问题动机
深度模型的学习能力随着架构和容量不断爆炸式增长,目前模型可能需要上亿张照片才能过拟合,对数据的需求在自然语言处理任务中可以使用GPT和BERT中的自编码遮罩来解决。为了将其移植到计算机视觉领域中,有研究者进行了尝试,不过进展远远落后于自然与语言处理,主要原因有:
- 直到最近,自然语言处理与计算机视觉的架构还互不相同
- 语言和视觉信息密度不同,语言信息已经经过人类的提炼,如果丢失部分数据会几乎无法理解,而视觉信息中则有大量的冗余
自编码器的解码器将潜在信息映射回输入,在语言和视觉中,潜在信息有着不同的作用。视觉任务中,解码器重建像素的语义级别很低,而在语言任务中,解码器包含了丰富的信息
相关工作
遮罩语言建模
在BERT和GPT中是一种已经被证实的十分成功的NLP预训练方法,该方法保留一部分输入序列,让模型去预测缺失的内容,大量数据表明,这样的预训练可以很好地推广到各种下游任务中
图像遮罩方法曾经也被研究,使用卷积神经网络修复大量损失区域,基于ViT也有部分方法进行小块预测自编码学习
自编码特征学习是一种经典方法,他有一个将输入映射到潜在表示的编码器和一个重构输入的解码器,比如PCA降维和Kmeans就是经典的自动编码器,去噪自动编码器DAE破坏输入信号去重建原始未破坏的信号,一些列方法都可以被认为是不同损坏的DAE,可以试屏蔽像素或者某个颜色通道。
简介

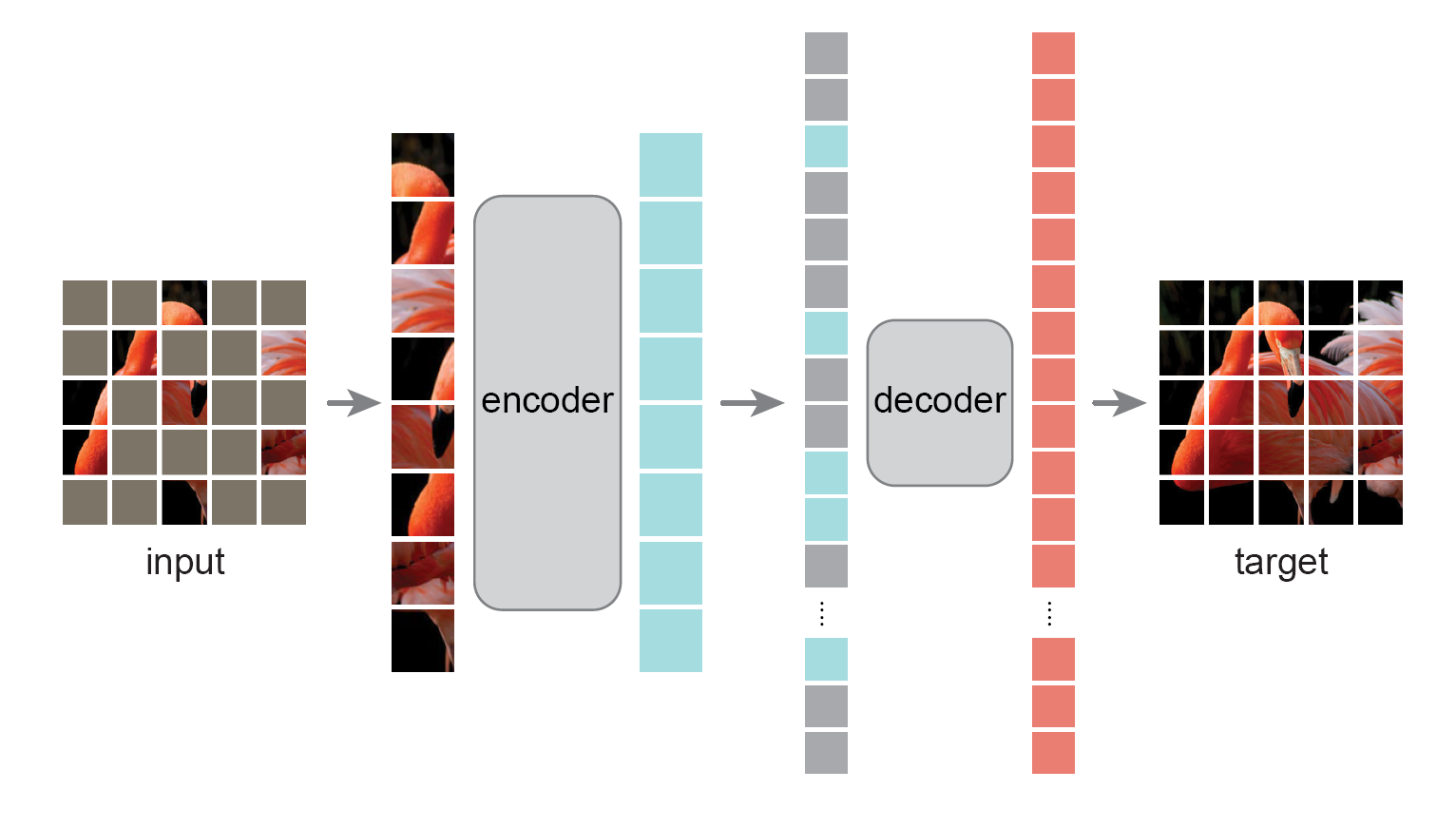
本文提出了用于计算机视觉的简单、有效、可拓展的遮罩自编码器(MAE),本文的策略很简单,对输入图像的随机小块进行屏蔽,将未被屏蔽的小块送入编码器,然后在像素空间重建缺失的小块。本架构使用的是非对称编码器-解码器结构,其中的编码器只对没被屏蔽的小块进行操作,轻量级的解码器从编码器生成的潜在信息和被遮罩小块的标记中重建原始图像。
可以将MAE用作自监督学习任务,当屏蔽了输入的75%的小块时,因为编码器只处理25%的数据,大幅度优化了自监督预训练时间,从而可以训练大型模型。
本架构可以学习非常高容量的模型,大幅度提高泛化能力,减少数据饱和,在ViT-Huge模型上实现了最高性能,自监督学习的下游任务性能优于有监督预训练。这些结果和NLP中的自监督预训练的结果一致,进一步证实了语言和视觉任务融合的可能性方法核心
遮罩
和ViT一样,将图像划分为非重叠的小块,然后对小块的子集进行遮蔽,采样的策略也很简单,按照均匀分布对随机小块进行采样,无需替换,简单来说就是随机采样。当遮罩率很高时,有以下优点:
去除了图像中的大量的冗余信息
- 生成了无法借助相邻小块推算来解决的困难的视觉任务
- 均匀分布可以有效防止潜在的中心偏差,即图像的中心区域有更多遮罩
- 高稀疏的输入图像也极大幅度的提高了编码器效率
编码器
编码器只应用于未被遮罩的小块,和ViT中一样,加入位置信息和并使用嵌入层投影,然后通过Transformer处理数据,不过这次只对整个集合的一小部分进行处理。这样就可以使用一小部分的计算量和内存来训练非常大的编码器解码器
解码器包含了完整的小块信息,其中一部分是经过编码的可见小块信息和被遮罩的小块的标记信息,每个被遮罩的小块是一个共享、可学习的向量,表示这个小块的信息需要被预测生成。对这里所有的标记嵌入位置信息。然后经过另一系列的Transformer模块。
MAE的解码器只在预测阶段才会执行图像重建任务,所以设计方式比较灵活,仅使用了非常小的解码器也可以实现优秀的效果。和编码器相比,每个标记的计算量不到10%。通过这种不对称设计可以大幅度减少计算量,所有标记只经过小型解码器,大幅度减少了预训练时间重建图像
MAE通过预测每个遮罩标记的像素值来重建输入,解码器输出中的每个元素都是表示标记像素值的向量。解码器的最后一个线性投影层的输出数就是小块中的像素数量。然后通过各个小块重建图像,损失函数只计算被遮罩的小块和原始图像的均方误差。
本文还研究了一个变体,重建的目标是每个遮罩小块的规范化像素值。具体来说,就是计算一个小块中所有像素的均值和标准差,然后用他们来规范化这个小块,实验表明,以规范化像素作为重建目标可以提高性能简单的实现
本方法实现的步骤特别简单,首先为每个小块生成一个标记,使用np.random.permutation或者np.random.shuffle方法随机打乱顺序,根据遮罩率屏蔽序列后半部分,这个过程为编码器生成一个小批量的标记,每个小块也不用进行替换,直接将为未被遮罩的小块合并成列表输入进编码器中。
得到编码器的输出后,将为被遮罩的小块添加进序列末尾,然后将小块序列重新排序后送入解码器即可。打乱和重新排序的时间开销可以忽略不计实验结果
预训练效果
本文使用ViT-Large做基线,使用ImageNet-1K做预训练,MAE使用自监督学习,ViT-Large使用监督学习预训练,然后经过线性投影得到分类精度,再通过端到端微调得到微调后精度
在经过50轮的微调之后MAE精度达到了84.9%,ViT-L有监督预训练只有76.5%,从头开始训练200轮达到了82.5%,MAE大幅度提高了预训练的效果,加快了收敛速度方法比较
自监督学习方法
和其他自监督学习方法进行比较,对于ViT-B,各个方法都比较接近,在ViT-L各个方法的差距更大,这需要模型减少过拟合。MAE可以轻松拓展,并在更大的模型中随着训练轮数增加稳定得改进。使用ViT-Huge获得了87.8%的准确率,优于其他所有自监督、监督预训练方法。监督学习方法
在最初的ViT中,预训练ImageNet-1K很快就饱和了,而MAE预训练可以很好的泛化,对于容量更高的模型,更适合重头开始训练局部微调
线性投影和微调结果在很大程度不相关,不过如果改变微调策略,只微调最后一个Transformer块,精度从73.5%改进到81%,说明最后一个Transformer块实际上是起到多层感知机头的作用。随着微调块数增多,精度迅速保持不变,说明MAE的线性可分性较差,但是具有更强的非线性特征,调整非线性头时表现更好消融实验
遮罩比例

对遮罩比例进行消融实验,最佳遮罩比是75%,超出正常认知,因为使用相同方法的BERT的遮罩率只有15%,而这个比例也远高于其他计算机视觉的相关工作的遮罩率,一般只有20%~50%
较高的遮罩率要求模型推断合理但是互不相同的输出,因为没有相邻的小块,所以无法简单地延伸线条或者纹理来完成。这可能会让网络更着重学习特征
线性投影和微调在不同遮罩率的精度曲线不同,相对来说线性投影更加平滑一些。微调在所有遮罩率下都优于使用ViT有监督预训练,充分证明了本策略的有效性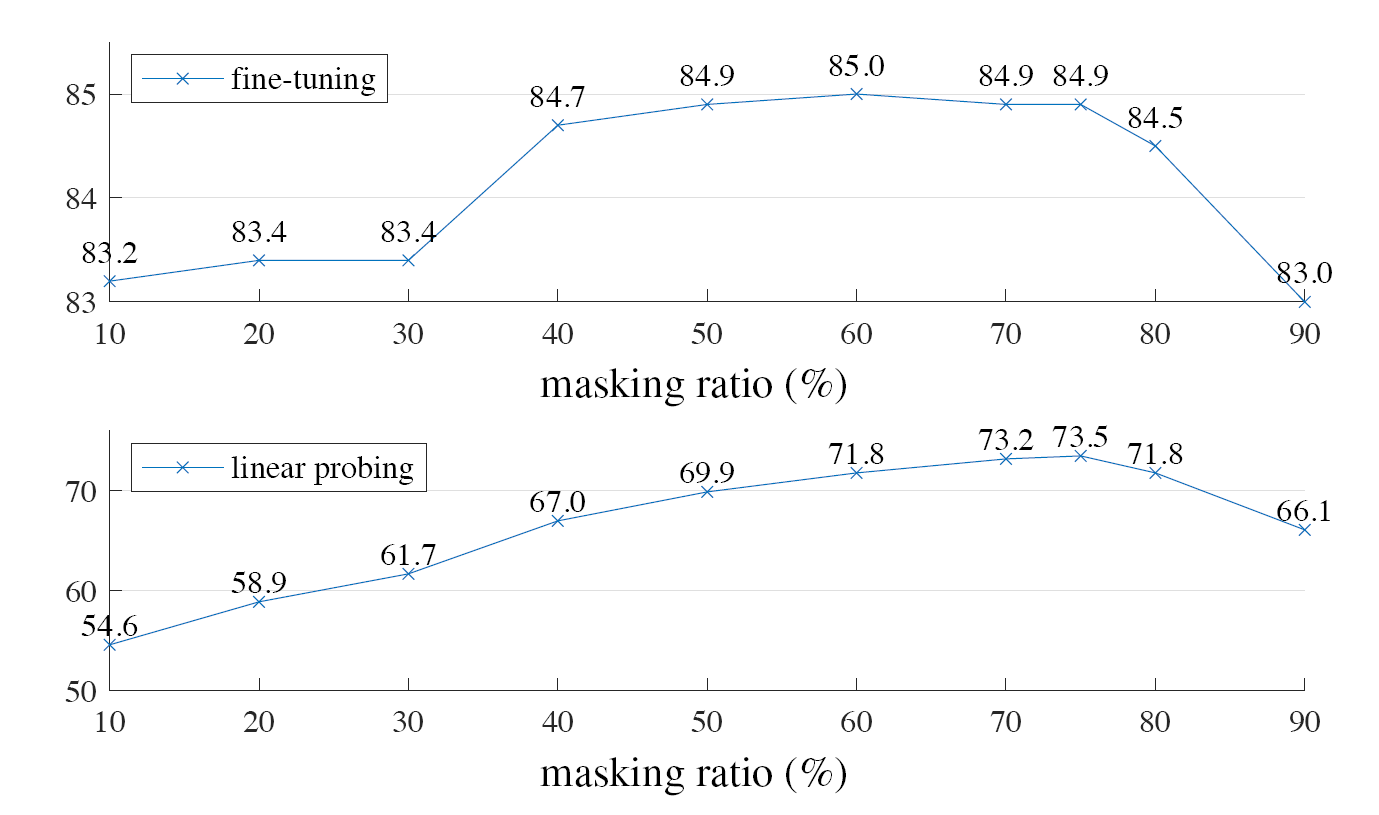
解码器设计
MAE的编码器可以灵活设计,改变解码器深度对线性投影的影响比较大,因为像素重建和图像分类任务之间有差距,自编码器后几层更专注于重建,与识别的相关性比较低,这需要更深的解码器,增加深度可以让线性投影精度提高8%,但对微调就没什么影响,单层解码器就可以达到84.8%的精度,这是解码器的最低要求,使用单层解码器可以进一步加快速度
改变解码器的通道数在微调和线性投影上表现都很好,本文使用的是512通道的解码器,总的来说参数量非常少,计算量只有ViT-L的9%遮罩标记
本文另一个设计就是跳过遮罩的小块,阶码时再恢复时使用,如果编码时保留遮罩的标记,精度会下降,线性投影下降14%。可能是因为这些标记表明了这些部分在图像中不存在,影响了学习特征。所以需要移除这些标记,只将未被遮罩的小块送入编码器。移除75%的小块后,计算速度提高了3.5~4.1倍,毕竟自注意力复杂度是,同时内存占用也大大减少数据增强
使用不同的数据增强对精度也有很大的影响,只使用剪裁增强的效果就很好,无论是固定大小剪裁还是随机大小剪裁,添加颜色抖动会降低效果。不使用数据增强MAE的效果也很好,而其他方法严重依赖数据增强遮罩采样策略
通过研究不同的遮罩采样策略,倾向于移除大块在75%的遮罩率下性能下降,训练损失更低,重建也更加模糊,均匀的网格采样,在训练损失更低,重建也更加清晰,不过未被遮罩的小块的表现质量比较低。所以还是随机采样最适合MAE,同时拥有速度和精度的优势,还可以使用更高的遮罩率
训练时间
本文发现,经过800轮训练,模型仍然没有饱和,随着训练时间的增加,准确率稳步上升,在1600轮也没有发现线性投影精度的饱和。其他模型在300轮时则会饱和。因为每次只能看到25%的数据,这使得模型可以通过更多轮看到更多的数据总结
一个架构的可拓展性对其他研究者在其他领域使用该架构十分重要,比如自编码器就是从自然语言处理迁移过来的。图像和语言是不同性质的信息,原本需要必须要谨慎处理,现在Transformer架构提供了融合两种信息的可能。之前看的文章自监督ViT的新特性也尝试像自然语言处理任务一样,挖掘ViT在自监督预训练上的潜力,本文进一步提高了自监督ViT预训练的性能,再次证明了该方向的可行性
可拓展的简单算法是深度学习的核心,比如自编码器就是从自然语言处理领域迁移过来的。同时图像和语言原本是不同性质的信息,必须要谨慎处理这些信息,而Transformer架构提供了融合两种信息的可能,同时本文的最佳遮罩率出乎常规的观点,也证明了两种信息之间还是存在不少差距,调节超参数可以在更大的范围进行实验。
本文取得了很好的结果,不过网络的整体信息是隐藏的,不可解释的,希望后续可以增强本架构的可解释性和可视化。同时在预训练时可能会产生针对预训练数据集的偏差,当遮罩率过高时,会生成原本图像中不存在的内容,值得进一步优化。本文的最佳遮罩率出乎常规的观点,也证明了两种信息之间还是存在不少差距,调节超参数可以在更大的范围进行实验。
如果针对细粒度图像分类进行优化,我觉得有必要进一步调整遮罩率,因为很可能会将图像的主体隐藏掉,不知能否生成判别性部件。或者在随机隐藏时,优先隐藏判别性部件、最重要的各个小块,让模型专注学习这些部件。

若有收获,就点个赞吧
0 人点赞
