方法动机
目前基于深度学习的深度模型在计算机视觉领域十分成功,不过结果往往都是无法解释的,比如,为什么模型将鸟识别为“黄头黑鸟”或者“微笑”。对于没有明确部件标记的情况下学习划分对象的部件本身就是一个具有挑战性的任务。
过去的模型没有考虑将先验知识加入到神经网络中,本文加入了一些简单的先验知识后,有效的提高了模型的可解释性和精度。那同时融合部件信息和先验知识,能否设计一个可解释的深度模型来学习所发现的部件对于识别结果的重要性呢?
相关工作
可视化深度网络
深度网络一直像一个黑匣子,我们无法理解具体哪些特征被应用到了最终分类结果上。一些研究者尝试用可视化的方法理解深度网络,开发专门提取卷积核和特征图的工具。还有一些工作尝试输出网络的判别区域。还有人提出了一个量化标准,将神经元和人工注释的掩码进行比较。
另一个方向是训练一个非常简单的线性分类器或者决策树这样的方法,模仿训练行为来给出解释。本文中,作者也是用人工标注的部件来量化网络的可解释性
可解释的深度模型
可解释性可以通过深度模型来构建。比如一些研究者提出了一种正则化方法,促使高层卷积层中的卷积核专注于提取特定的特征。也有尝试将小图像块作为输入的网络,然后再将整体输入,运用小图像块来进行预测。最相关的工作提议学习网络对象部件的原型,模型的决定取决于对原型的识别。不过本文有两个区别,一是本文使用部件来提供图像类别的解释,二是模型学习通过对象部件出现的先验知识进行正则化。
弱监督分割
本文的工作和之前的对象部件的弱监督或无监督语义分割有关系。有研究从预训练的CNN提取对象部件,但是这需要使用部件注释的标注进行监督。也有尝试对预训练CNN进行非负矩阵分解。也有将模型结合了强先验,例如空间一致性、旋转不变性、语义一致性和显著性等,用于对象部件的无监督学习,作者从中受到了启发,尝试在弱标注下进行部件分割。
Wasserstein距离
Wasserstein距离用来衡量两个分布之间的差异,也称作推土机距离(Earth Mover’s distance)。如果把他的推导过程用很形象的挖土填土来解释,EMD则是将一个土堆转换为以另一个土堆所需的最小工作量。对于连续分布函数,则是在两个分布之间所有可能的联合分布里找出期望值的最小值。
相比于之前常用的KL散度和JS散度,Wasserstein距离有以下好处
- 能够很自然的度量离散分布之间和连续分布之间的距离
- 能够给出如何把一个分布转变为另一个分布的方法
- 在转换分布的同时,能够保持分布自身的几何形态特征
简介
本文提出了一个用于细粒度识别的可解释的深度模型,只使用图像级标签,可以像素级分割出对识别做出贡献的部件,同时判别他们对识别结果的重要性。
本文的创新地使用了关于对象部件的简单先验知识:对于给定的图像,部件的出现遵循Beta分布[1],比如鸟的头部出现在大多数鸟类图像中。同时,这个简单的先验知识与本文提出的基于区域的部件寻找机制相结合,就可以识别出有意义的部件,同时保证深度模型的可解释性和精度。
具体来说,本模型预先定义部件的字典数,再通过学习得到对象部件的字典,将像素特征和字典中的部件比较,把像素分组为部件。在得到部件后,对所有其强制应用先验Beta分布,再附加本文提出的正则化项。对得到的部件提取特征,融合部件分割结果与特征得到注意力图,再通过注意力图和特征输出最终分类。测试时,本模型联合输出对象部件的分割和部件的重要性进行预测。
作者在多个数据集上进行实验,本架构可以准确定位判别力部件和其重要性,分类精度略低于目前最先进水平,但是部件的分割精度超过目前所有模型
方法核心
本文架构的核心是使用图像级的标签,让模型学习将像素分组成为有意义的区域,并根据这些区域进行细粒度分类。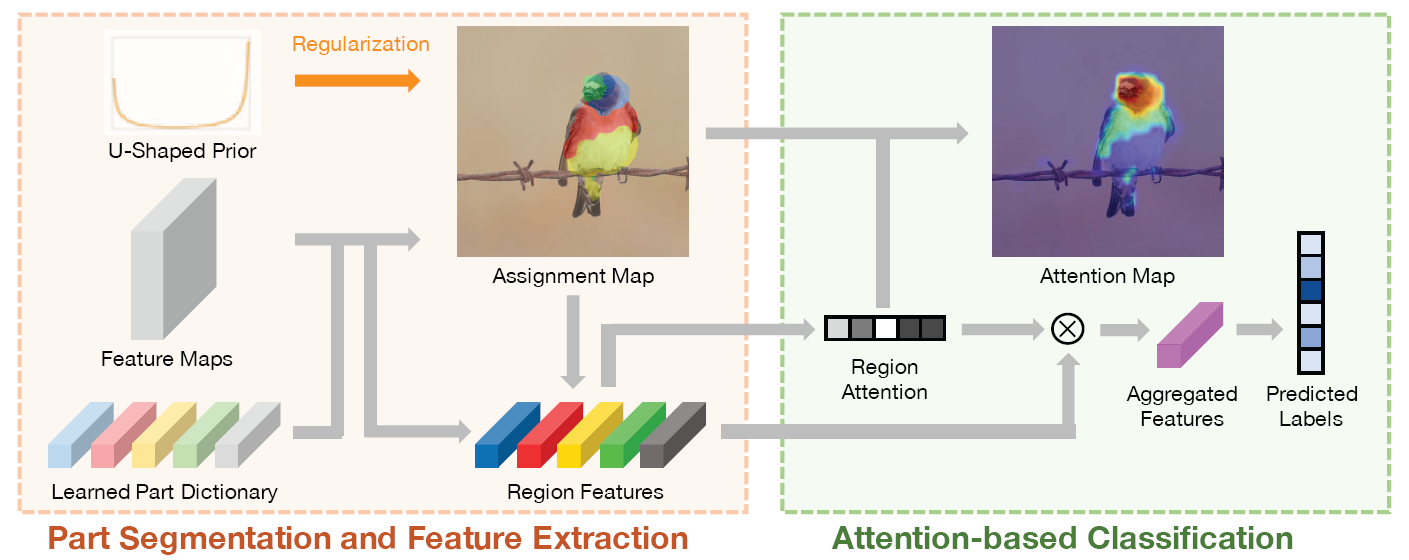
参数定义
本模型的目标是是学习一个部件字典D和一个决策函数,具体来说,字典为K个部件定义一个向量,使用获得的部件来输出预测结果,预测函数分为三部分
- 部件分割图
Q(K×H×W),用于表示每个像素,对于D中K个部件的概率 - 区域特征提取
Z(X,Q,D),根据部件字典输入图像和部件分割图来提取部件图,同时计算注意力分数,通过注意力分数来各个部件分割的重要性 - 基于注意力的分类,使用区域特征和区域注意力的加权来输出最后的分类结果
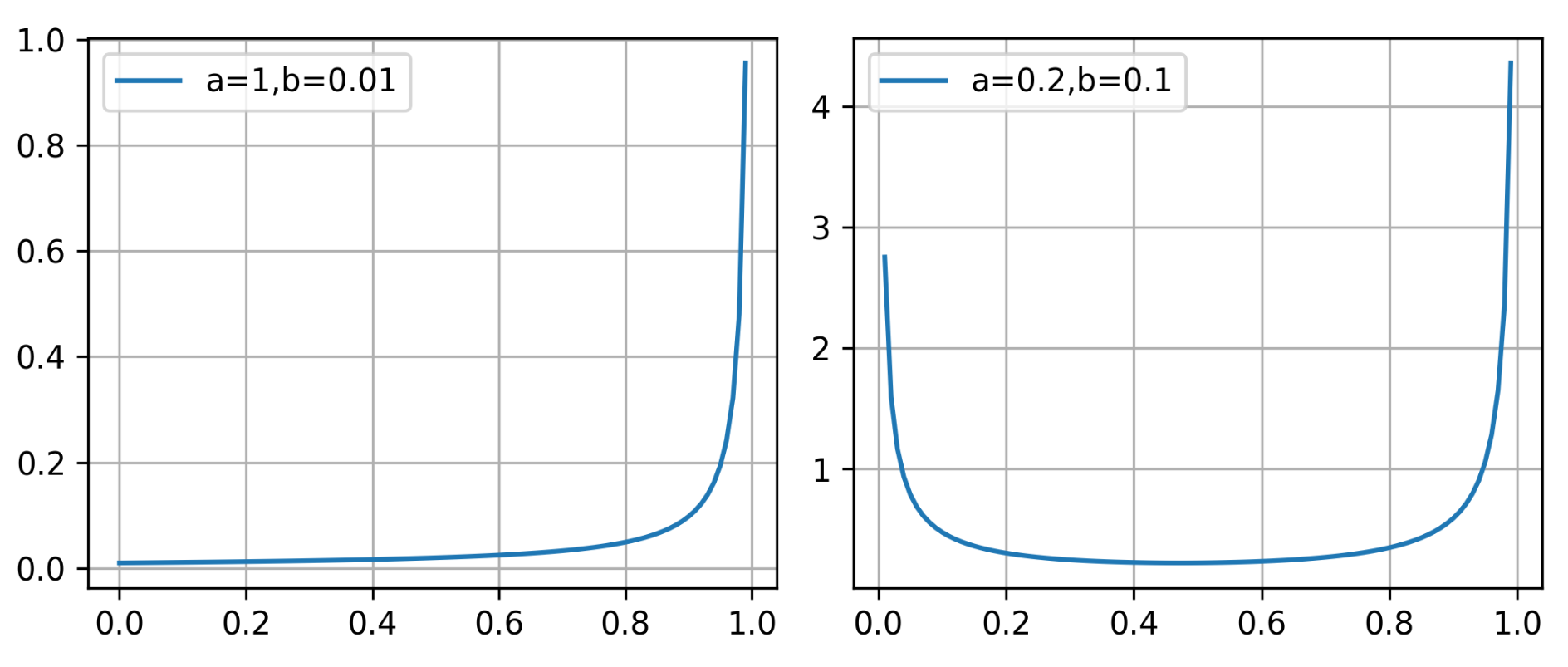
- 正则化部件,本文让每个部件的出现强制执行先验分布,用来表示开关,比如说,U型Beta分布出现概率是0-0.2和0.8-1的概率密度会很大,其他的概率密度较小
部件分割和正则化
部件分割
对于每张输入特征图的每个像素使用逐点卷积的操作,对应每个部件生成一个权重,将对所有权重输入SoftMax函数,得到每个像素对于每个部件的概率图Q
确定部件
有了部件概率图之后,对其使用最大池化操作来确定部件是否存在,为每个部件概率图生成一个值$T_k∈(0,1) $,然而本文发现,在执行最大汇聚之前,应用一个高斯平滑可以帮助消除特征图上的异常值,提高准确率。获得部件之后将所有输出结果连接成一个矩阵。
正则化部件
本文的主要思想是正则化每个挑选出来的部件,这需要部件的出现的经验分布和事先定义的先验分布对齐,对于每个小批量中出现部件的部件向量来估计经验分布,再使用Wasserstein距离和先验分布进行对齐,其中F是分布函数
为了防止在训练时的梯度消失,使用对数函数重新缩放可以提高训练稳定性,再使用小批量样本求和来代替积分计算减少计算量,实际计算公式如下
本式依次计算每个部件和先验分布的差距,这样即使部件远离所有特征向量,即如果分割图Q的对应层中所有数值均很小,经过梯度缩放,仍然可以接受非零梯度。
特征提取
在有了划分好的像素级部件之后,下一步就是汇聚每个区域的特征,将每个概率图求和取平均,将所有部件组合到一起,获得了区域特征集Z,将这个特征集输入具有多个残差网络单元的子网络,输出时通过3个1×1卷积核的瓶颈层,再进行批量规范化和激活函数,获得提取出特征。
将提取到的特征输入到一个可以计算注意力的子网络,该网络具有多个1×1卷积层,也应用了批量规范化和激活函数,通过SoftMax层输出各个部件重要性的注意力a,长度为K。再和部件概率图Q相乘,得到注意力图A
基于注意力的分类
最后输出分类时,就是将提取出的特征×注意力,通过softmax层输出分类。为了方便计算,会将注意力图、特征图的长宽展平
实验
实现细节
- 损失函数,本模型是通过最小化交叉熵损失和实际部件分布和先验分布的差异1维Wasserstein距离来优化训练,同时让实际分布匹配先验Beta分布
- 网络架构,本文将测试基线ResNet101的最后一个卷积阶段替换为本文的架构,并小幅度修改了参数
训练和推理,本文使用的是小批量随机梯度下降优化算法,学习率调度使用固定步长衰减
评估标准
作者在小中大数据集上分别评判了本架构的性能,小数据集为CUB-200,中数据集是用于分辨人脸表情的CelebA,大数据集是包含了5000个五种的iNaturalist2017。
作者对人脸和鸟数据集计算预测框和测试集的实际框的平均L2距离,对iNaturalist2017计算注意力图峰值位置位于真实边界框之外的情况CelebA结果
作者在本文使用的先验Beta分布α=1,β=0.001,各个部件出现的概率几乎为1,设置了9个部件字典
精度上,作者的方法和主干网络ResNet101相比,精度完全一样,比目前最先进水平相差1.5%,不过这些模型都使用了面部辅助解析的标签,而本文架构只是用了图像级分类标签就达到了和他们相近的的效果,证明了在精度方面拥有最先先进水平
在面部部件定位结果上与目前最新方法比较,作者发现本架构的定位精度明显高于目前最新的DFF和SCOPS,分别减少了6.6%和21.9%的误差,表明了本架构可以准确的定位部件区域,从而支撑模型的可解释性本模型对面部识别区域定位上达到了目前最先进水平。
通过进一步可视化,区域定位清晰的表明模型能够将人脸分割成有意义的部件区域,同时格外关注具有辨别力的区域

鸟数据集结果
先验分布和人脸数据集相同,都是默认各个部件会出现。
ResNet101主干网络精度上已经取得了最先进水平,本架构精度比ResNet稍差,和之前的模型精度相当。和DFF与SCOPS比较定位精度,本架构显著降低了定位错误,实现了11.5%的定位误差,同时注意力图准确的识别出了鸟类身体连贯的部分。并且识别重要区域拥有更高的注意力权重。
iNaturaist数据集
先验分布和之前不同,因为不是每张图都会出现对应部件,于是设计为U型先验分布
其中SSN和TASN都是用基于注意力的上采样来放大判别区域进行分类,ResNet比目前最先进水平差了不少,本架构比ResNet高了3.7%,作者尝试在分类时使用全卷积网络,使模型精度进一步提高2%,但距离最先进水平还有1.4%的差距。作者认为可以融合上采样机制进一步提高性能。在部件定位上,和目前基于ResNet的方法相比,本模型实现了最低的部件定位误差
消融实验
作者对注意力图和先验分布正则化后发现,在没有注意力图时,精度和定位准确率最高,而如果去掉了先验分布,分类精度降低了0.2%,定位精度降低了5%,使用完整模型是定位精度略低0.9%,但是缺点就是无法输出完整的模型分类区域和各像素的重要性
在iNaturaist数据集上出现了无法准确分割部件区域,甚至完全错误的注意力图,这可能是因为需要强制拟合U型Beta分布,而实际分布和真实情况有差别。总结
本文提出了的可解释模型非常具有创新型,可以在没有标注框的情况下实现像素级部件分割,同时生成能表示分类重要性的注意力图,同样也是像素级分割,大幅度增加了模型的可理解性。先定义模型出现的部件总数,再让每个部件出现的概率按照匹配先验分布的概率,从而保证部件分割的精度。
不过本架构的缺陷也非常明显,主要有以下问题:分类精度并没有很具有优势,基本上只能和基线精度持平,不过本文使用的ResNet101主干网络,如果使用目前最先进的Transformer架构,精度可能进一步提升,弥补最大的的劣势,值得进一步研究
- 先验概率的Beta分布是人为定义的,这其中包含了太多的不确定性,并且不同数据集需要不同的分布,比如在iNaturaist上就出现了分布不正确导致分割错误的情况,不知道能不能借助部件标注来生成准确的先验分布
- 部件的字典数也是事先定义的,对于一些比较简单的物种,没有这么多部件,可能会造成部件冗余,影响分割精度和最后的分类结果
- 本文没有源代码也没有提到训练所需要的时间,由于需要提取两次特征,还有三个子网络,在训练和预测的速度可能并没有优势。
本文提出的方法很新颖,解决的路径也比较明晰,可惜没有源代码,进一步研究所需的代价比较大。
- 用于描述一个事件概率的概率分布 ↩︎

若有收获,就点个赞吧
0 人点赞
