简介
作者提出了一种自注意力自回归模型,主要用于图像或者视频这种高维度张量数据,解决了处理这些数据最关键的问题:
- 高维数据计算资源需求量过大
- 分布表达能力弱,无法整合各维度或者接受域小
轴向注意力保持了数据联合分布表达能力,并且使用标准的深度学习框架,需要的计算量比直接计算更小
方法
轴向注意力
该模型不改变数据张量的原始形状,一次对张量的单个轴上的所有像素执行自注意力机制,通过混合整个轴的信息,保证数据的相关性,用其他轴作为键和值。
以此法计算出的行/列注意力可以将时间复杂度减少O(N^(d-1)/d)
但是这样并没法获得完整的感受野,只能获取一列的信息.
轴向Transformer
内部解码器
为了融合行/列注意力的信息,定义了Transformer架构。以行轴向注意力举例,在嵌入位置信息前,将所有像素向右平移一个像素,相当于感受野向左平移一个像素,同时将当前像素从感受野排除。
外部解码器
首先一次处理一个通道,将通道排序按顺序堆叠在输入过程中。
对于每行,他上面的行表示了上下文信息。每一批次将像素向下平移一个像素,接受当前像素行上面所有像素,相当于感受野向上平移一个像素;加入当前行,并屏蔽当前行当前像素右侧的所有元素,相当于加入该像素左侧所有像素。
这样模型不但能捕捉当前的像素,还可以捕获当前行的像素,和常规序列模型感知范围相同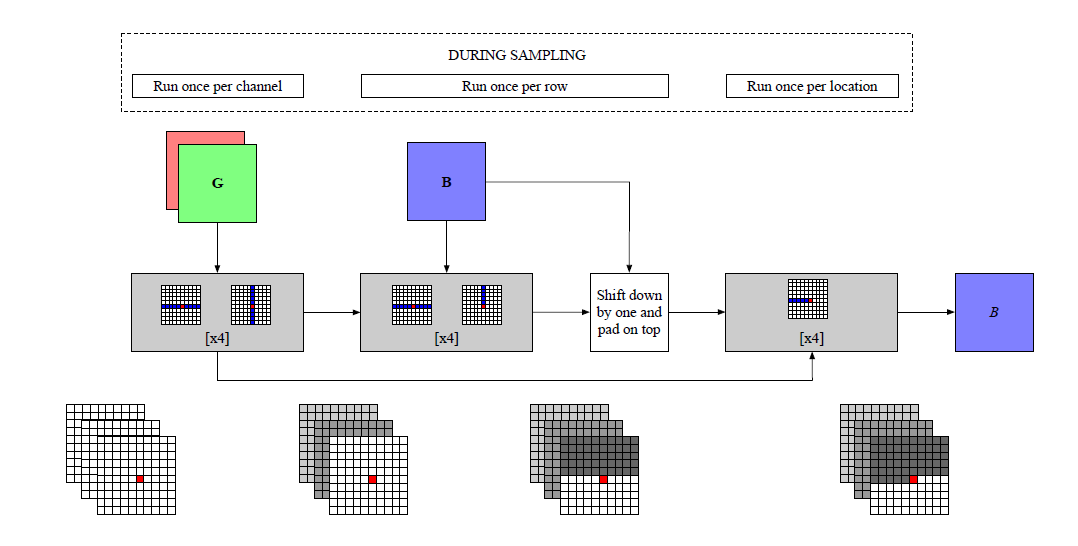
减少复杂度
如果按照上面的做法,会极大的增加时间复杂度,导致速度优势消失,不过作者想到,对于每一行上面一行的元素,已经融合过了更上面行的信息,所以只需要采样上一行,忽略其他行
通道编码器
如果想获得通道之间的融合信息,如果合并通道维度到长或者宽中,都会导致行列注意力序列太长,所以作者的做法是,随机取出一个通道,当做是单通道图像,将前面通道的信息融合到之前信息的编码块中
总结
使用轴向注意力减少时间复杂度,并不断位移保证每个像素对多维信息的完整感受野。

若有收获,就点个赞吧
0 人点赞
