问题动机
目前,以自注意力机制为基础的Transformer架构在自然语言处理(NLP)上应用十分广泛,通过预训练大量的数据,可以在微调后就取得相当好的成果。
但是在计算机视觉领域,CNN仍然是主导,其中SOTA则是几年前的ResNet相关架构。大部分科学家只是将Transformer架构的一部分融合到CNN中。比如只将自注意力机制应用于局部区域,尝试使用多头注意力代替多通道卷积,也有用伸缩的近距离观测,观察不同大小的区块,用于模拟CNN的下采样,这些研究也取得了一些结果,但都需要大量硬件算力的支持
核心思路
作者将每张图像拆分成多个小块,并加上位置编码,再将每个小块展平,作为序列输入到Transformer的编码器中,在编码器的输出结果后,加入一个最基本的多层感知机输出分类结果。
传统Transformer不同的是,作者只使用了编码器部分。一个编码器块的组成如下图
- 将已经拆分并加入位置编码的信号按照顺序进入编码器
- 首先进行层规范化
- 将规范化结果送入多头注意力机制块
- 将多头注意力的输出结果和规范化后的结果相加
- 再进行一次层规范化
- 规范化结果送入一个多层感知机
- 将多层感知机的结果和层规范化的结果相加
- 输出最后结果
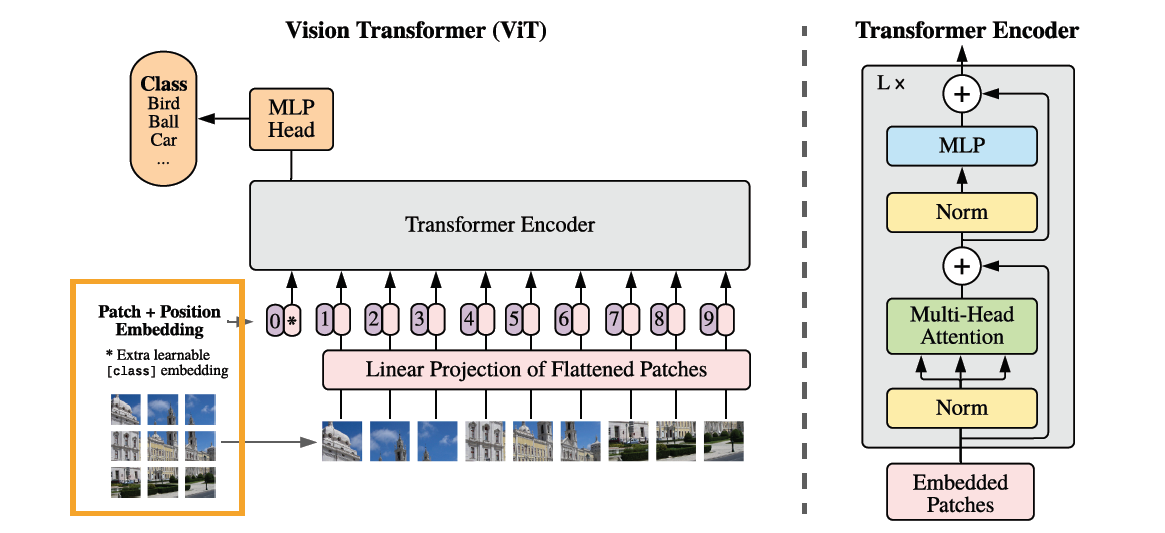
在模型设计中,作者尽可能的遵循原始Transformer架构,好处是不需要进行额外的参数调整就可以直接用作图像分类
方法细节
原始图像的尺寸为(H,W,C),现在将其切割为(P,P,C)的小块,为了保证最后一维尺寸相同以便输入多层感知机,将前面的维度合并,并使用尺寸为D的嵌入层,将其映射到D维,最后输入尺寸是(P^2·C,D)
关于位置编码,作者尝试了多种位置编码的方式,最后选择以为位置编码,更高维的位置编码并没有得到显著的提升
多头注意力自注意力机制是Transformer架构原始的方法,使用了和ResNet类似的残差连接方法,每个残差块之前应用层规范化(Layer Norm,LN)
在多层感知机的激活函数上,作者使用的是和语言分类模型BERT一样的GELU激活函数,以保持参数的一致性
归纳偏置
作者注意到在Transformer中归纳偏置学习的比CNN中少的多,这也是这个架构常见的问题,在ViT中只有多层感知机可以识别局部信息和平移变换,而自注意力层则关注全局信息。所以在二维领域信息需要根据不同分辨率调整不同的位置信息编码,这会导致小块之间的位置信息必须从头开始学习。
混合架构
作者也尝试了直接将CNN的特征图按照每个小块1×1输入到架构中,相当于将整个特征图按照每个像素展平并投影到D维作为Transformer的输入
预训练和微调
为了保证预训练的可行性,在解码器输出结果后接入一个多层感知机输出分类结果,可以方便以后做迁移学习。虽然该模型可以输入任意大小的图像,在保证每个小块大小相同的情况下,序列长度更长,但是预训练的位置信息则不再有意义,所以作者在则新图像上插入基于原图像位置的对应2D位置信息
实验过程
数据集
作者比较了ResNet,Vision Transformer(ViT),和上面提到的混合模型进行比较,使用的数据及包括ImageNet-1k,ImageNet-21k,JFT-18k,其中后两者拥有大量分类和大量数据。
模型变体
ViT使用的是BERT的模型参数,根据参数数量可分为Base和Large尺寸,作者额外增加了Huge模型,拥有更多的层,隐藏层大小和参数量。其中小块越大,序列越长,所需要的计算性能也就越多。
ResNet在原本的基础上将批量规范化替换成组规范化,并加入其他改进。
混合模型则将中间特征图输入到ViT中,为了保证输入的正确性,将调整ResNet50第四阶段的输出
使用的优化器统一是Adam
实验结果
实验结果发现,在小型数据集上,Transformer架构表现不如CNN,归纳偏差方面不如CNN架构,在数据不足时不能进行很好的泛化。
但是在超大规模数据上(ImageNet-21k,JFT-18k)使用预训练模型,作者提出的不同尺寸的Transformer架构的性能可以持平或者略微超过目前最先进的ResNet架构,与此同时,训练需要的计算资源要少的多。更大尺寸的Huge模型在超大型数据集JFT-18k表现则更加出色。
预训练数据集大小的影响
在使用中小规模数据集预训练的情况下,作者提出的ViT模型表现不如ResNet,出现了比较严重的过拟合,在很小的与训练数据集表现的则要比ResNet差的很多。只有在使用JFT-18k数据集进行预训练时才能体现ViT的优势。
训练成本
混合模型在使用较小的计算成本的情况下可以得到最好的结果,ViT次之,ResNet需要的训练成本更高,总的而言,在模型性能/训练成本的比例上,ViT比ResNet有着更好的表现。
混合模型在小数据集上的性价比比ViT更好,但是在大数据集上,这种优势就消失了。
过程可视化
在低层的多头自注意力机制学习到的信息一样是比较低级的信息,不过多头注意力中的部分头哪怕在低层也可以感受到相当大范围的内容,这表明了该模型可以使用全局集成信息的能力。随着深度增加,每个头部的注意力距离都会不断增加。
自监督学习
作者还模仿了和BERT类似的机制实现自监督预训练,在ImageNet上实现了79.9%的准确率,虽然人比监督预训练落后4%,但说明该模型拥有者广阔的前景
自己思考
该模型在大型图像分类任务表现出了很好的性能,但是在仅有小规模图像数据预训练的情况下表现不如ResNet,能否通过改进模型减少对数据量的需求。
该模型的解码器部分是直接从BERT移植过来的,能否进行进一步改进提高性能
数据输入的时候输入了一维位置信息,作者使用了二维位置信息,但是提升并不明显,能否改进位置编码的形式,使其具有更强的偏置归纳能力,更好的融合相邻小块的信息。

若有收获,就点个赞吧
0 人点赞
