问题动机
目前基于部件的学习方法无法很好的利用部件之间的关系,通常孤立的处理各个部件,或者只在单独一个样本中建立联系,没有充分考虑到部件在不同图像之间的联系。有研究者尝试采用了弱监督的方法来处理细粒度图像识别的问题,避免了对部件标注的繁重劳动。弱监督图像识别主要有两种方法,一种是利用细粒度标签之间的关系来规范特征学习,另一种是定义辨别性部件。不过这些方法对样本的选择有较高的要求,同时需要专门定义特殊的损失函数进行优化,缺乏稳健性,无法很轻松的拓展到大型项目上,同时性能提升有限
简介
本文提出了一种可以利用不同图像之间和不同网络层之间的关系进行稳健的多尺度特征学习的网络Cross-X。其中涉及到两个新组件:
- 跨类别跨语义正则化器(C3S),用于知道提取的特征来表示语义信息
- 跨层正则化器(CL),通过匹配育才来提高多尺度特征的稳健性
本架构首先通过多个激励模块生成注意力区域特征,然后使用C3S来引导来自不同激励模块的注意力特征来表示不同的语义部件。理想情况下相同语义部件注意力特征,尽管来自具有不同类别标签的不同图像,但应该比不同语义部件的注意力特征更相关。所以C3S会最大化同一个激励模块提取的特征相关性,降低不同激励模块提取特征的注意力相关性。和传统度量学习损失相比,C3S可以自然的集成到模型当中,不需要额外的采样步骤。
为了更好的利用不同网络层之间的关系,首先使用特征金字塔网络合并特征,获得良好的空间分别率和语义信息,CL通过最小化不同阶段特征图的预测结果的KL散度,让中级特征和高级特征输出的预测分布相匹配,通过正则化特征提高不同层特征的稳健性。
该方法可以进行端到端训练,在五个基准数据集上进行实验,取得了和目前最先进水平相持平的精度,本模型也可以拓展到大规模数据集,比如NBirds,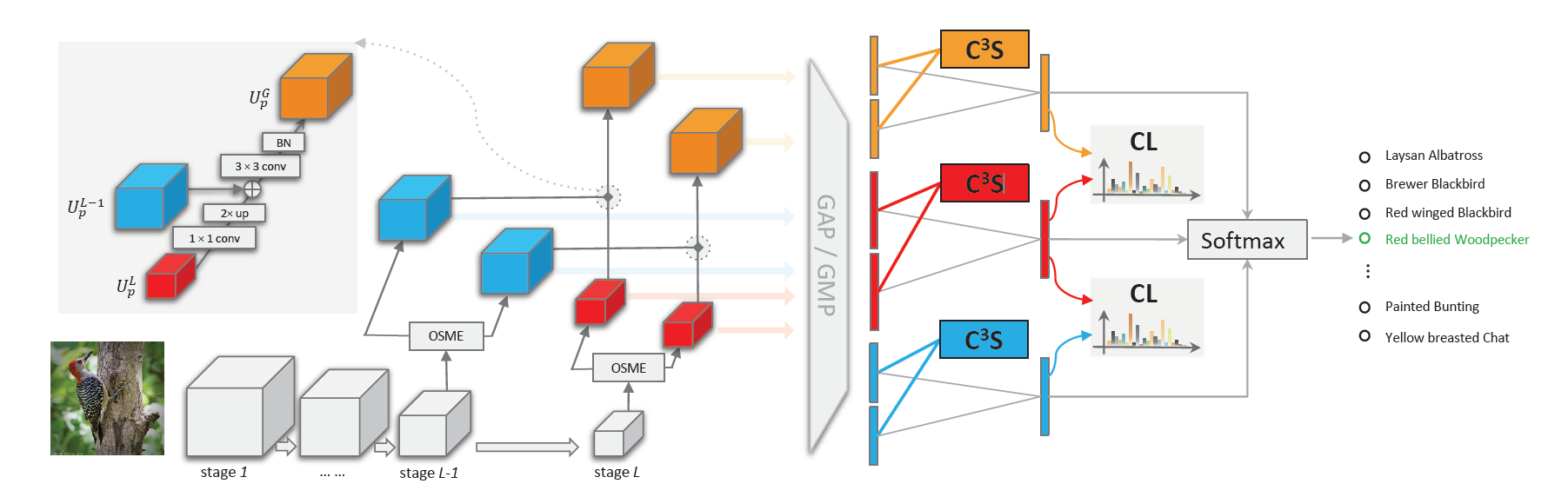
方法核心
单压缩多激励模块
首先使用单压缩多激励模块(one-squeeze multi-excitation block,OSME)对每张输入的特征图学习多注意力区域特征,通过全局平均池化层来压缩输入,获得最重要的注意力特征。尽管可以学习到注意力特征,不过想要给这些特征赋予语义含义十分有挑战性,虽然可以通过优化度量损失来解决这个问题,不过这些损失也会倾向于将不同激励模块的特征相互拉近,降低不同模块之间的区分度,失去了选择重要样本的作用。
跨类别跨语义正则化器
为了解决难以优化损失的问题,作者尝试使用跨图像跨模块的信息来学习不同语义特征,理想情况下,同一个激励模块应当有着相同的语义,不同的模块拥有不同的语义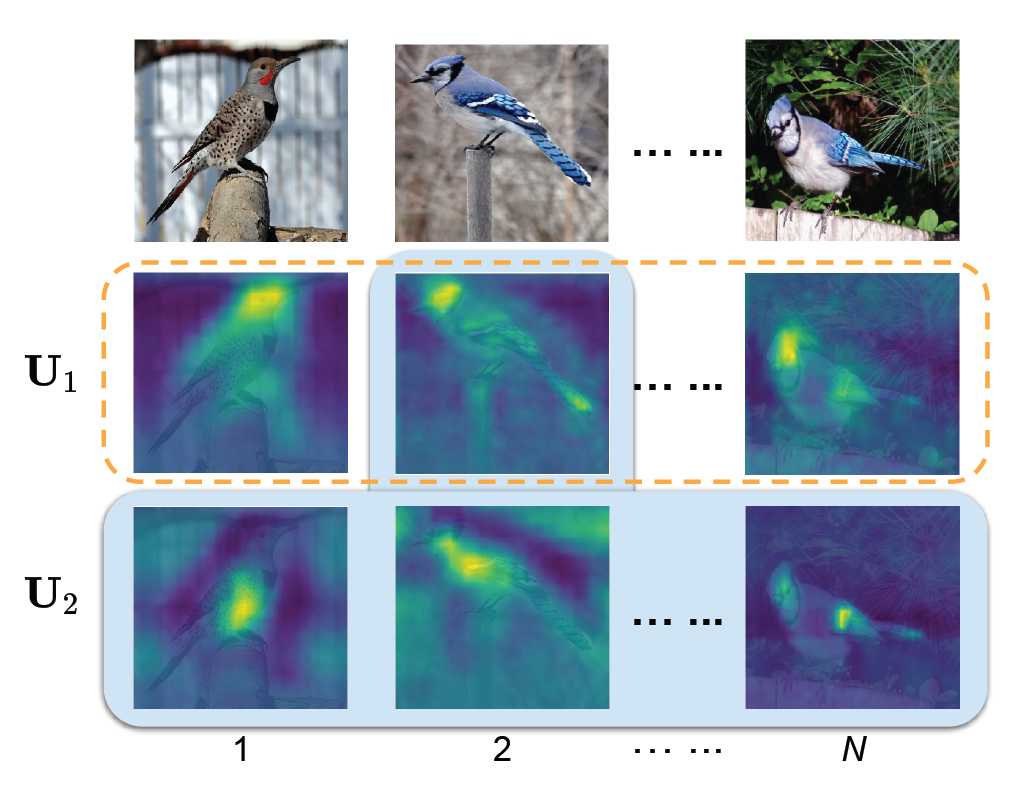
首先对OSME提取出的特征进行全局平均池化,然后进行向量长度标准化,对所有激励模块生成自身关于其他图片特征的矩阵,其中的尺寸为(C,N),N是一个批量里图像的数量,将其转置后和自身相乘,相乘后尺寸为(N,N)这样融合不同图片的特征信息。对角线表示不同图像相同部件的特征相关度,非对角线的点表示不同部件相关度
比如S[0,0]表示A图1号部件×A图1号部件+B图1号部件×B图1号部件+C图1号部件×C图1号部件S[0,1]表示A图1号部件×A图2号部件+B图1号部件×B图2号部件+C图1号部件×C图2号部件
然后对其应用C3S正则化损失,由最大化S对角线以最大化同一个激励模块内的相关性,惩罚S不在对角线,以最小化不同激励模块之间的相关性。表示矩阵中每个元素的平方和再开根号,表示取对角阵
该损失可以自然地集成到OSME块中,在训练时自动对生成的模块规范化。
跨层正则化器
利用卷积神经网络的不同层的语义特征已经被证明有利于很多视觉任务。其中最简单的方法就是对每一层的特征图都预测一次输出,并将预测结果组合起来,然而实验中,这样的效果很差。可能是因为以下两个原因
- 中级特征对输入的变化更敏感,而细粒度图像类内差距较大
- 各层之间的关系没有被充分利用,没有充分建立不同层特征图的联系
作者融合两个阶段的特征图时,先使用1×1卷积操作进行降维,再进行上采样,保证两个阶段特征图尺寸相同,合并之后,先使用3×3卷积进行抗锯齿操作,再应用批量规范化。
这样就同时融合了中层空间的高分辨率特征和顶层具有丰富语义的特征,为了进一步利用不同层预测之间的关系,作者使用跨层正则化器来约束各层的输出结果拥有尽可能相同的分布,通过最小化KL散度来实现
总损失函数
最后,得到优化后的后两阶段和融合的特征图之后,将其预测结果相加得到最后预测结果。同时,将交叉熵损失和上面的跨类别跨语义正则化损失和跨层正则化损失按照比例加权在一起获得总损失函数。其中,跨类别正则化器会对每一层的OSME输出的组件进行计算,第L-1、L、融合层共三项损失;跨层正则化器会对这三层计算KL散度,共两项。
实验
实验结果
在NBirds上,由于多剪裁、多尺度、多阶段优化的复杂性,大多数模型都很难再此数据集上进行训练,因为本模型比较简单,可以很好的拓展到大型数据集上。Cross-X在以ResNet50为主干的网络上,相比于ResNet50精度提高了3.2%
在鸟数据集上,只需要经过简单的设置,就达到了目前最先进的水平,无需任何专门的初始化,精度达到了87.7%
在汽车数据集上,精度超过了之前最先进水平0.7%,而且,没有和其他方法一样使用多尺度剪裁,充分证明了激励模块之间的相关性来表示语义特征的有效性和稳健性
狗数据集上发现,SENet和ResNet本身就超过了很多花里胡哨的方法,尽管他们采用了各种方法来提高性能,增加了模型复杂度,精度并不如简单的主干,Cross-X略微领先基线。
在飞机数据集上和基线相比,有2.7%的精度提升,和最先进水平相比有0.7%的提升。由于飞机数据集的差距来源于飞机结构的变化,而本架构也适用于处理类内结构变化较大的问题。
消融实验
作者发现本文参考最多的方法OSME模块的精度比基线SENet-50要差不少,说明了OSME无法很好的处理细粒度图像这类任务。加入了跨类别正则化器之后有效的规范了网络的学习,加入了中层和深层特征而没有约束会导致性能下降,在加入了跨层正则化损失后,有效的提高了中级特征的稳健性。
特征图融合的操作对精度带来系统性的提升,无论是在什么组合,加上融合特征图后,精度都大幅度提升,同时也提高了模型的稳健性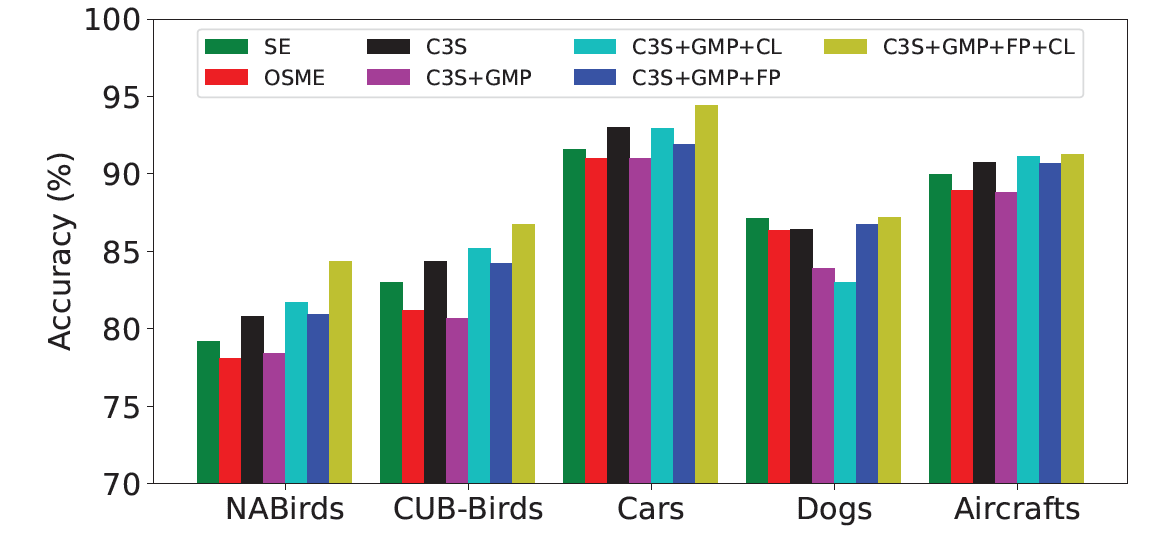
在处理OSME模块的特征时,默认使用的是全局最大汇聚层,在使用全局平均汇聚层进行实验后发现使用CL后的精度大幅度降低,可能是因为全局最大汇聚层更好的确定具有丰富精细纹理的局部和细微结构,这时使用CL对精度的提升更大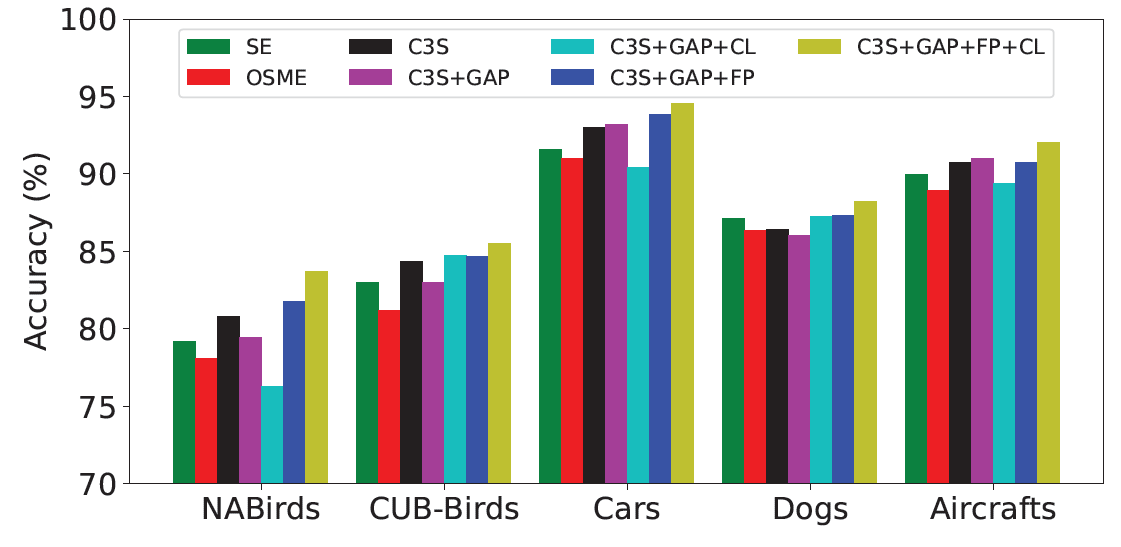
可视化
展示的激活图表示,网络很好的实现了本文提出的目标,让每个激励模块学习的部件集中在不同区域。同时融合的激活图可以看出来是增强的常规激活图,增强了常规激活图对应区域的响应强度,最后一列表示将常规和融和图相结合。
总结
本文提出了多个十分有创新点的想法,首先是针对类内差距大提出了跨类特征提取,随后将各层的特征图规范化,让他们输出相同的预测概率,最后融合了最后两阶段的特征图,这样可以以较低的计算量达到特征融合。之前的方法都没有专门针对细粒度图像的特性进行分析,不过本文主要优化的是类内差距大的问题,没有针对类间差距小进行优化,在未来的研究可以充分考虑到这点。
本文使用了KL散度来优化两阶段特征图分布,可以尝试之前新学到的推土机距离,因为他提供了从一个分布转向另一个分布的方法。而且在进行跨类别正则化时,进行了两次全局最大汇聚操作,特征大量损失。同时,部分判别性部件的类间的差距十分细微,往往就是依靠某一个部件的细微差距进行分类,而跨类别正则化器则要求他们更加靠近,可能会让其失去辨别性。

若有收获,就点个赞吧
0 人点赞
