方法动机
Transformer中自注意力操作是置换不变的,将小块视为独立相同的个体,它不能利用输入序列的顺序信息。
之前的工作将绝对位置编码添加到输入序列中的每个标记中来实现顺序感知,位置编码是可以学习的,也可以是用不同频率的正弦函数来固定的。尽管这样的方法十分有效,也不会额外增加计算量,但是这些位置编码严重损害了Transformer的灵活性。比如,编码通常和输入序列等长,在训练过程中一起更新,所以一旦训练,编码长度就固定了,在测试期间,如果序列长度比训练期间更长则会带来困难,比如在目标检测任务中,锚框的尺寸各不相同。
目前有几种常用的方法都无法很好的解决问题:
- 双三次插值扩展编码长度,会降低性能
- 固定的位置编码,降低了平移不变性
- 相对位置编码计算标记之间的距离,计算成本增加的同时精度会下降
-
简介
本文中作者提出了条件位置编码(CPE),一种全新的编码方式。它根据每个标记的局部领域动态生成位置编码,于是位置编码的尺寸根据输入长度的变化而变化;保证输入序列排列可变,可以拥有平移不变性,同时还拥有提供绝对位置信息的能力,解决了以前的痛点。经过实验,这种方式生成的编码就有根高精度,还可以通过深度学习框架轻松实现。本文还针对ViT进行了优化,提出了CPVT。
本文还提供了使用全局平均汇聚层来表示分类标签的配置,精度可以进一步提高1%,因为绝对位置编码无法带来平移不变性,而CPVT可以实现完全平移不变性。
在最先进水平DeiT上使用本文的方法,精度相比以前提高了2.7%,因为卷积操作引入的额外计算量和参数量和DeiT相比可以忽略不计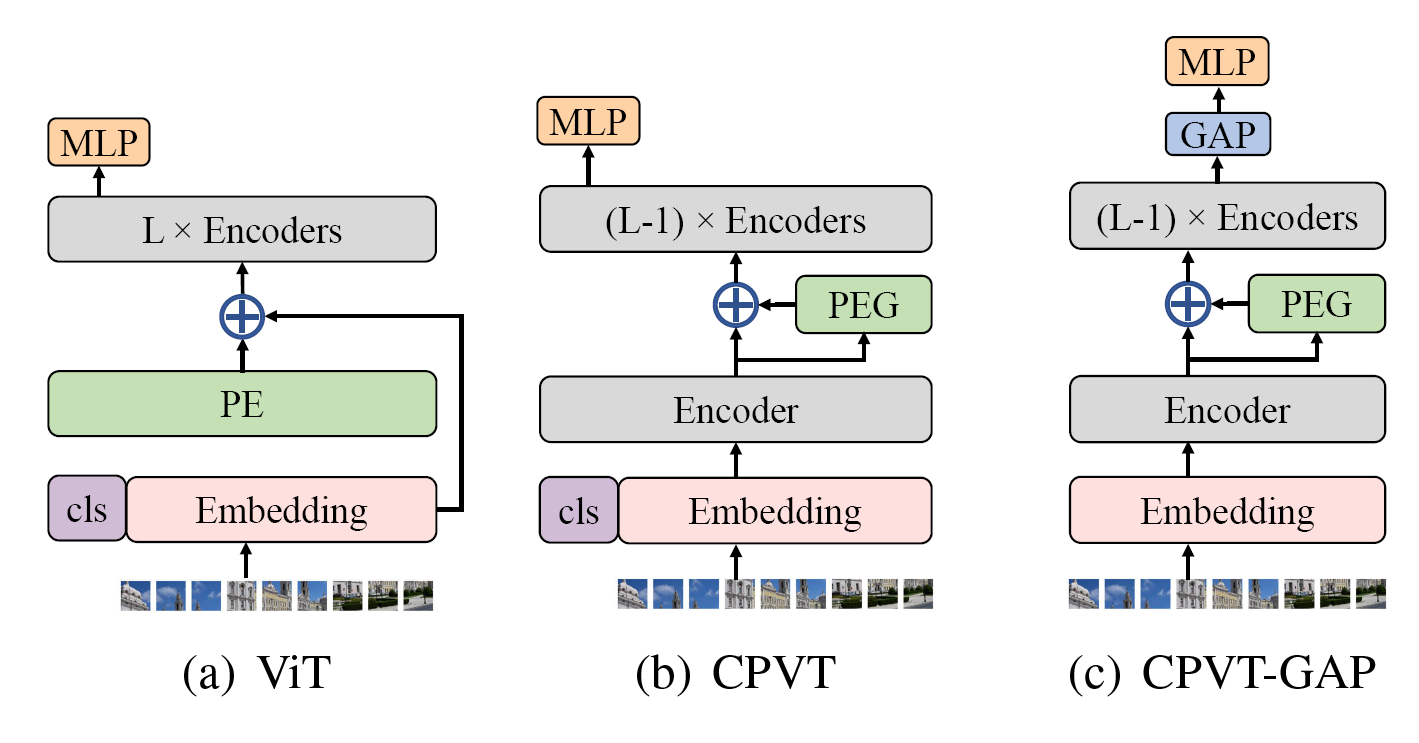
方法核心
作者认为优秀的视觉任务编码需要满足以下要求:
输入序列排列可变,但有平移不变性
- 具有归纳性并且能够处理比训练期间更长的任务
- 具有一定程度提供绝对位置的能力
本文发现,通过位置编码来表现局部关系足以满足上述所有要求。
- 序列的置换会改变局部领域顺序的改变,而输入图像的平移不会改变局部领域的顺序
- 模型很容易拓展到长序列中,因为只有标记的局部邻域受到影响
- 如果已知任何输入标记的绝对位置,可以推断出其他所有标记的绝对位置。
位置编码生成器
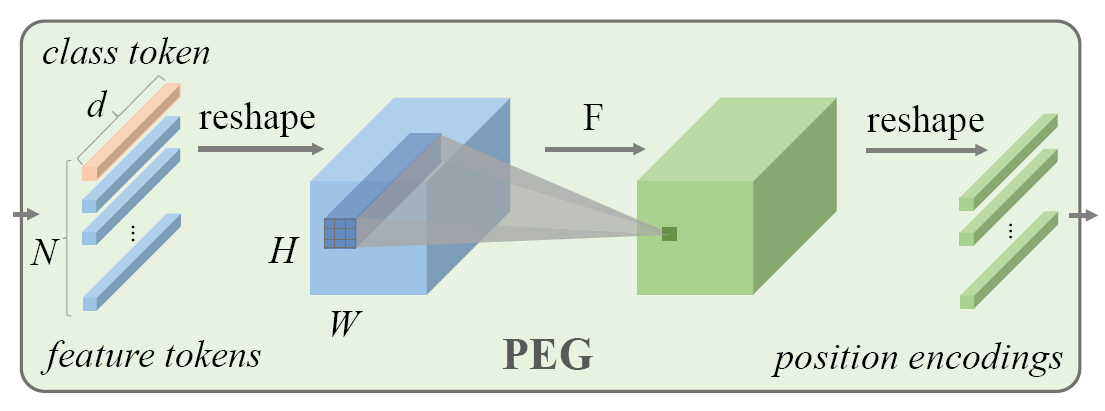
首先将经过嵌入层的小块(B,N,D)转换为(B,H,W,D),对其应用卷积操作,核大小,再加上的0填充保证输出尺寸不变,其中这一步尤为重要。其中核可以是多种操作。CPVT
考虑到ViT默认使用的是分类标记的方法,会导致多一个维度,上述方法无法处理分类标记,让其保持平移不变性。为了解决以上问题,可以采用全局平均汇聚的方法输出分类标签。针对这种方法,本文的条件编码器除了应用于标记法的CVPT版本,还有用于全局平均汇聚方法的CVPT-GAP版本,因为将标签信息融入到了小块中,所以分类标记也拥有了平移不变性,同时获得了更高的精度。总结
本文提出了一种可以用在ViT上的新的位置编码方式,因为图像中重要的小块一般都在中间,所以指示出哪些小块位于中间十分重要,但是以前的方法无法处理变长序列,本文则提出了动态编码方式,使用了卷积操作,将周边小块作为输入生成编码信息,既可以保持平移不变性,又可以保留绝对位置信息。同时,计算成本可以忽略不计。
本文的方法有效的解决条件编码的问题,之前研究的相对较少,同时对精度有了较大的改善,充分体现了ViT未来的潜力。

若有收获,就点个赞吧
0 人点赞
