简介
细粒度草图检索是使用手绘草图作为查询方式来寻找匹配的照片,该任务的关键挑战是视觉空间的差距,现有模型着重于直接比较草图和照片的特征空间,将正样本放入更近的位置,负样本嵌入到更远的位置。不过因为在特定领域训练,所以无法很好的跨类别泛化,而且草图的样本标注十分昂贵。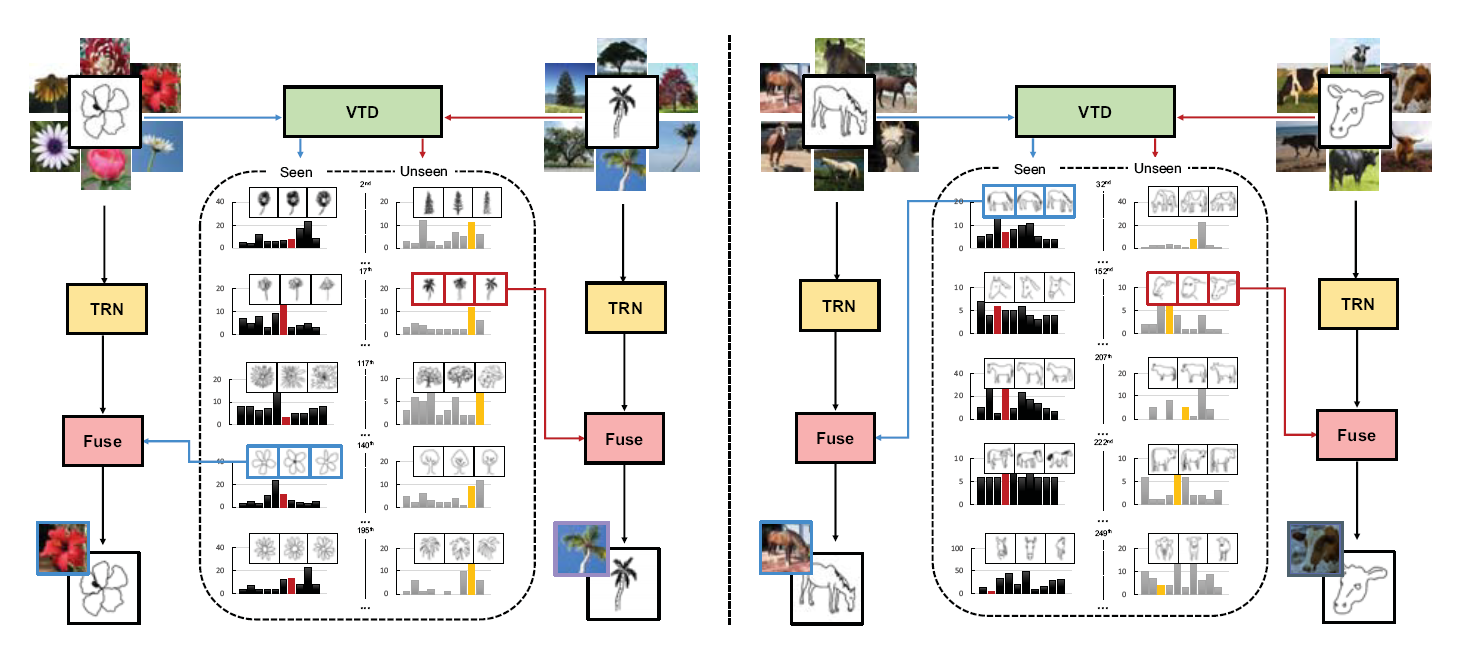
本文为了解决提出了一种无监督学习方法,对原型草图特征进行通用建模,从而首次解决了跨类别泛化的问题。该模型可以对草图和照片的表示进行参数化建模,通过在模型中加入新的操作并相应的更新检索功能,可以自适应适应新类别
本文还提出了一个新的评判标准,在检索数据集上证明了该网络的泛化性。
方法核心
本方法主要有两部分组成,首先是无监督嵌入网络通过编码器-解码器结果将草图映射到特征空间用于查询。然后制定了三元组损失的动态参数化特征提取器,通过生成的描述来寻找距离最小的照片。通过无监督的方法进行训练。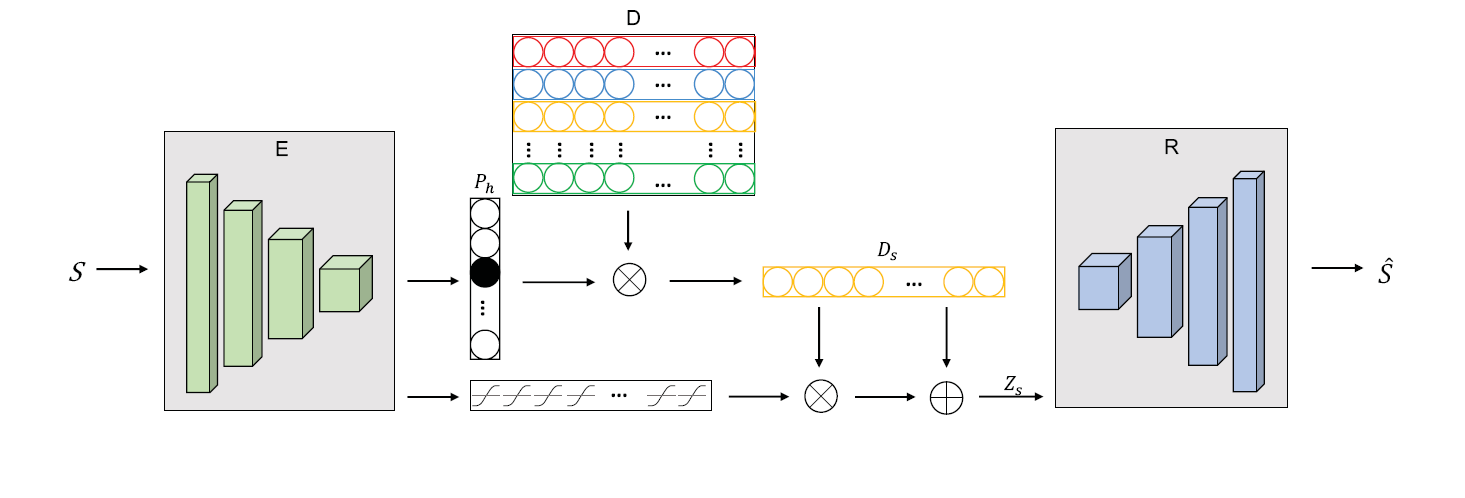
通用特征嵌入
编码器解码器
无监督网络需要将特征映射到字典D中的条目里,字典一共K行,需要预先定义,然后使用正态分布随机初始化。网络的目标是将草图随机映射到这K行中的一行里。
使用卷积神经网络提取草图特征,然后通过softmax输出K个结果,将特征嵌入到概率最大的对应行,然后将这K行描述符进行解码,由于最后类别往往有上万个,而K很小,所以大量特征被压缩,重建效果很差。所以这里需要进行残差链接,将输入经过tanh函数以一定权重连接到字典中
硬分配
由于需要使用到argmax,所以这个过程是不可微的,这个算法还同时拥有高方差。硬分配方法采用了Gumbel-Softmax来替代传统softmax,然后再用独热编码进行硬分配,可以有效减少噪声的影响,降低方差。为了防止样本仅分配给字典中的一部分描述符,这里设置一个均匀分布,将输出的概率和均匀分布计算KL散度作为损失,尽可能确保每个批次样本被分配到不同描述符中
软分配
由于使用交叉熵损失,所以本文联想到,如果在映射到字典时不使用硬分配,而是根据输出的概率,按照概率比例输出到字典的各个描述符中,同时保证概率的稀疏,所以本文定义了行损失和列损失,行损失鼓励网络输出一个主导标签分类,当独热编码时取得最小。列损失则在均匀分布时取到小。在更新过程中动态替换字典里的内容,每轮结束后,选择最集中的描述符,对其增加一个小的扰动,从而提高泛化能力。
优化目标
根据以上描述,除了最后的重建损失,硬分配需要减少KL散度,保证尽可能均匀分配,而软分配需要最小化行列交叉熵,然后用来控制各项损失的比例。
动态参数化
每个草图都会经过编码器提取到描述符,然后将其参数化为三元组排序网络,用作草图和照片的通用化表示。提取时将卷积神经网络的特征和编码器的特征相乘,加上残差链接后得到这个动态参数化的特征提取器:
在验证时,将标签也输入到特征提取器当中,然后计算是否正确分类,得到三元组损失
总结
本文和细粒度图像分类几乎完全不相关,不过本文将图像特征存储到字典中的方法可以参考。不过本文的方法也有不少缺点,首先过于复杂难以理解,其次定义非常多的损失函数,相当于加入了很多先验知识进去,同时损失函数带来了很多超参数,为后续的优化带来了很大的困难。
在存储到字典的过程中,除了使用损失函数来规范嵌入的过程,还可以对字典的内容或者特征进行归一化处理,从而减少分布不均匀。或者使用Dropout的方法,每次随机屏蔽掉一定的字典数来保证均匀分布。

若有收获,就点个赞吧
0 人点赞
