简介
认知神经科学家的研究发现,人类在理解一个场景时,视觉系统会经历三个阶段,扫视激活显著区域,选择感兴趣区域,注视局部区域,最后做出判断。之前的一系列工作也使用了锚框选择部件,再专门提取特征,不过主要有以下几个问题
- 然而在图像级标签下准确得估计锚框一直是个相当复杂的问题
- 部件数量是一个预定义的超参数,不能很好适应所有的图像内容
- 剪裁操作忽略了部件周围的局部环境,限制了模型表达能力,尤其是在锚框错误的时候
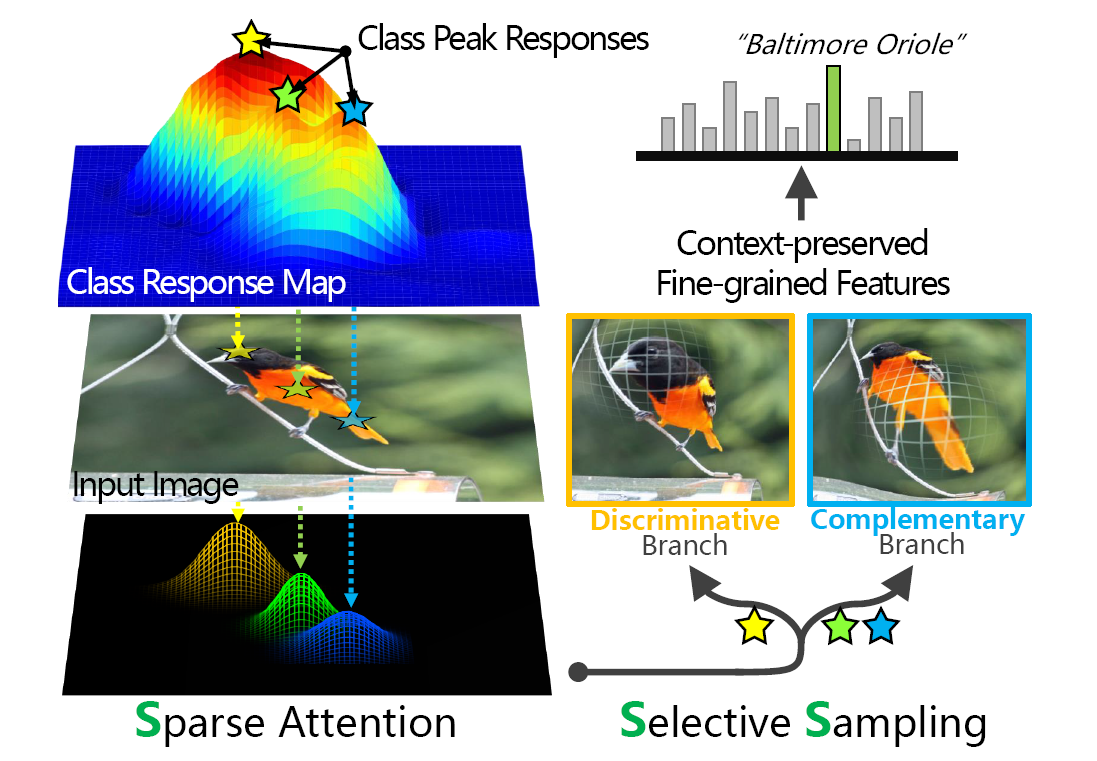
作者受到了以上研究的启发,提出了本文的选择性稀疏采样(Selective Sparse Sampling Networks,S3Ns)在只依靠图像级标签解决细粒度识别问题。
本文核心思路是模拟人类视觉生成一组基于图像内容的动态稀疏注意力,并对信息富集的区域应用非均匀放大,可以在不丢失上下文信息的情况下捕获精细的视觉特征。具体步骤如下:
- 生成注意力图,收集响应图中的局部最大值,也就是峰值区域
- 为每个估计出来的峰值生成一组稀疏注意力
- 对图片进行非均匀扭曲变换,突出学习峰值区域。
- 将峰值区域分为判别区域和互补区域,送入网络中采样
和传统方法相比,本方法不需要预先定义部件的数量,不需要额外的监督。因为峰值响应是动态的,所以框架更加灵活,甚至不需要针对不同任务调整超参数。精度和基线相比有了显著提升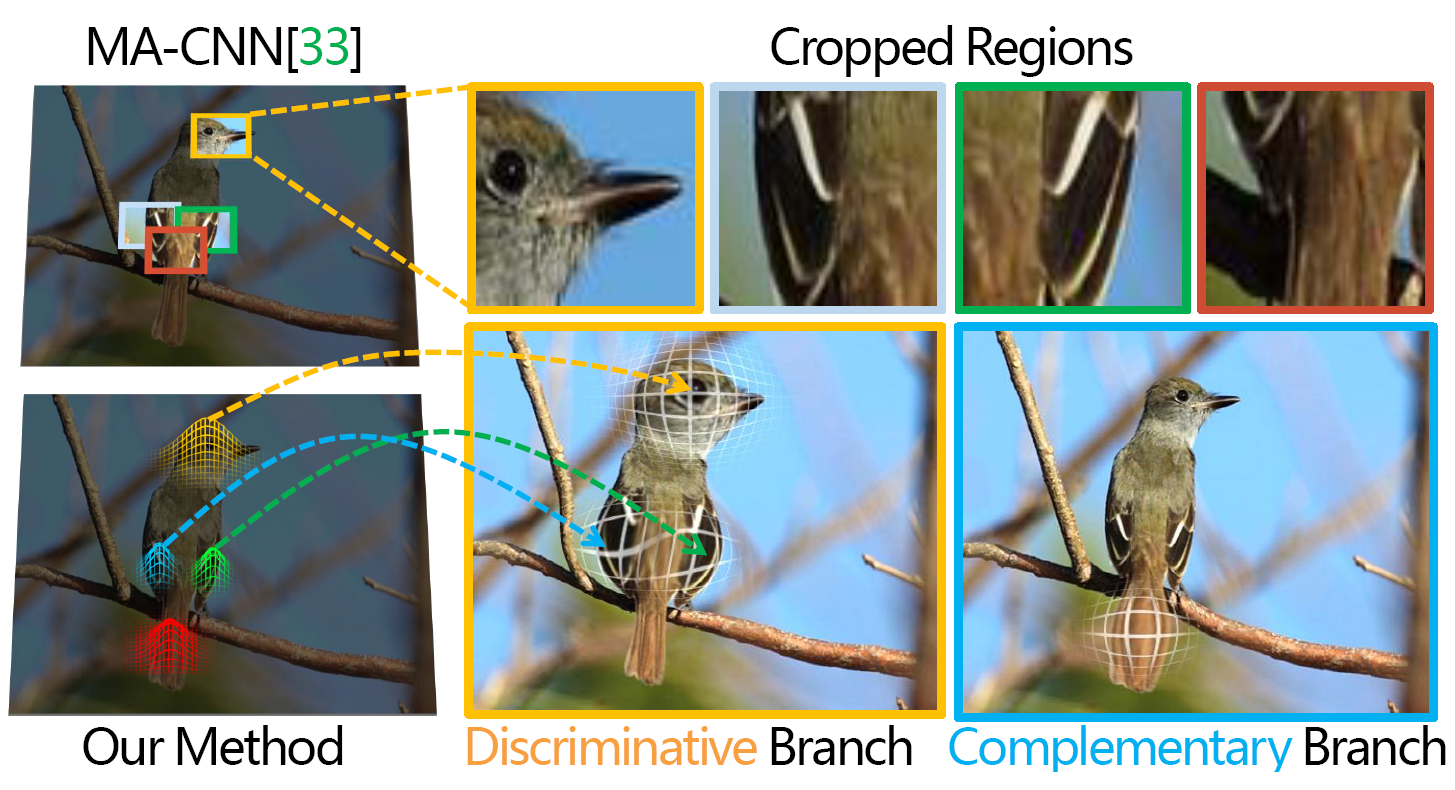
方法核心

峰值响应
给定输入图像,首先输入卷积神经网络中提取特征,得到最后一层输出的特征图,尺寸为(H,W,D),对特征图每个通道应用全局平均池化层,得到长度为D的向量,将向量输入全连接层,输出尺寸为细粒度类别数C,提取全连接层的权重矩阵 ,尺寸为
,尺寸为(D,C),将每个特征图和对应的各个类别权重相乘,对每个类别生成一个峰值响应图,尺寸为(H,W,D,C),每个类别的峰值区域是一定窗口大小内的最大值
稀疏注意力
如果只从预测概率最大的一个类别提取峰值往往覆盖不到所有特征,所以本文从预测结果前五名的响应图中提取峰值,然后对五个响应图进行min-max归一化,然后找出T个局部最大值作为峰值区域。
选择峰值时,作者使用熵确定置信度,对于置信度高的,使用Top-1峰值,对于置信度低的,汇总Top-5响应图,再查找峰值区域。
然后在生成(0,1)的随机数,将峰值区域分为两组。其中高峰值区域更有可能被划分为判别特征,低峰值区域更有可能被划分为互补特征。
最后使用高斯核计算每个峰值的稀疏注意力,最后注意力图尺寸为(T,H,W)
选择性采样
然后针对判别特征和互补特征的注意力图,分别进行图像重采样,突出重要的局部区域同时保留周围的上下文信息。在对局部进行缩放的时候,重要性较高的区域拥有统一比例的缩放,而重要性较低的区域则会被抑制,最后生成两张图,分别是判别分支图,用于突出显示重要区域以提供详细证据,另一个是互补分支图,用于挖掘更多视觉线索,展示不那么重要的区域。该方法和可以避免强大的特征主导梯度学习,并且鼓励网络学习更多样化的图像表示。
计算损失时会将两张图分类的损失相加求和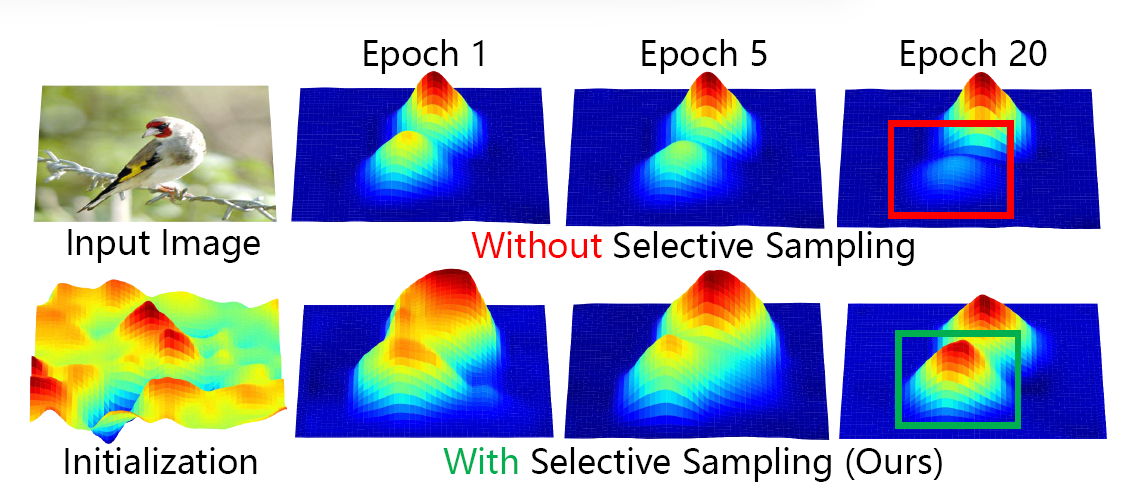
总结
直观的来解释本文的方法就是将图像上多个重要的区域放大,按重要性分组为判别图和互补图,使用两张重构的图像进行分类。这种方法符合人类视觉系统理解图像的机制,为图像识别领域提供了新的见解,同时也很符合人识别图像的直觉,这样的方法对图像精度提升的改进也是可以解释的,也很容易通过可视化判断是否得到了重要的部件
不过我认为本文的思路和解决方法并没有找到细粒度图像分类的核心点。
- 放大图像也是让其在后续卷积操作中占比更大,会被卷积核更多次的感知到,变相的相当于拥有了更高的注意力权重,既然如此那为何不直接对这些判别性和互补性部件使用更高的注意力权重呢。
- 放大峰值区域操作和锚框剪裁相比,保证背景和周边部件信息的完整性,不过放大一样挤压了周边信息,而背景区域信息也只是被挤压,没有完全排除掉。
- 对于峰值注意力判断错误的区域,分类效果反而不如不应用该机制。
- 同时因为放大采用的是非均匀放大,可能会让辨别部件形状扭曲,比如车、飞机数据集中的部件 ,导致网络误判。
总的来说,本网络还有很大的优化空间。

若有收获,就点个赞吧
0 人点赞
