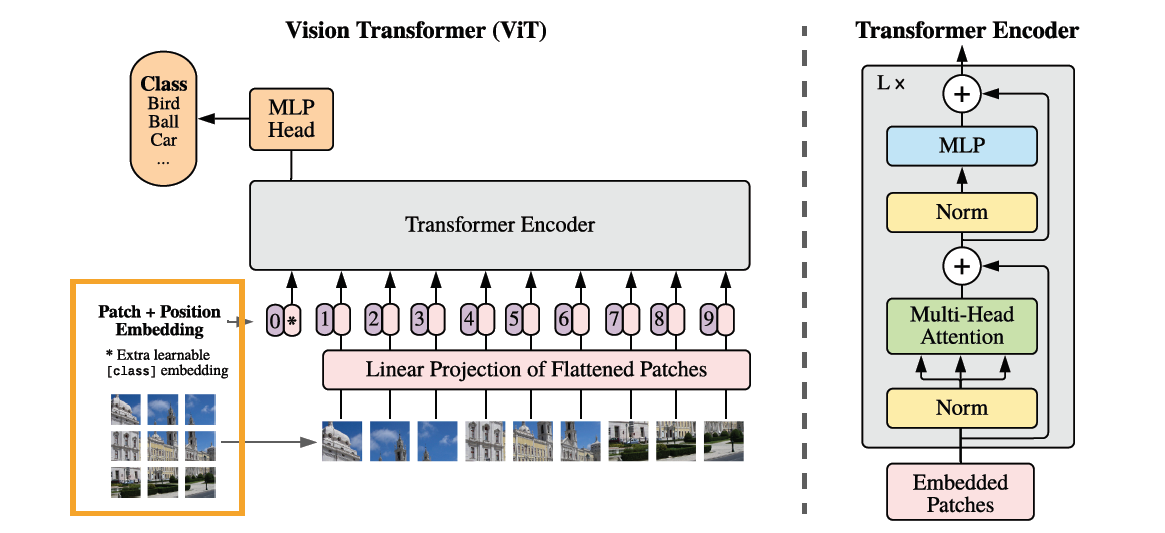
自监督学习
自监督学习是使用无标注数据用自我监督的方式学习一种表示的方法。具体应用有图片上色,图片抠图位置预测,视频帧顺序预测等。
监督学习的图像分类是将每幅图像视为不同类别,提取特征后,然后进行区分,这样的问题是,如果只想提取特征,训练所需的图像数量和学习到的特征不成比例。最近的研究发现,完全可以在不分类图像的前提下,使用自监督学习方法来学习图像上的特征,作者正是受这样的启发才实现这篇论文
知识蒸馏
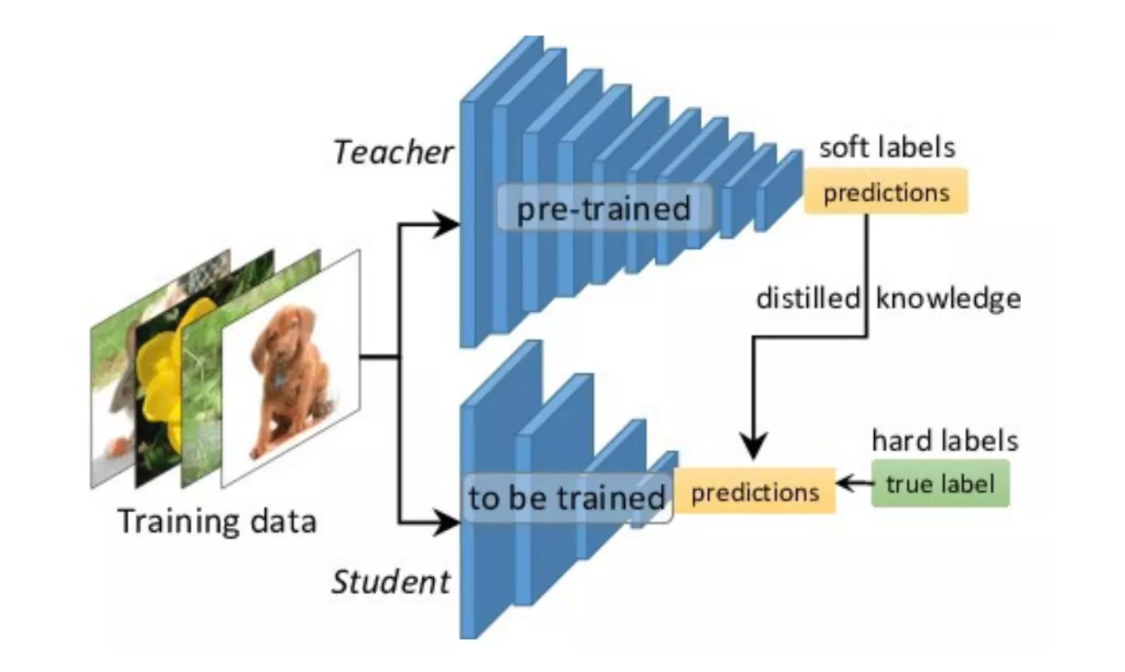
知识蒸馏(Knowledge Distillation)是使用一个已经预训练好的老师架构来辅助学生架构进行学习,将预训练好的知识提炼到学生架构上,老师架构输出的结果是软标签,即输出的是各个类别的概率,包含了不同类别之间相互的关系,比直接用真实标签更容易收敛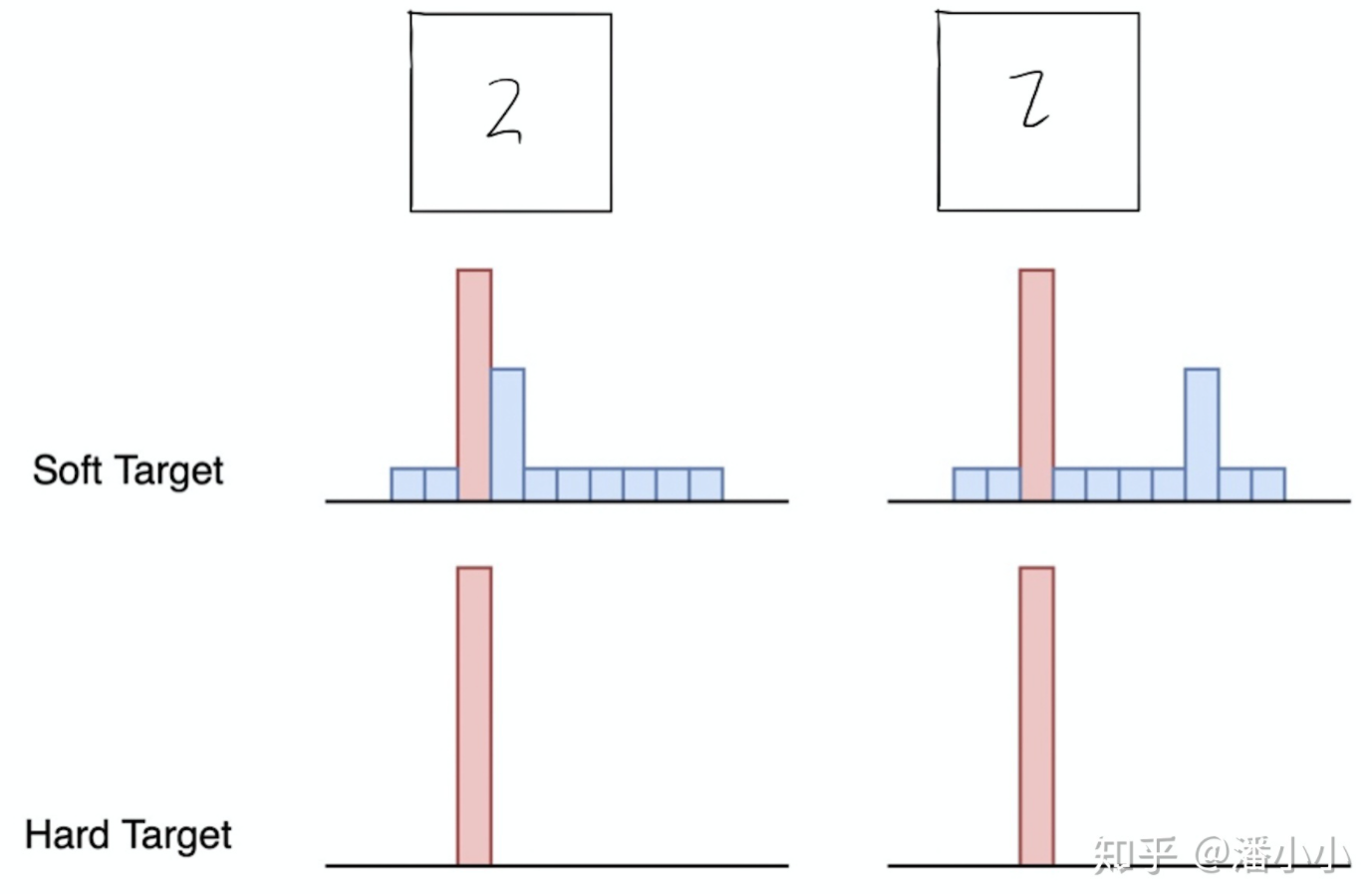
K近邻
K-近邻(k-Nearest Neighbors,K-NN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近样本的大多数属于某一个类别,则该样本也属于这个类别(这就类似于现实生活中少数服从多数的思想,也可以理解为近朱者赤,近墨者黑)。
方法核心
自监督知识蒸馏
过去的老师网络的架构需要进行预训练,而且通常和学生网络的架构不相同。作者根据之前工作的启发,便提出了本文的DINO架构。
这个架构的核心方法是让学生网络的输出去匹配老师网络的输出。在这个架构中,学生和老师网络的架构相同,老师网络也不需要额外进行预训练。首先将输入的图像x进行随机变换,输出x1,x2传递到学生和老师网络中,老师网络额外多了一步,将输出结果中心化(centering),即该批量的输出减去该批量的均值,保证输出均值为0
再将各自将输出结果通过softmax层以输出概率,最后用交叉熵损失函数来衡量两者的相似性。反向传播时不对老师网络进行梯度计算,只通过学生传播梯度,老师参数用学生参数的指数平均移动值[1]进行更新。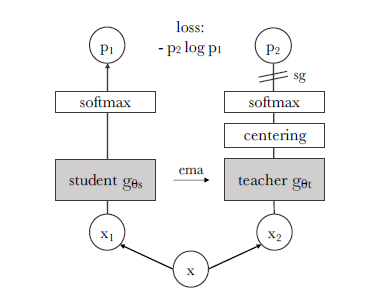
为了保证老师拥有更多信息,在对输入图像进行变换时,倾向于给老师全局视图,覆盖原始图像的大面积(例如大于50%),而给学生局部剪裁的较小视图,覆盖原始图像的小面积(例如小于50%),本文使用的都是这种策略。
老师网络
因为老师网络没有对比损失,所以通过学生网络过去的迭代来构建,不过通过输入更高质量的图像足以让老师网络的表现比学生网络好。在知识蒸馏时,还可以使用一个温度参数(temperature parameter)将老师的预测概率进行增强,让输出各类概率差距更明显,文章中称为锐化(sharpening)
网络结构
整个网络结构(Networks architecture/configuration )由主干网络和投影头部组成,主干网络是用Vision Transformer或者ResNet,头部网络使用一个带l2正则项的3层的多层感知机输出结果。为了防止老师和学生网络相同,经过作者的测试,在整个网络中不使用任何批量规范化(Batch Normalization)的效果更好
避免退化解
自监督学习的聚类过程中容易出现退化解的问题,即所有输入输出合成一类,没有分类的能力,上面讲到,老师网络有中心化和锐化两种优化方法,其中中心化鼓励输出均匀分布,而锐化鼓励输出的一个维度占主导地位,当单独使用中心化或者锐化时,DINO无法正常训练;当同时使用中心化和锐化时,可以避免退化解。
实验结果
作者在众多计算机视觉的应用中测试了自己的架构。
在图像分类任务中,分别使用k近邻算法和线性分类器进行自监督图像分类的测试中,主干网络使用ViT-S和ResNet-50,其他自监督模型使用同样的主干网络,作者的DINO架构都获得了最好的成绩。
在图像检索(Image Retrieval)、重复检测(Copy detection)、视频实例分割(Video instance segmentation)任务中,以ViT为主干的DINO都取得了当前最好的准确率。
使用迁移学习应对各类数据集,DINO架构使用ViT-S主干取得了几乎所有数据集上最好的结果
探索自注意力图
作者展示了不同头部关注的注意力的语义区域,注意力图再不需要任何优化的情况下输出的结果可以直接在场景上进行可视化。有监督的ViT不能很好提取存在噪声和杂波的对象的特征。
消融实验
消融实验(Ablation Study)是指,通过删除神经网络的部分模块,来观察输出的结果的变化,以此来研究网络各部分的重要性。类似控制变量法,比如你论文提了三个贡献点:A、B、C:
- 去掉A,其它保持不变,发现效果降低了,那说明A确实有用。
- 去掉B,其它保持不变,发现效果降的比A还多,说明B更重要。
- 去掉C,其它保持不变,发现效果没变,那C就是凑字数的。
各部分重要性
作者发现动量法,也就是更新老师网络时使用的学生参数的指数平均移动值是最重要的,如果不使用这种方法,网络几乎无法工作,其次是交叉熵损失,如果使用均方差损失,网络性能会有大幅度下降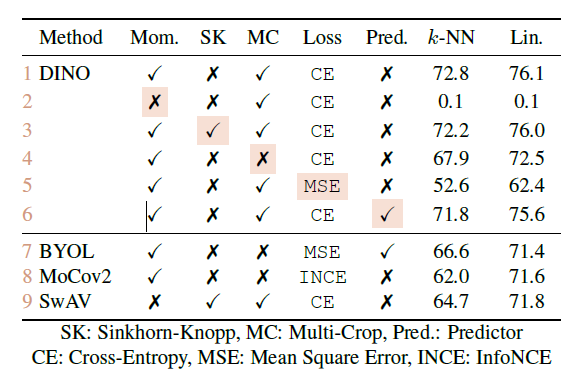
视觉Transformer小块的尺寸
作者使用了16×16,8×8,5×5大小的小块,使用k近邻算法在ImageNet上评估精度,结果表明,随着缩小小块的大小,性能得到了显著的提高,然而小块变小会导致一个图片的序列更长,降低吞吐量,影响运算速度Impact of the choice of Teacher Network
Avoiding collapse
涉及到的其他内容太多,这两部分跳过计算需求
经过作者使用各种尺寸ViT训练DINO架构发现,在同样算力的训练下,DINO架构的表现优于目前基于卷积神经网络的自监督学习架构,并显著减少了计算量需求,可以在数量有限的GPU上训练自监督ViT。批量大小的影响
作者尝试了使用不同批量大小来观察对精度的影响,当批量大小为128,256,512时,精度会比本文的1024略。其中批量大小为128时,精度下降的更多,而且需要重新调整超参数。总结
在这篇论文中,作者展示了自监督预训练ViT模型的潜力,可以和精心设计的最佳卷积网络相媲美。同时,该模型还有着可以在不同任务中应用的特性,例如使用k近邻进行图像检索,使用训练的特征信息进行弱监督语义分割等等。本文证明了和一样BERT使用自监督预训练是Vision Transformer未来发展的关键。
- 越新的动量权重越大,过去的动量的权重以指数速度下降 ↩︎

若有收获,就点个赞吧
0 人点赞
