简介
目前大部分科学家都致力于解决Vision Transformer需要大量数据预训练的问题进行优化,作者则另辟蹊径,选择对ViT的自注意力机制进行优化。
作者提出了一种新方法优化了自注意力嵌入层尺寸和多头注意力头数之间的问题。同时,为了解决自注意机制过分重视全局信息,而忽略局部信息,作者使用了类似卷积神经网络卷积的方法,改进了自注意力层。
作者通过这种方法有效优化了ViT的性能,在不增加过多计算量的前提下,在多个数据集上达到了比基础ViT更好的表现。同时该模型在语言模型上表现也有不错的表现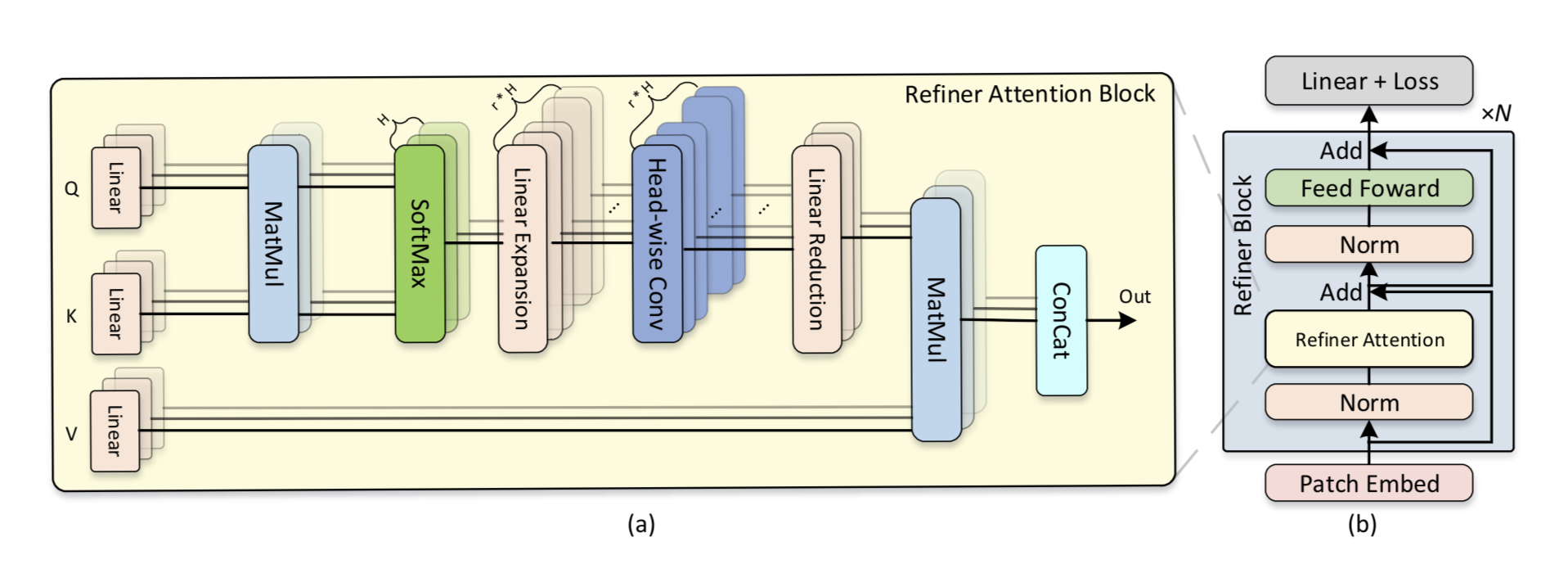
方法
ViT的局限性
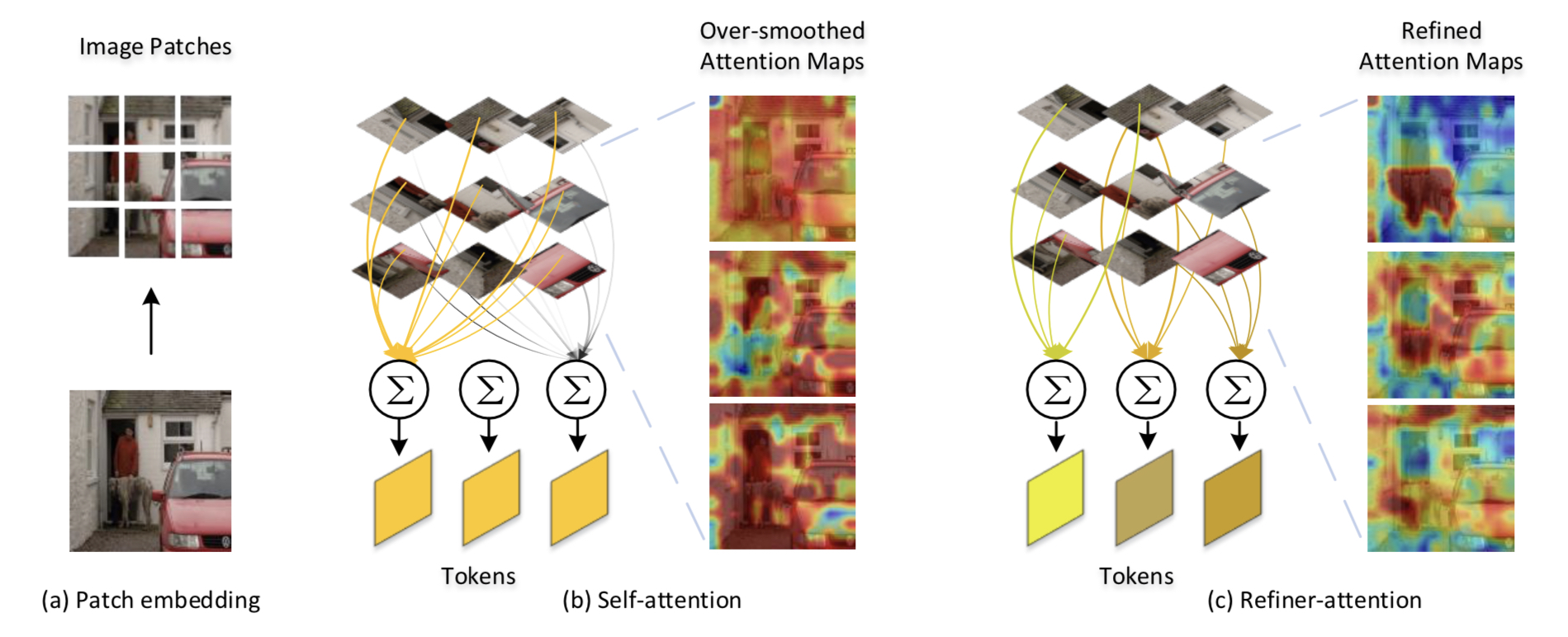
ViT中对信息的聚合完全依赖于自注意机制,作者发现,和ResNet和最新单独针对ViT改进,加入了大量局部信息的架构DeiT相比,传统ViT在增加网络深度后,性能几乎没有提升,并且底层和顶层特征的相似度也更大,作者想到这可能是原架构因为没有融合局部特征导致的
优化头数和嵌入维度
作者发现,增加ViT中自注意力模块的头数可以显著增加模型性能的表现。但是如果保持嵌入维度不变的前提下,单纯的增加头数,会导致每个头部获取的内容变少,同时会导致注意力图更加分散难以理解
作者对每个头部的注意力图进行线性投影,让每个头部中有多张注意力图,由此可以在不减少嵌入层尺寸的前提下,隐性地提高了注意力图的维度,让模型可以同时享受更深潜入层维度和更多头数带来的精度提升
同时,该方法可以在不显著增加计算量的情况下直接替换ViT中原有的自注意力模块,方便未来使用
全局和局部注意力
作者受到ViT自注意力方法的启发,传统自注意力是将所有小块的信息都进行聚合,这样生成的注意力图往往没有明确的焦点,
于是作者提出进行注意力运算时,只考虑相邻的小块的信息将其加入注意力机制,这样可以得到局部注意力的输出结果,将多个这样的模块生成的注意力相加,作者将其称为分布式局部注意力
作者将分布式局部注意力和常规注意力产生的全局注意力信息进行聚合,两者互相弥补各自的缺点,该架构可以很好的解决全局和局部上下文信息的融合问题
总结
综上,作者提出的架构优化了ViT中的自注意机制,同时留下了很多可以进行拓展研究的方向
- 注意力图被标准化为0-1之间,是否可以突破限制来更强调局部特征呢
- 在全局注意力上做加法是个好方法,那做减法呢
- 该模型通过分布式局部注意力学习了归纳偏差,那如何让其他模型自己学习到这个偏差呢

若有收获,就点个赞吧
0 人点赞
