问题动机
计算机视觉中,常用的方法是将视觉信息转换为像素矩阵,再通过卷积卷积处理,不过目前有以下挑战:
- 并非所有像素都是同等重要的
- 不是所有图像都有高级特征都有作用[1]
-
简介
为了解决以上问题,本文提出的视觉转换器(Visual Transformer,VT),使用图像的语义概念来表示表示高级特征,从而可以有效的关联和学习稀疏分布的高级特征,因为一个具有几个词的句子就足以描述一张图的高级特征。本文首先将特征图按照给定数量语义概念像素级分组成视觉标记,将这些标记提供给Transformer模块,输出的视觉标记充分融合了其他视觉标记的语义信息,再将视觉标记的重新投影到特征图中,这些标记可以用于图像级分类任务,也可以进行像素级分割任务;
本文针对卷积网络的问题,提出了以下创新点: 对重要区域分配更多计算量
- 在少量的视觉标记中加入语义概念,大幅度减少计算量
- 通过语义概念和视觉标记关联空间上遥远的特征
作者在多个数据集上进行试验,并用VT重新设计了当时最先进水平的金字塔网络,在图像分类任务上,和ResNet相比,降低了6.9倍计算量的同时提高了4.6%~7%的精度。在语义分割任务上降低了6.4倍计算量的同时将mIoU提高了0.35%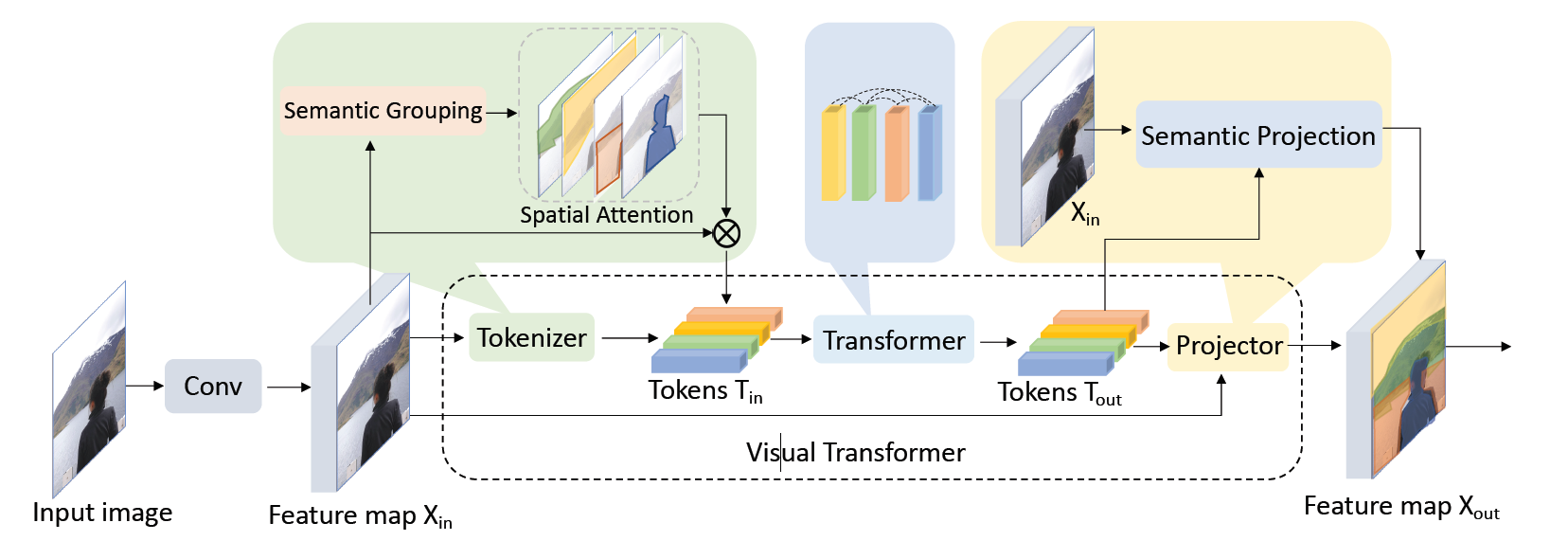
相关工作
Vision Transformer
本文也利用到了Transformer架构,不过和ViT直接利用自然语言处理架构处理图片不同的是,既然Transformer架构擅长解决语言处理问题,那就把图像问题转换为语言处理问题在进行处理,这样还能解决卷积操作冗余的问题,和ViT相比,极大程度的优化了计算量和所需数据量的问题。
可解释细粒度图像识别
本文在提取视觉标记的步骤上通过区域分组进行准确可解释的细粒度图像识别方法几乎完全相同,都是给定一个特定数量的标记/字典,让网络使用语义分割方法对像素分组,最后结合注意力信息输出高级特征。不过上文的创新之处是在上面应用先验分布,而本文是将其融合了语义信息后输出视觉标记,消除了像素卷积的冗余计算。
方法核心
网络架构
首先将像素分组成语义概念,结合注意力机制生成一组视觉标记,再使用Transformer架构融合视觉标记之间的信息。最后再将这些视觉标记投影会像素空间获得增强的特征图。和以前的方法相比,本文只需要16个语义概念就可以实现卓越的性能。在本架构上,作者充分利用了卷积和VT的优势:
- 在网络早期使用卷积神经网络提取特征
- 在网络后期使用稀疏的语义信息提取高级特征
- 在网络末端可以使用视觉标记进行图像分类或者语义分割
视觉标记
首先在进行卷积操作,在生成的特征图上进行逐点卷积,将每个像素映射到L个语义分组中,在每个组内,使用汇聚层融合空间信息,获得标记T。再使用softmax层将标记信息转换为注意力图,最后计算注意力图和原输入的加权平均值,得到L个视觉标记。
为了解决直接使用语义概念分组导致的不准确性,本文将提取视觉标记的操作重复若干次,使用上次提取出的语义标记来指导下一层提取,由此来增加输出视觉标记分割的准确度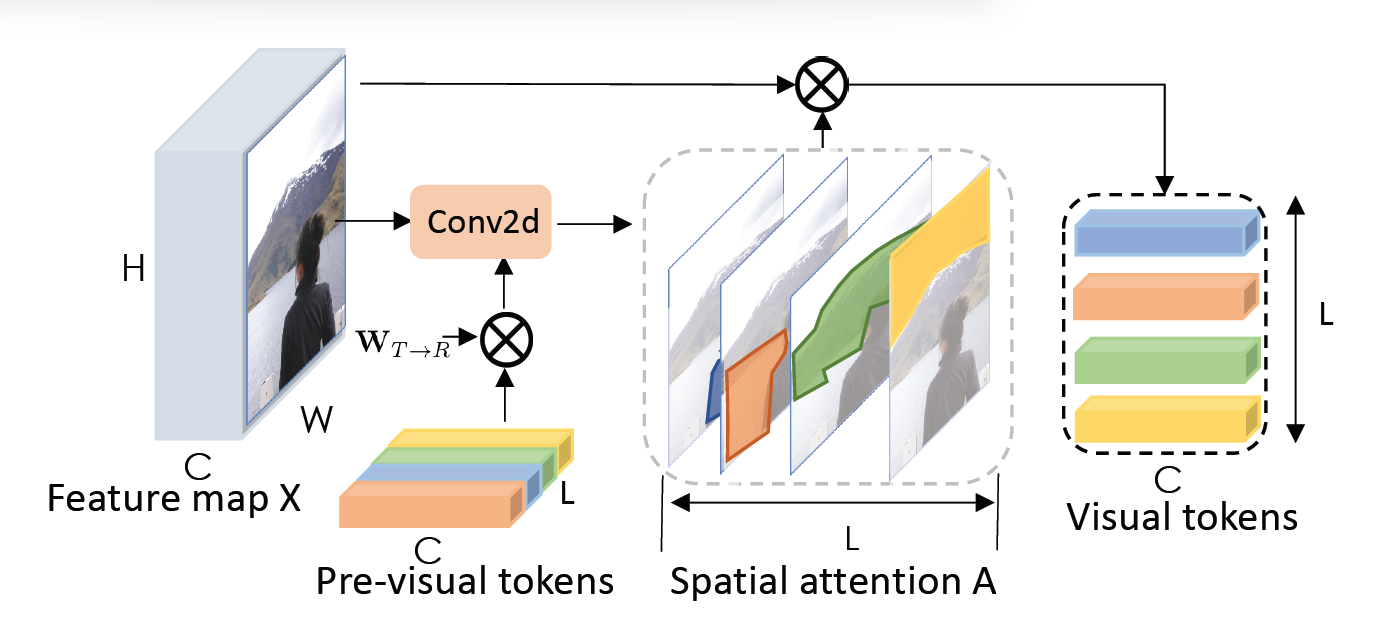
Transformer
提取出标记后,由于每个标记都代表着一个特定的概念,如果使用图像卷积操作,生成的多个特成图往往代表多个特征,这造成了浪费,于是本文使用了Transformer,Transformer的输入输出尺寸相同,十分适合具有可变含义的语义标记。空间投影
由于各种视觉任务需要像素级分割,所以需要将视觉标记重新投影到特征图中。先将输入作为查询输入Transformer计算注意力,在和视觉标记相乘,最后链接残差得到输出特征图。
完整架构
对于图像分类任务,作者使用ResNet作为主干网络,使用ViT模型替换ResNet的最后一个阶段,把其中的基本块、瓶颈块全部替换成相同数量的VT模块
对于语义分割任务,作者使用VT替换全景特征金字塔中的卷积操作,并且将新模型命名为VT-FPN,在各个分辨率的特征图中,VT-FPN使用8个视觉标记。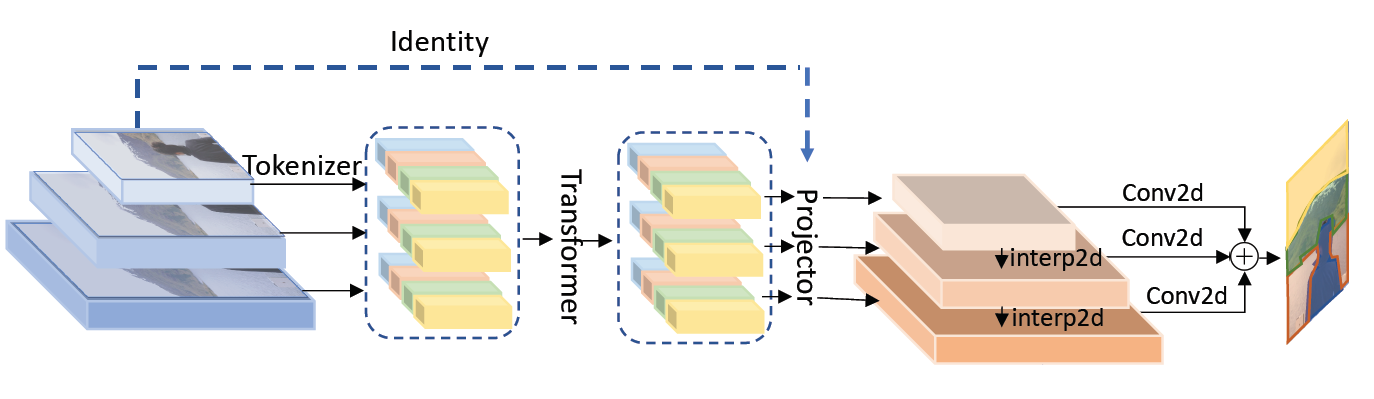
实验
图像分类
在替换了ResNet最后阶段的卷积之后,计算量需求少的多,同时验证精度相比于原架构提升了2.2%,证明了VT模块的有效性,不过训练精度提高了7.9%,说明出现了严重的过拟合现象,这说明VT的模型容量比较大,需要更强的正则化或者更复杂的任务
在更大容量的数据集上和使用更复杂的网络架构为主干后,本文提出的VT-ResNet超过了所有相同规模的其他架构,包括基于注意力的架构,并显著高于基线ResNet。这进一步验证了VT-ResNet拥有更大的模型容量,同时使用的计算量大幅度减少。
语义分割
对于COCO数据集,作者将VT模块替换金字塔架构的卷积模块,精度有着些微提高,不过计算量减少了了6.5倍。
消融实验
提取视觉标记方法
作者尝试尝试使用不同的方法对像素分组提取视觉标记,包括汇聚法、卷积法、聚类法,用卷积核聚类法表现明显优于汇聚法,说明了特征图包含冗余,需要提取像素中的语义信息来解决。作者假设了卷积法和聚类法各自的缺点,现在有待验证。卷积法检测像素分组受限于卷积核的感受野和卷积核的提取能力,聚类的方法提取了所有可能存在的语义概念,并非旨在捕获基本语义概念。
作者对循环标记提取法做了消融实验,在ResNet18和ResNet34上精度分别提高了0.8%和0.4%,这说明越大的模型提取特征的能力越强,输出的特征图已经包含了丰富的语义信息,对循环标记提取的依赖越低。
标记之间的关系
作者使用了不同方法来融合不同标记之间的关系,其中不融合的精度最低,使用图卷积操作对精度提升很小,使用Transforemer相比于不融合提高了2.2%和1.5%。这可能是因为图卷积只能将每个视觉标记绑定到一个特定的概念,而Transformer可以计算每个标记对任意语义概念进行编码,充分利用模型容量
标记数量
作者尝试了使用不同数量的视觉标记,发现精度几乎没有改变,说明VT只需要少量的视觉标记就可以概括整图的高级特征,不需要太多额外的标记
是否使用投影
在视觉理解中,像素级语义十分重要,视觉标记不包含任何空间上的信息,这对图像分类和语义分割是不利的。实验结果表明,将其投影回特诊图会带来1%左右的精度提升
可视化
作者对生成的空间注意力进行可视化,在没有任何监督的情况下,不同的视觉标记关注了不同的语义概念,对应着前景部分或者背景部分,不过和其他架构相比,本文的注意力分割并不是十分优秀
总结
本文提出了从图像中提取少量语义概念转换成视觉标记,并用来表示图像中的高级特征,这些特征可以用做图像分类和语义分割。本文提供了另一种将图像处理任务和语言处理任务相结合的新思路。也同时证明了一张图只有少量高级特征,常用的卷积操作生成的多通道确实会带来大量冗余,一定程度解释了最近卷积神经网络中瓶颈层的合理性
不过本架构之所以没有像ViT一样热门,可能还是以下方面的问题:
- 本文依然是依靠在ResNet的主干上,和其他研究并无不同,无法作为一个独立的主干架构进行训练和学习,而ViT则完全替换了ResNet的同时保证了更高的精度
- VT模块主要优化了计算时间的问题,不过问题在测试精度上和基线相比没有太大的提升,和ViT有着很大的差距,相当于是用精度换速度。
- 生成的注意力图效果和最新研究相比,还是有着不小的差距,很难定位到真正有用的部件。同时峰值相应不够明显。
不过本文在视觉标记提取出使用了循环提取的操作,以此来增加提取的准确度和稳健性,与此同时,参数量增加的很少,并通过消融实验证明了该操作的有效性,这样的操作可以应用到之后的工作中。
- 像边角、纹理这些低级特征的卷积核对所有图像分类都有帮助,而像耳朵的形状等,不会出现在汽车、花卉上,不实用的卷积核浪费大量计算 ↩︎

若有收获,就点个赞吧
0 人点赞
