问题动机
语义分割在自动驾驶、增强现实上有着广泛的应用,然而目前最先进的全卷积网络固定的几何结构导致了限制了它感受野的大小和对图片上下文信息的获取,由此影响了语义分割的精度。
对此不少人对此问题进行研究,比如使用金字塔结构或者池化方法获取信息,然而并不能生成密集的上下文信息。后来提出的自注意力机制虽然可以获取全局上下文信息,但是时间复杂度过高,且需要占据很大内存,于是作者提出了这个可以高性价比提取密集上下文信息的架构。
简介
作者提出了使用循环交叉注意力模块来替代原有的注意力层。首先对每个像素的水平、垂直方向的像素提取注意力并输出,而不是整个特征图,作者称之为交叉注意力模块,通过交叉注意力模块聚合水平、垂直两个方向的上下文信息,将输入再次应用交叉注意力模块,便可以从所有像素中收集上下文信息,因为只需要计算纵横个方向的注意力,计算复杂度从O(H×W×H×W)降低到了O(H×W×(H+W-1))。作者将该架构成为CCNet
CCNet相比其他可以融合全局上下文信息的架构,所需要GPU的内存使用量降低了11倍,计算全局上下文时,减少了85%的算力要求。同时该架构在多个语义分割数据集上达到了当前最佳水平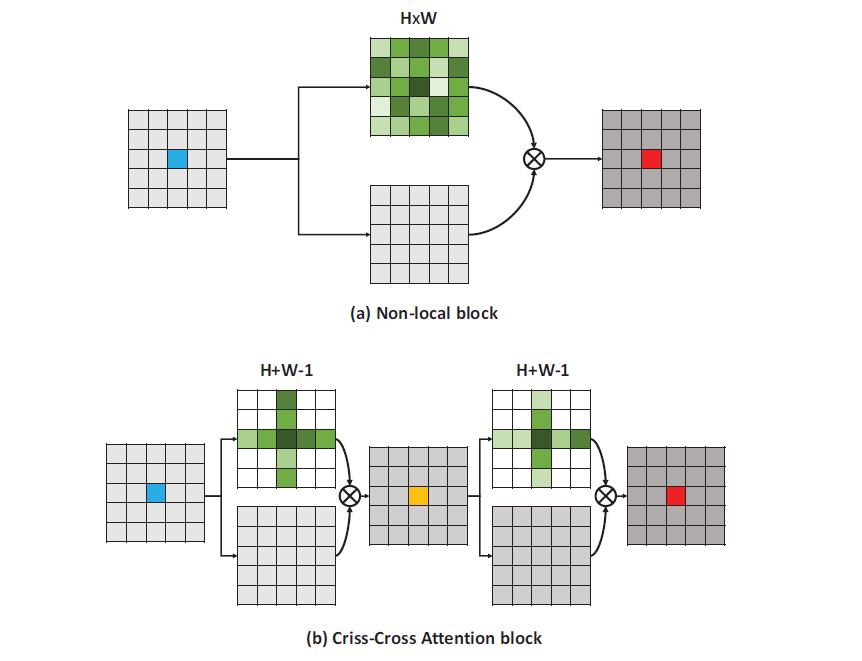
方法核心
CCNet网络架构
首先将输入送入卷积神经网络中,得到卷积神经网络的输出的特征图后,首先运用卷积层来减少特征图的通道数,然后将其输入到交叉注意力模块,这些特征图将其水平,垂直两个方向的所有像素的上下文信息聚合到一起,然后再次将刚才的输出输入到交叉注意力模块中,于是,最后输出的特征图中包含了所有像素的上下文信息。
和常规残差网络将不同的是,作者将未经过交叉注意力模块的输入和刚才的输出连结(Concatenate)起来,再经过若干具有批量归一化和激活函数的卷积层进行特征融合,最后送入分割层预测结果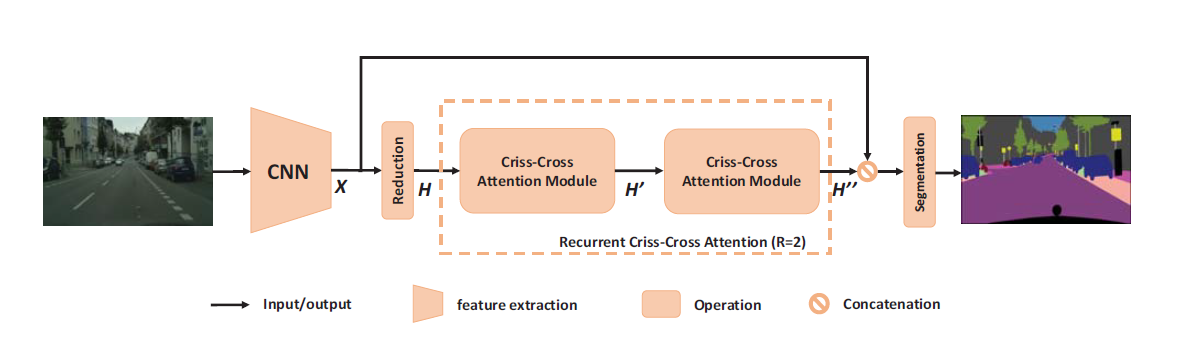
交叉注意力模块
对于一个给定的特征图,首先在该特征图上应用2个1×1卷积核的卷积层,生成两个特征图,分别用作查询和键,输出尺寸为(C,H,W)其中C小于原有通道数,主要用作降维,减少计算量。
查询特征图上的每个像素的各个通道组成一个特征向量Qu,在键特征图上的对应像素点对应的横向、竖向像素点的各个通道Ωiu,尺寸为(H+W-1,C),作者于是进行仿射操作,将Qu和Ωiu.T相乘,得到融合信息横向、竖向多通道的融合信息D,尺寸为(H+W-1,H,W),将该信息通过softmax层后得到仿射图
将特征图再应用一个1×1卷积核的卷积层,生成的值用作值图,和仿射图相同,得到Vu和Viu,(H+W-1,C)为了聚合仿射图和值图,对于横向纵向上的每个像素点,将仿射图对应的值图的值相乘,再加上输入的残差,同时尺寸恢复为(C,H,W)。
通过以上操作,上下文信息就被添加到了局部特征当中,最后得到的新特征图的每个像素点就聚合了其横向和纵向的上下文信息。
循环交叉注意力
单个交叉注意力模块无法获得每个像素与其不相邻像素的信息,于是作者提出了循环交叉注意力。在经过一轮交叉注意力模块后,每个像素都包含了纵横向像素的上下文信息。进行第二轮纵横方向的信息融合时,对于每个像素,可以获得其他各个像素都可以在横向和纵向上的信息。只需要两个循环,就可以从所有像素中获取上下文信息, 同时大幅度减少了所需的参数量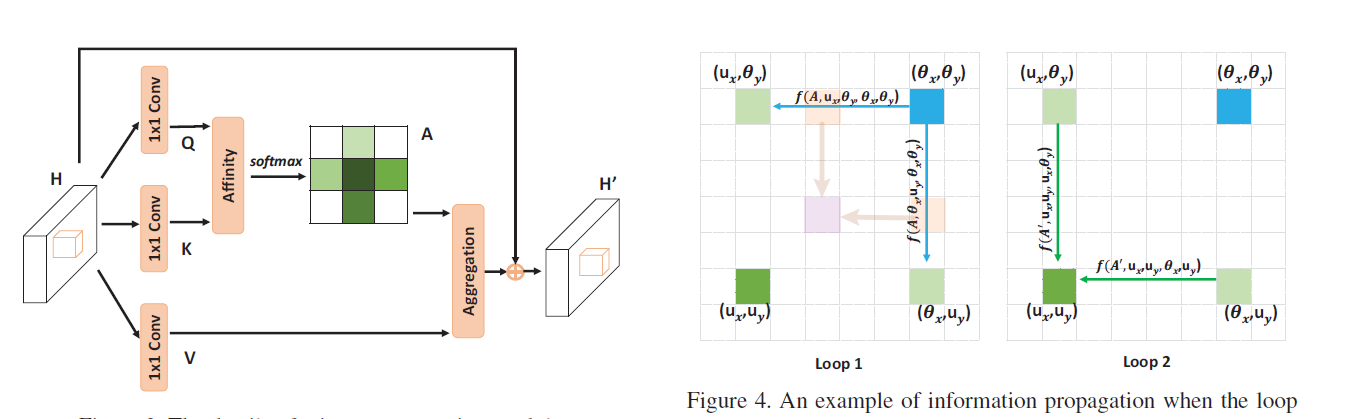
实验过程
作者在Cityscapes、ADE20K,COCO数据集上进行了实验,结果发现,在Cityscapes、ADE20K上实现了当前最佳性能,同时能为COCO数据集带来性能的提升
实验细节
网络架构
作者使用了在ImageNet上预训练的ResNet-101网络作为基础卷积神经网络,然后移除了最后两个下采样。输入交叉注意力模块的尺寸为原本尺寸的1/8
优化算法
作者使用带动量的SGD作为优化器,学习率调度采用了曲线类似余弦调度的幂调度方法,计算公式为,其中power是超参数,默认值为0.9。对于训练数据,作者使用随机缩放,从0.75-2.0
实验结果
为了验证CCNet的有效性,给目前优秀的架构使用了更加强大的主干网络,并且使用了更大的数据集进行预训练,在验证集上进行多尺度图像预测[1],CCNet仍然优于这些架构的表现
在测试集的表现上,其他架构都使用了相同或更强的主干网络,CCNet仍然取得了最优成绩,其中PSANet也使用了注意力图,思路和作者接近,不过每个像素需要2×H×W个权重,而作者仅需要H+W-1权重,消耗更少的计算量和内存的同时达到了更高的精度
消融实验
循环交叉注意力
作者在模型中加入不同数量的交叉注意力模块来测试不同数量循环交叉注意力的影响,结果表明,添加一个模块对精度有很大幅度的提升,加入两个模块,精度仍有2%的提升,不过加入第三个模块时,计算量增加了50%,但是性能只有0.3%的提升。
结果表明,加入交叉注意力可以有效捕捉上下文信息,提高语义分割的能力,为了平衡性能和精度,加入两个模块性价比最高。
计算量需求
和多个其他融合上下文方法对比,其中non-local(NL)架构性能最接近CCNet, CCNet所需的计算量仅有NL的15%,内存需求仅有NL的9%,在达到更高精度的同时极大幅度减少了计算量和内存需求。
注意力图可视化
作者通过注意力图可视化发现,只有一个交叉注意力模块时,只能提取到少量的注意力信息,而且只有水平和垂直两个方向的线性信息。当使用循环交叉注意力时,注意力图已经可以提取出全局信息
总结
作者在本文中提出一种创新型的注意力融合方法,每次对每个像素点横向和纵向十字型的像素点提取注意力,将此模块循环若干次,便可以在大幅度降低时间复杂度的情况下同样融合全局上下文信息,将注意力操作的时间复杂度降低了O(n)。同时因为更高效的融合了上下文信息,在多个数据集上取得了最佳水平。
结合组会汇报的情况,因为交叉注意力模块大幅度降低了提取全局信息所需要的计算量,我想到能否将此注意力模块移动到卷积神经网络之前,因为这样可以提前降低不重要信息的权重。同时,同时提取横向和纵向注意力可以融合全局信息,不过既然使用循环交叉注意力,那完全可以一个模块提取横向注意力,再紧接着提取纵向注意力,这样操作一样可以提取到全局上下文信息,不过又将计算量消耗减少了一半。近期可以对其进行实验。
- 将图片进行不同尺度的缩放,得到图像金字塔,然后对每层图片提取不同尺度的特征,得到特征图。最后对每个尺度的特征都进行单独的预测。不同尺度的特征都可以包含很丰富的语义信息,精度高,速度慢。 ↩︎

若有收获,就点个赞吧
0 人点赞
