问题动机
目前有研究尝试使用混合不同样本进行训练,以此来为深度模型增加训练数据,Mixup和CutMix证明了这种方法的有效性,并可以提高模型泛化能力。他们通过混合随机图像内容,并按一定比例混合它们的标签来生成新数据。不过这种方法往往会为细粒度图像识别产生不合理的样本,因为随机混合可能会破坏对象结构,从而对改进性能帮助有限。而且细粒度图像类别之间的差异主要存在于小部分区域,成比例的混合标签可能会产生噪声,因为语义信息和对应的像素的数量不成比例
简介
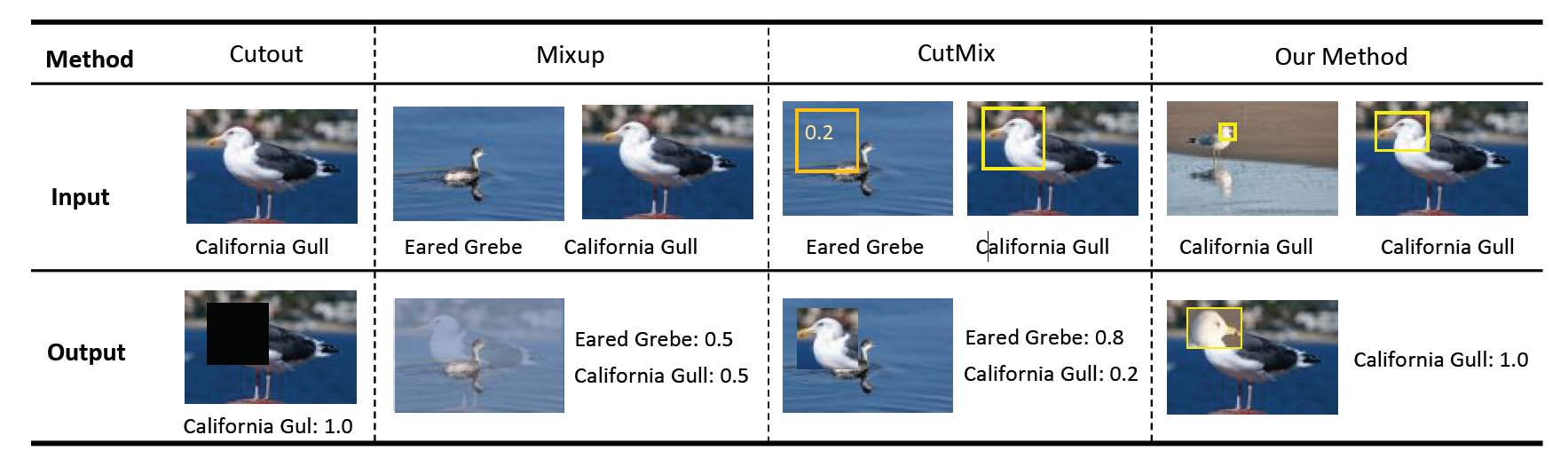
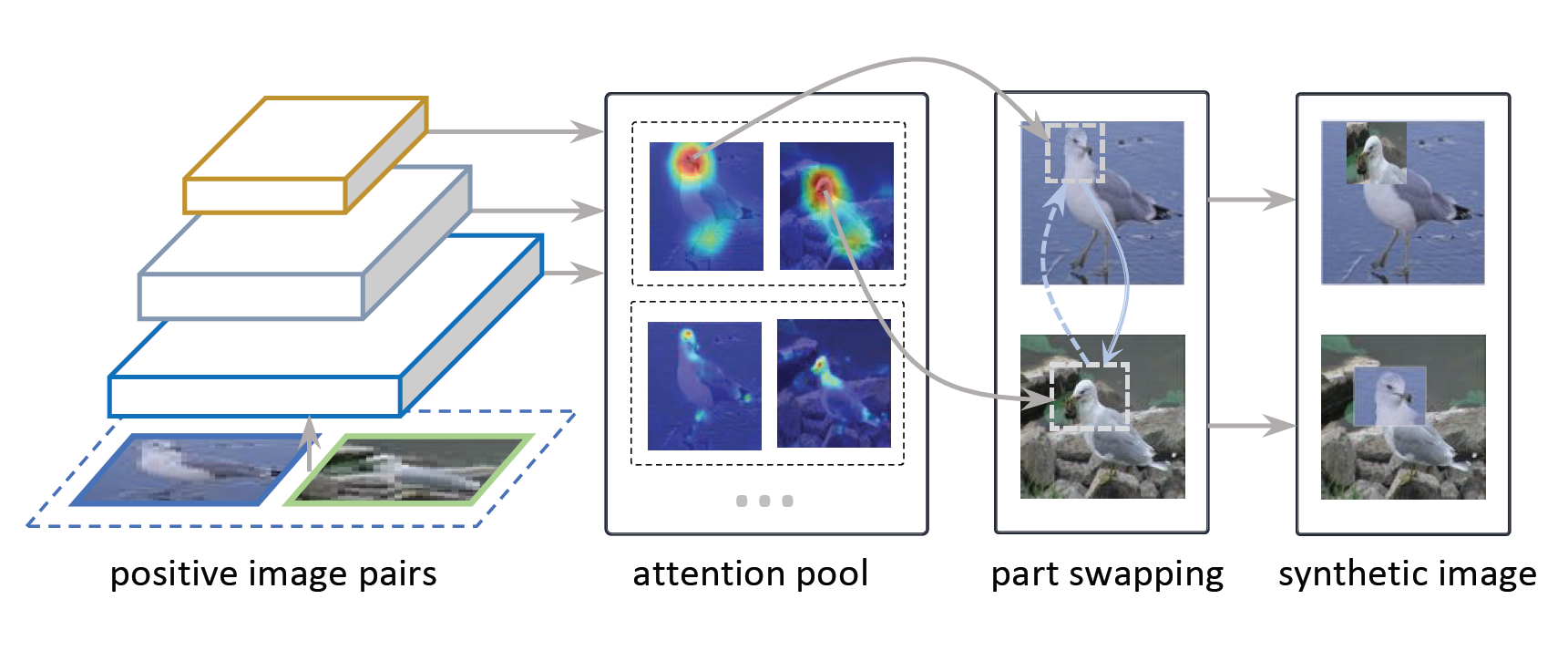
为了更合理的生成更多的训练数据,本文提出了类内部件交换(InPS),它提供过对来自同一类别的输出执行注意力引导的内容交换来产生新数据,同时对要混合的图像内容和标签施加了限制。本方法不会破坏太多的对象结构,同时避免标签噪声,有效增加了细粒度训练数据。
特征提取的管道从多个主干简化为一个主干,可以很容易地嵌入到现有的网络中,在不引入额外资源的情况下,提高模型分类和定位性能
通过实验证明了本方法在识别精度优于目前方法,实现了目前最先进性能,同时保证了预测效率。在弱监督对象定位上,也优于传统方法,表明了InPS训练神经网络对对象完整性更加敏感
方法核心
优化目标
由于主要是依靠目标的特征来识别对象,所以在空间维度上,本文依照图像的功能分为两个区域,包括关键信息的内部参与区域和外部保留区域。给定参与区域,本方法的目标是驱动网络在更多样化的上下文中理解细粒度对象。为了实现上述目标需要解决以下两个问题:
- 在给定图像级标签的情况下定义和获取确定的区域
- 将图像混合到新样本中时如何保留监督信息
注意力先验
使用注意力机制获得初始注意力图,然后使用阈值对其进行二值化
完整架构包含一个共享主干网络,这样可以从不同层生成注意力图。以两个注意力区域为例,对应有两个子网络。为了结合初始注意力图,这里提出了注意力汇聚。通过使用一个特定分布的阈值,将注意力空间扩展到一个更大的空间。训练阶段,随机采样注意力对来指导交换操作。类内部件交换
首先随机在类内找到一对图像,对其进行仿射变换(缩放和平移)合成图计算如下:
其中F是大小2×3仿射变换的增广矩阵参数化,用于协调仿射变换的像素,采样器S用于将采样变换后的剪裁区域从旧坐标转化为新坐标,其中仿射变换矩阵为,其中为缩放,为偏置
再有了之前两个子网络生成的注意力二值图之后,将各自关注区域公式化为一个矩形锚框,然后根据两个锚框的坐标获得缩放因子
对于图上的一点,变换后的坐标为
然后再使用采样器,从原图中获得每个变换后坐标的像素值,生成融合后的图像。
本文的方法是直接从注意力二值图中计算出来的,将原区域和目标区域位置对其,然后直接拼接在目标区域上,这种转换只应用在训练阶段。测试期间只是用主干网络。
InPS同时利用了类内交换和注意力信息,并使用同类信息的内部区域和外部区域组合,创造了一个更大的数据集,使得网络拟合数据集变得更加困难,在识别时可以使用不同部件进行判别,还可以充分利用上下文信息,从而提高识别能力
实验
方法对比
作者将本方法和和CutMix进行比较,在CutMix中设置在正样本中混合,精度提高了0.2%,如果进一步加入注意力信息,和高0.92%。充分证明了本方法敌对细粒度图像的有效性
弱监督定位
和其他图像融合方法进行对比,本方法在鸟类、飞机数据集上的定位精度远远高于其他方法,达到了平均值37.1%,45.0%,以5%、10%的水平领先其他方法。其中MixUp方法对定位精度会产生负面影响,导致在三个数据集上精度都不高,而CutMix比Cutout更好地利用像素,不过不相关的区域也被激活。InPS解决了这些问题,它更专注于参与区域的交换,减少背景的干扰。
同时,本方法还对阈值具有稳健性,随着IoU阈值增高,本方法的精度下降仍然比其他方法满,并实现了最佳性能。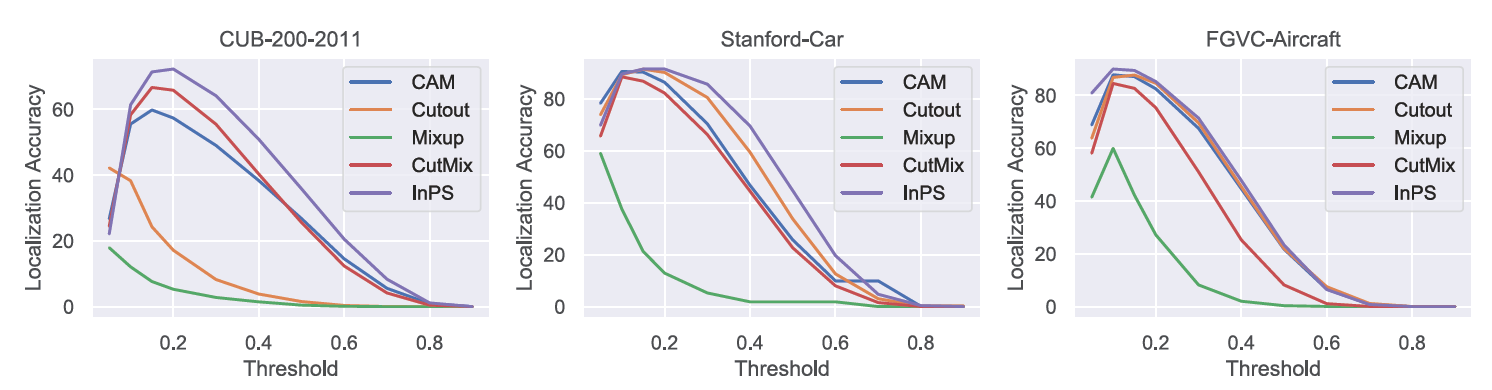
分类精度
使用Top-1分类准确率进行评估,和基线相比,有着2.8%、1.8%、2.4%的提升,表明了本方法学习了来自细粒度图像的正确特征,和最先进水平相比,本方法优于目前所有网络。
同时加深网络可以大幅度改善本方法的精度,使用ResNet-101作为主干后,分类精度进一步提高了1%
消融实验
作者使用了一个beta分布来为每个样本选取阈值的值,其中beta分布有两个超参数,对多对超参数测试后,发现时分类精度最高,这个时候beta分布退化为均匀分布
由于InPs的目的是增强现有网络,所以不会像基线网络在预测时加入更多参数。
总结
本文相当于又为细粒度图像识别开辟了另一个赛道:融合样本。本文通过注意力机制定位最重要的区域,然后将同一类别中的不同注意力区域相互调换形成新的样本,增加网络拟合的难度,从而提高网络的性能,还可以用来解决数据集长尾分布,部分类别样本过少的问题。
在测试TransFG时就发现了一个问题,在鸟类数据集上,100次迭代就将训练精度刷到了99%,这个时候学习率继续下降,训练精度继续提高,导致反向传播时几乎无法传播梯度、优化网络,测试精度提升很慢。使用本方法增加训练样本数,有可能大幅度缓解这类问题。
不过本文使用的是最基本的注意力方法,并使用二值化来提取注意力区域,可以考虑使用目前最新的注意力方法进行优化,其中二值化的操作和阈值的选择也有待商榷,或者使用专门的目标检测网络来提取更加准确的部件锚框,本文只捕捉了一个部件进行交换,可以尝试将在类间融合更多部件,这样可以大幅度,指数级提高训练样本的数量。在替换部件块时,使用的是硬边界叠加,这里可以尝试使用柔化操作,减少对替换区域周围的破坏。
现在的数据集一般都带部件标注信息,不少网络也使用了这些信息,结合本文的方法,可以使用这些部件信息精准的对同类图像进行融合替换,更高效的使用这些标注信息,从而达到更好的性能。

若有收获,就点个赞吧
0 人点赞
