简介
传统的目标检测方法往往都会根据一些初始猜测进行预测,性能往往很大程度上收到后处理步骤的影响,比如抑制锚框、锚框比例的设计、锚框的分配等等,这用到了很多其他形式的先验知识,或者在挑战性任务上无法和基线竞争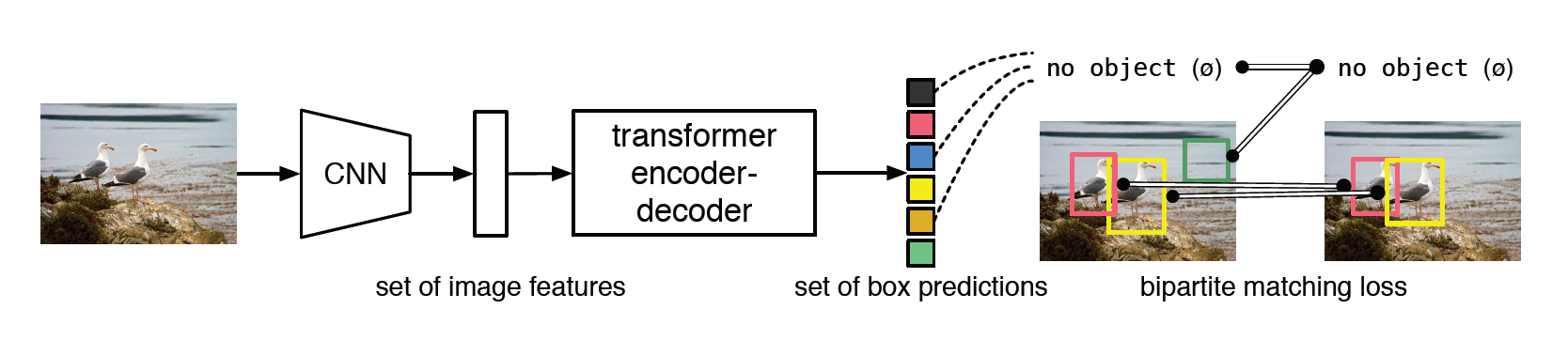
本文提出了一种将目标检测转换为为端到端预测的新方法DETR,简化了预测流程,有效消除了许多手动设计组件的要求,比如非极大值抑制和锚框生成。本方法基于集合的定义预测对象和真是对象二分匹配的全局损失,使用Transformer编码器-解码器结构进行端到端的训练。给定一组固定的学习对象,DETR推理对象和全局图像的上下文关系,并行输出最终预测集。同时新模型很简单,不需要任何自定义的层,只需要将CNN和Transformer拼接起来
在COCO数据集上精度和速度与目前完善且高度优化的Fast-RCNN基线相当,在大目标检测上远超Fast-RCNN,小目标略弱。同时可以很容易拓展到语义分割。缺点是需要超长时间的预训练
方法核心
损失函数
本文的目标是没有重复的为每个对象找出一对一匹配的锚框。DETR通过解码器推断出一组固定大小为N的预测,其中N预先定义,并且大大多余图像中的对象数量。训练的困难点是如何使用真实标签对预测标签的类别、位置、大小进行评分,本文使用匈牙利算法来计算预测标签和真实标签的配对成本。匹配的过程同时考虑了类别和位置的相似性。这样匹配的过程与现在检测其中启发式分配规则有相同的作用。找到最佳的匹配边界框后计算损失函数,损失函数定义为
在预测为空集时,一般会为边界框损失加上10左右的系数用来平衡,其中边界框损失是IoU和边界框的欧氏距离加权和
网络架构

由于本文提出的较早,没有使用ViT的小块分割,直接将特征图嵌入位置编码后展平输入到Transformer中。然后在解码器的FFN中提取出N个事先定义的锚框,包括了中心坐标和高宽,对于每个目标框都会使用softmax函数预测类标签,因为N往往会远大于图中实际对象的数量,对于没有内容的标签会标记成无
本文发现,在训练期间对解码器使用辅助损失有帮助,主要是判断每个类别正确对象的数量,因为所有FFN共享参数,所以额外使用一个层规范化来规范不同解码器的输入。
总结
本文首次使用提出了端到端的目标检测架构,不同于以往的检测方法,先预先定义锚框,再找备选锚框,再筛选的方法,本文可以直接从输入经过编码器解码器结构直接得到不重叠锚框,不需要人为的干预,也不用单独绞尽脑汁设计网络,大大减少了网络的设计成本。不过因为没有使用ViT的小块拆分结构,所以训练速度会很慢,而且在小物体检测上没有改进。
本文是首先尝试将目标检测和Transformer结合起来的人,成为了后来的基线。对细粒度图像检测来说,之后可以尝试和Swin Transformer结合,得到最后一阶段的输出后,一部分进行分类预测,另一部分输入进类似的架构进行目标检测,因为已经得到了编码后的内容,可以直接将其送入解码器得到部件锚框,并进行改进训练。

若有收获,就点个赞吧
0 人点赞
