问题动机
传统卷积神经网络都是在封闭假设下训练的,即所有类别都是已知类,然而出现未知类时,网络会将其以高置信度分配给已知类。根据未知类的类别数量,新颖性检测可以分为一类或者多类。在本文中尝试了更为挑战的任务,即细粒度图像的新颖性检测,因为在野外动物保护系统中,检测外来入侵物种和未知类的物种十分重要,在自动驾驶中也需要对各类新型道路障碍进行识别。
目前的新颖性检测算法的核心是使用新颖性分数,一般通过度量和已知类的距离来计算,有研究在卷积神经网络框架内开发了在基于已知类下的概率和基于已知类特定向量的距离的方法。不过结果表明,使用软最大化输出结果的卷积神经网络分类器与新颖性检测不一致,因为类分布和距离度量是无法识别的,只能使用多组分布来与卷积神经网络参数兼容。
简介
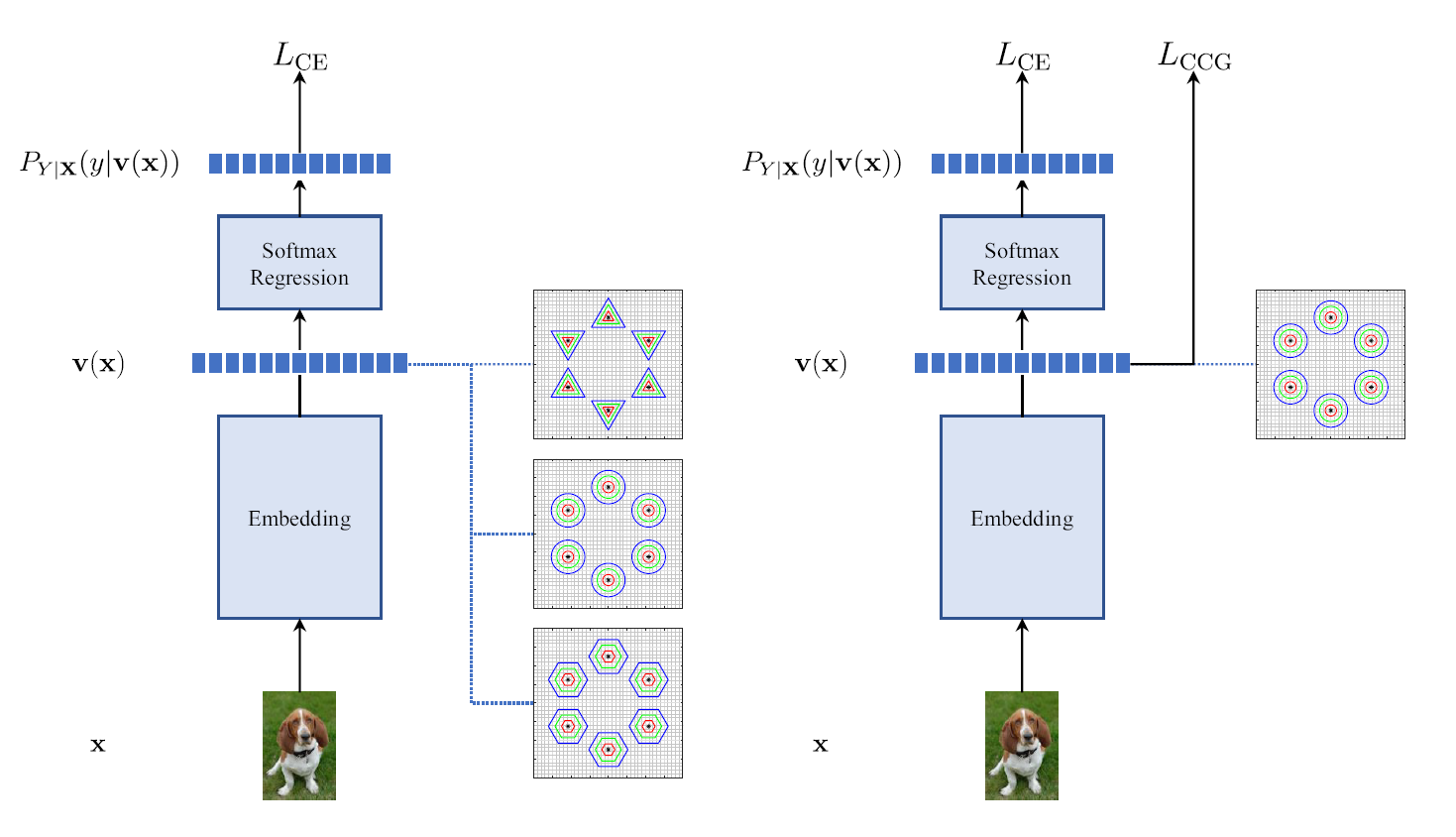
本文提出了一个新的正则化约束类条件高斯损失(CCG),利用经过分类训练的卷积神经网络,通过对特征强制执行高斯类条件分布,其几何形状遵循Bregman散度,由此可以计算和各类之间的距离,然后再进行简单的阈值处理实现新颖性检测,从而解决传统新颖性检测的无法度量的问题。
为了保证可以寻找到理想的正则化约束,本文应用了马氏距离,不过在高维向量空间中计算协方差十分困难,所以本文利用了几何方法。交叉熵损失用于对所有已知类执行最佳概率分布,属于对后验概率进行调整,而CGG损失则约束经过卷积神经网络提取的特征服从多类高斯分布,对输入的类分布进行修改,从而和新颖性检测生成的分布一致,同时这种方法并不会损失精度。
本文成功训练了新颖性检测一致分类器(NDCC),这些分类器联合优化了分类任务和新颖性检测。实验结果表明,NDCC在小型和大型数据集上都取得了最先进水平
方法核心
传统卷积神经网络
使用传统卷积神经网络分类方法进行新颖性检测,一个简单的方法就是得到各个类别的概率后,当最高概率低于一个阈值后,则认为对当前所有类都没什么信心,判断为未知类,不过这种方法基本不可靠,因为所有类概率的总和超过了1。
也可以尝试在软最大化之前进行检测,直接在特征图上进行判断,可以和已知类的分布进行建模,然后和特征图进行比较,或者从已知类中选一些代表性的特征,计算特征和特征空间的距离。每个类别的概率服从指数族分布,不过特征图对于每个类别的概率分布和定义的距离是未知的,不可识别的。
指数族分布
其中指数族分布的累计函数具有以下几个重要特性:
- 是一个凸函数
- 一阶导数等于类别的期望,二阶导数是类的协方差
- 拥有一个共轭函数
通过推导可以证明,每个卷积神经网络输出的每个指数族分布都有唯一的Bregman散度,所以无法计算和识别分布的距离
正则化约束
本文尝试在卷积神经网络训练中添加正则化约束,从而可以计算类别条件概率分布和输出特征的距离。通过实验发现,这种正则化不会影响分类器的精度,通过限制分布的自由度来似的卷积神将网络和指数族的多个分布兼容,原则上可以使用所有分布,不过高斯分布更加合理
经过直观容易的推导计算,可以通过马氏距离进行阈值处理来实现新颖性检测,之前的工作使用跨类别正则化器来约束协方差,不过这也有几个困难:
- 当维度很大时,计算协方差十分困难
- 无法确定目标协方差
-
类条件高斯损失
为了解决以上问题,本文创新型的提出了类条件高斯损失,根据引理,只需要在训练期间保证特征的均值等于每个类的协方差即可,不过如果直接对训练样本计算均值和协方差,然后最小化也比较困难,不符合小批量计算方法,通过可学习参数进行参数化,然后约束卷积神经网络特征的某一类别的均值和协方差相等。
每个类别的均值和协方差应该符合特征的分布,可以通过最小化高斯模型的负对数似然来实现。
- 保证特征整体的期望等于协方差,可以通过最小化马氏距离来实现
这种方法的正则化有两个优点,不需要指定目标协方差,只需要匹配分布,同时保证特征图每个类的分布具有相同的均值和协方差
所以类条件高斯损失就是两种约束的加权和,总损失则是交叉熵和CCG的加权和
新颖性检测分类器
一方面,交叉熵对后验分布进行调整,让他们符合最优分类结果,另一方面CCG约束输入的特征,然他们呈高斯分布,由此可以方便的计算样本到每个类的距离,从而简化新颖性检测。
首先使用训练集训练卷积神经网络,对每个类别生成权重,鼓励类条件分布是高斯分布,然后计算样本和已知类别的最小Bregman散度,然后进行阈值化来判断是否属于未知类
实验
实验设置
本文使用了两种实验设置,因为哪怕是每个类别的协方差矩阵也十分复杂,数量是通道数的平方,所以本文选择使用将对角元素的平方生成对角矩阵,另一种策略是在对角元素上加一个可学习参数后平方,实验会比较两种方法的精度
最先进水平
NDCC和目前几种方法的基线比较,其中TLN,MND具有最先进水平。评价标准是AUROC,ROC曲线的横坐标是假阳率(假正类和预测为负的比例)纵坐标是准确度(真正类在预测为正的比例),ROC下的面积就是AUC的值,AUC表示预测一个正样本的概率比预测负样本值大的可能性。
在狗、字体、鸟数据集上测试AUC,本文方法在所有数据集上都超过了目前的最先进水平,其中使用可学习参数的精度更高一些。本文使用的主干是AlexNet和VGG-16,使用VGG的精度得到了明显提升,本方法分别以6.1%/1.9%领先于使用相应主干的最先进架构
其中狗、鸟、字体在使用NDCC后提升更大,因为这三个是细粒度数据集,传统方法在细粒度数据集上无法很好的表现,因为特征更加微妙,需要更复杂的算法。其中最先进算法TLN使用了辅助数据预训练,不过NDCC仍然领先
消融实验
为了证明正则化的重要性,本文评估了直接使用最大似然估计的方法进行比较,精度下降了8%左右,证明正则化对于性能的必要性。
总结
本文提出了一种解决新颖性检测的方法,因为在无法使用软最大化输出的概率进行新颖性检测,只能使用输入前的特征检测,不过每个样本的特征图的数据分布没有规律性可言,所以无法计算和每个类别的距离,从而对估计新颖性分数造成了困难,本文使用了正则化的方法让特征服从高斯分布,并从多方面优化了计算均值和协方差的方法,在不影响对已知类分类精度的情况下提高新颖性检测的效果。在细粒度图像分类这种更具挑战的数据集上达到了相当好的水平,大幅度领先于传统方法,同时不影响已知类的分类精度。
本方法通过损失函数的约束来特征的分布不会改变分类精度,那完全可以用在其他方法上面,既然计算和各个已知类的距离,那自然也可以对其进行优化,比如对错误的类别附加损失或者将这些特征提取出来用于计算注意力。
如果针对新颖性检测任务,我认为移植到Transformer架构上可能会有不少困难,因为自注意力机制和卷积提取的特征不同,无法确定对其进行高斯分布的约束是否会影响精度,或者注意力图的定位效果。

若有收获,就点个赞吧
0 人点赞
