方法动机
细节决定成败,在细粒度图像识别中,局部信息比全局信息重要的多,不同的细粒度类别通常共享相似的全局结构,仅在某些局部细节上有所不同。具有判别力的部件特征对图像识别有着至关重要的作用,比如生物学专家可以仅依靠若干个部件就进行判断。在自然语言处理中,有方法采取了打乱句子顺序的方法,让神经网络更加专注于学习词汇的意思,强迫网络学习有意义的词汇。于是作者收到启发提出本文的方法。
简介
本文提出了一种名为解构与重构学习(DCL)的细粒度图像识别架构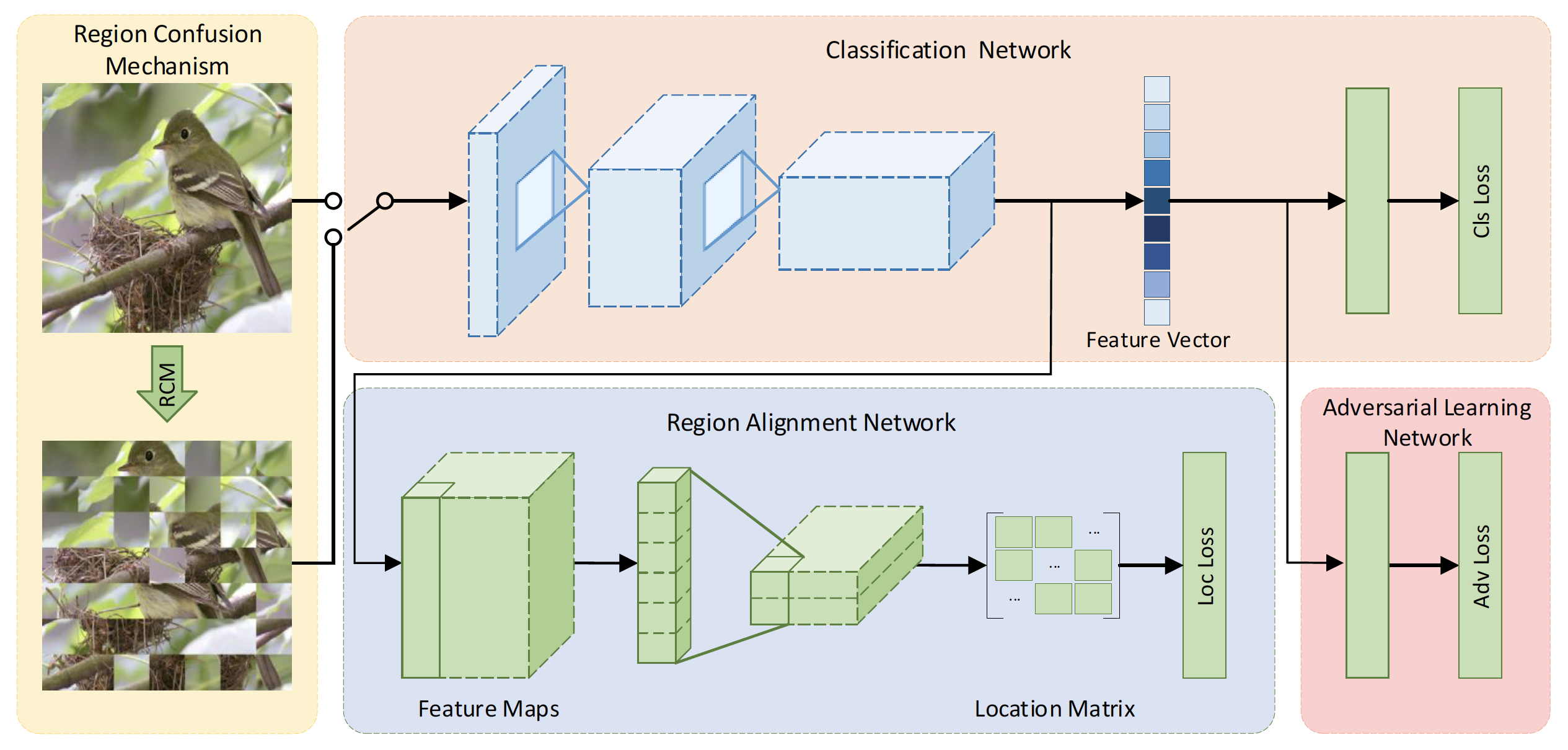
对于解构而言,作者提出了一个区域混淆机制(RCM)用来混淆全局结构,作者将整张图拆分成若干个小块,再随机的打乱,对于细粒度图像而言,局部信息相比于全局信息更加重要,所以用这种方法丢弃全局信息的同时让网络更加专注于对辨别力的局部区域进行识别,不重要的小块则会被忽略。同时这样的方法在保证可以识别的情况下,增加了识别的难度,可以提高网络的学习能力。
破坏不完全是有益的,RCM会引入大量的噪声,为了抵消负面影响,作者对其应用了对抗损失,让噪声的影响最小化,只保留有益的局部细节。
同时作者提出了重构学习,要求网络将图像恢复成原始排列顺序,并计算重构错误的损失,这样的作用和RCM相反,让网络在学习了局部信息后理解每个局域之间相关性和全局的语义信息。
这种方法在预测时不需要额外增加计算开销,训练时增加的开销几乎可以忽略不计,同时在目前的标准细粒度图像分类数据集上达到了最先进水平。
方法核心
解构学习
区域混淆机制

如图所示,作者提出了区域混淆机制(RCM)以破坏当前图像区域的空间布局。作者首先将图像划分为N×N不重叠的小区域,然后再他们的2D邻域中随机打乱,打乱的范围为,其中U是均匀分布,其中k是可调超参数,然后根据新的位置,对横向和纵向进行排序,得到每个小块新的位置。这样解构的方法破坏了原有全局空间结构,同时每个局部信心在一个可调范围内波动。
在预测计算损失函数时,会将原始图像分类结果和打乱图像分类结果相乘再和真正标签计算交叉熵损失。
对抗学习
在对图像进行破坏时,不可避免的会为图像带来混乱的视觉模式,这些噪声会影响特征的学习。为了防止模型过拟合这些噪声,于是本文提出了对抗损失。
作者使用独热编码来判断该图片是否是已经打乱过的,0代表没打乱,1代表打乱了。同时在框架中加入判别器模块,判断图像是否被破坏过,同时附加判别器的损失函数,判别器损失的目的是让判别器无法分别出那个是破坏的,哪个是不被破坏的图像,这样如果让损失达到最小的话,就可以取消破坏图像引入视觉噪声的影响
作者将该方法可视化,发现在引入对抗损失之前,有很多卷积核对由RCM引入的边缘视觉特征或不相关的特征有响应。在引入了对抗损失之后,增强了具有判别性的局部细节,并且过滤掉了不相关的特征
重构学习
考虑到解构学习时将图像的整体拆分成了复杂多样的视觉区域,于是本文提出了使用重构学习来重新建立局部之间的联系。作者提出了一个具有区域构建损失的区域对齐网络,该网络测量重构图像中的不同区域的位置精确度,引导基础网络通过端到端训练对区域间的语义相关性进行建模。
对输入的特征图进行一次只有两个通道的1×1卷积,得到输出的尺寸为2×N×N的特征图,然后将其输入到激活函数和平均汇聚层进行处理。这个二通道特征图分别对应的是预测的行和列坐标。对特征图上每个点预测一个坐标以匹配原始图像的坐标。对于原始图来说,真值和输入位置相同。然后计算区域对齐损失,损失为预测结果相对于原始坐标的L1距离
区域构建损失有主意帮助定位图像中的主要对象,并且学习各个局部区域之间的关系,通过端到端的训练,有助于让网络更加深入的理解原始图像之间区域和全局之间的关系,同时反应对象的形象和局部之间的联系。
解构与重构学习
在本文中,框架使用分类、对抗、区域对齐三种损失函数进行端到端的训练,这三种方式很好的融合和增强了局部细节,并且考虑到了对象各部件之间的相关性。总的来说,训练的目的就是最小化三种损失。破坏学习主要从判别区域中学习,构建学习根据区域之间的相关性进一步学习局部细节和全局联系。
实验
实验设置
作者在最常用的车、鸟、飞机数据集上进行了实验。主干网络选择的是ResNet-50和VGG-16,数据增强应用了随机旋转和随机水平翻转。
对于非刚体物体识别任务,比如鸟类,不同区域的相关性对于理解物体很重要,所以作者将区域对齐损失的参数设置为1,而对于缸体物体识别,比如飞机和汽车,部件之间有所区分同时互补,所以物体和部件的位置比较重要。作者将设置为0.01以突出解构学习在学习细节上的作用。
实验结果
作者提出的DCL架构在以ResNet-50的骨干上取得了三个数据集的最好成绩,同时和之前最先进水平相比,有着0.5%~1.8%的提升
消融实验
解构重构测试
作者在ResNet-50架构上分别对解构、重构、解构与重构进行单独的实验发现相对于基线都有速提升,同时应用了三种方法时,精度相比于ResNet-50分别有2.3%,1.8%,1.9%的提升。解构学习可以表明解构良好的视觉特征空间能区分特征噪声和细节特征,这有助于细粒度图像分类,而构建学习可以进一步提高模型性能。
分区粒度
作者对图像应用了不同尺度的小块,其中发现随着拆分块数的增加,精度先增加后降低,当图像拆分成7×7个小块时,在飞机数据集上表现最好,和最先进水平有0.5%的提升,但当进一步增加拆分数量时,模型变得更加难以收敛。
拆分比例
作者拆分比例默认是1:1,当图像比例变化时,分类精度都会有着较大幅度的降低,因为训练时没有有效的融合全局上下文信息。同时经过研究发现,区域混淆机制中每个小块可能偏移的位移量k设置为2时精度最高,在偏移量为2-6时,精度下降的十分缓慢,说明本文的方法对k的值并不敏感。
特征可视化
作者对最后一个卷积层的特征进行可视化,做法发现,使用了拆分之后,特征图相应区域更加集中在判别区域,通过不同的拆分方法,注意力一样可以一致的突出表现,证明了作者方法的稳健性。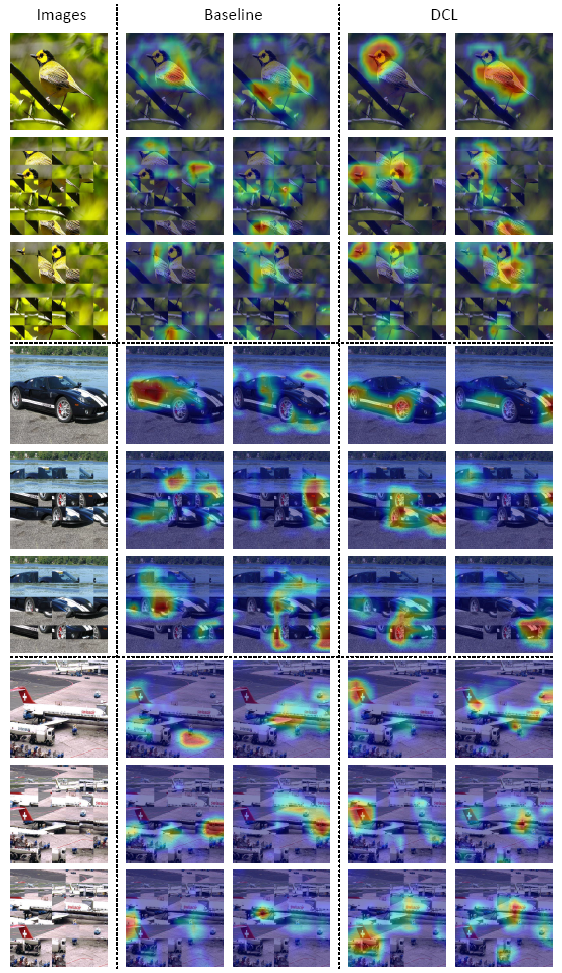
模型复杂度
在训练时只需要两个十分简单的架构,对抗学习网络和区域对齐网络来分别计算对抗损失和区域构建损失,相比于ResNet只需要增加少量的参数,占比0.034%,因此该网络的训练效率很高。在测试时只有主干网络会被激活,所以测试时不会增加任何计算量,但是精度和原本相比提升了2.3%
总结
在本文中作者提出了一种用于细粒度识别的解构与重构架构,这种架构增加了网络识别的难度以强迫网络学习更有用的部件信息。本篇文章的最大亮点还是不需要改动原本主干网络架构,并且带来的额外参数量和计算量可以忽略不计。在预测时则完全不需要增加额外的计算时间,具有很好的实用价值。
本文提出的拆分方法经过消融实验发现对拆分的块数十分敏感,但是对拆分后偏移的距离并不是十分敏感。这可能会导致在不同任务上需要进行不同的设置。而且针对不同细粒度数据集,每个判别部件的尺寸不同,这也减少了网络的泛用性。
为了防止一些小部件被拆分开来,我觉得可以对每张图进行不同尺度的拆分,将其分别训练,再将学习到的特征融合在一起,这样可以减轻将重要部件拆分的情况。同时也可以应用小块选择机制,将一些不重要的小块直接丢弃,既可以减少这些噪声带来的影响也可以突出更重要的部件。

若有收获,就点个赞吧
0 人点赞
