问题动机
在科学界,对于模型的精度和可解释性一直存在着争论,尤其是是在一些高风险决策的领域。现有可解释性方法一般都是事后解释,比如可视化神经元,反卷积特征图或者使用激活向量来解释网络。相比之下,传统机器学习算法中的决策树有着易于理解的优点,决策规则透明地按照层次结构排列。然而决策树的预测性能远不及深度学习,所以作者想到能否将深度学习的高精度和决策树可解释性相结合,使用基于原型的方法展示决策过程来解决深度模型的黑盒性,达到准确性—可解释性的平衡。
简介
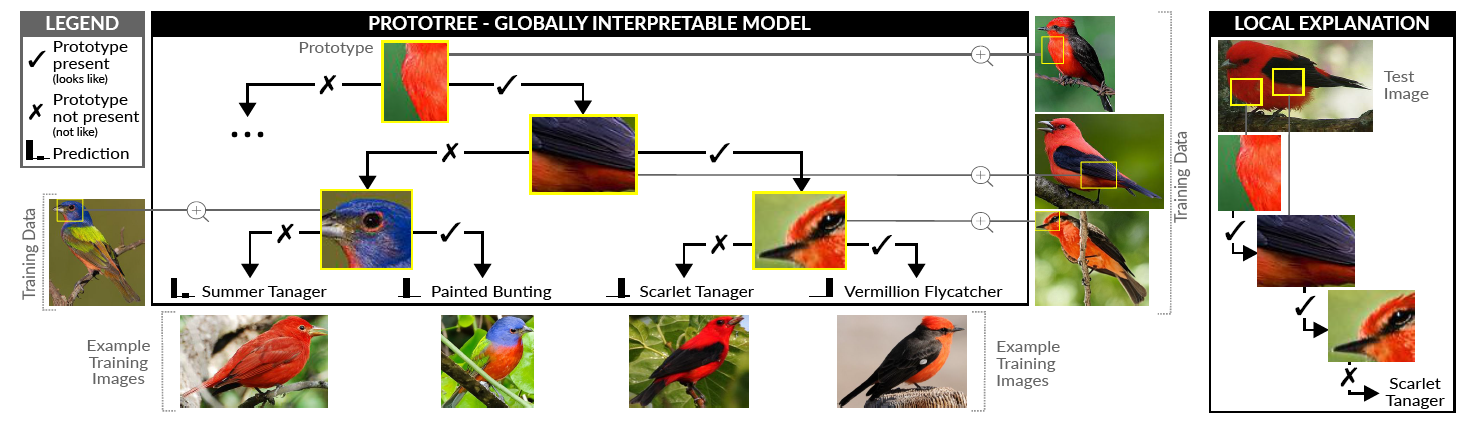
本文提出了本质上可解释的用于细粒度图像识别的神经原型树(ProtoTree)。神经原型树将卷积神经网络和决策树相结合,从而设计出全局可解释的模型,并且只需要图像级标签便可以通过标准的交叉熵函数进行端到端的训练。
神经原型树的构造如下:
- 每个节点都包含一个可训练的原型,表示图像中内容的一个部件,同时与反向传播兼容
- 树的路径表示决策规则,可以通过概览决策路径来局部解释单个预测
- 每个叶子节点使用了软决策树输出分类结果,最终分类结果加权所有叶子节点的输出
图像上每个原型的存在与否决定了决策路径是否通过这个节点,决策的过程和人的推理过程十分相似,提供了可信的全局和局部解释,允许人类追溯决策步骤,甚至可以直接打印出模型,简化错误分析。和以前的决策树相比,本文还使用修剪和二值化进行优化,原型数量只有之前的10%。
在鸟、车数据集上取得了和不可解释的分类器相似的分类精度,充分表明了神经原型树的强大能力。
方法核心
神经原型树
神经原型树使用二叉树路径决策进行可解释的细粒度图像识别,本文使用独热编码的真实标签y,计算预测概率与真实概率的交叉熵来训练原型树,同时也可以使用知识蒸馏预训练的软标签进行训练。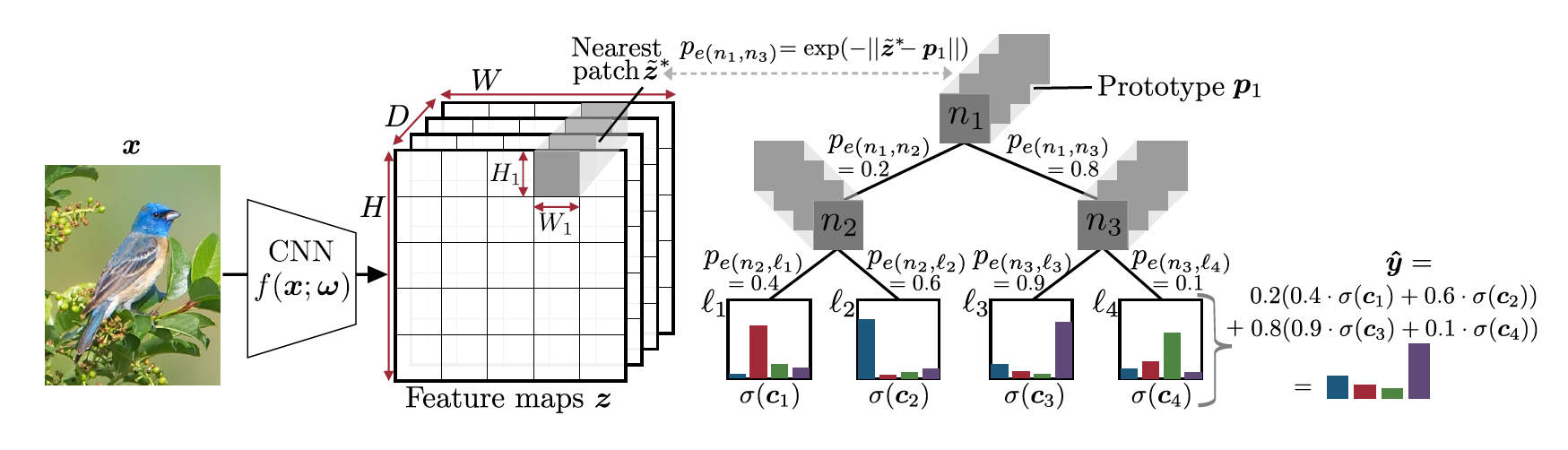
首先对图像进行卷积操作,得到的D维特征图作为二叉树的输入,每个非叶子节点代表着一个可训练的原型,其中原型表示为特征图上的一个尺寸(H1,W1,D)的可训练张量,可以理解为一个特征部件。
然后让每个原型在特征图上滑动,按像素最小汇聚找到和原型在欧氏距离小的一个小块。潜在的小块和原型之间的距离代表着该原型在特征图中存在的程度,本架构使用软决策树,根据距离来决定左右分支的概率,这里默认左分支的概率小于右分支,将分支的概率作为最终决策的权重。
左分支的概率为。对每个原型执行相同操作,遍历所有边,并以一定的概率到达每个叶子节点,概率为所有路径的概率的乘积。每个叶子节点需要学习在K个类别上的分布,为了得到最终概率分布,每个类别计算所有叶子节点上该类别概率和路径概率的加权,其中表示softmax函数
训练过程
原型提取
首先决定树的最大高度h,创建个叶子节点和个原型。首先加载预训练的卷积神经网络,在训练期间,树中的原型和卷积神经网络同步更新,最小化和真实标签的交叉熵损失。学习的原型会尽可能接近图像中潜在的部件,找到最相似的图像小块作为原型的可视化
叶节点优化
在传统决策树中,叶子节点的标签实在最后识别的叶节点中学习的,由于本文使用软决策树,优化叶子节点的分布是一个全局性的问题,作者发现如果直接尝试将梯度反向传播,分类结果较差。根据前面的研究发现,单独优化叶子节点是个凸优化问题,并提出了一个无导数优化策略,作者将其应用到本方法中,同时针对批量计算进行优化,每个批量计算卷积损失的同时优化叶子节点
可视化和解释性
修剪
在神经原型树中,网络的可解释性随着原型的增加而递减,所以需要修剪掉不需要的原型。这里优先选择没有辨别力的原型,即概率分布趋近于均匀分布的原型。具体而言,事先定义一个门槛,当概率分布的最大值小于门槛时,该节点及其所有叶子节点全部被舍弃,其中可以设置的比1/K稍微高一点。删除一个节点后,其双亲节点也被删除,兄弟节点替换双亲结点。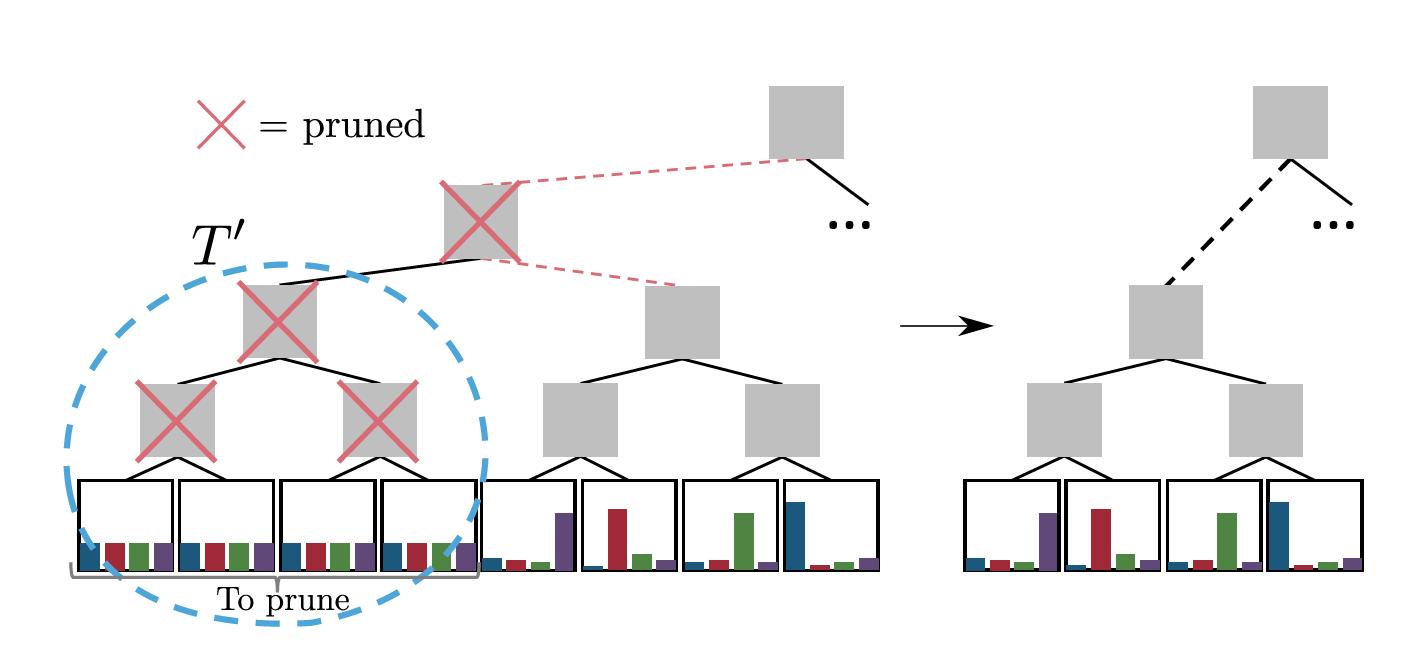
可视化
对于潜在的原型需要映射到像素空间来实现可解释性,于是在一个批量中选择和原型最相似的小块作为原型可视化结果,对特征图每个小块计算相似度,得到相似度矩阵,然后找到最高相似度的小块进行双三次插值进行上采样,将特征图的对应位置的小块提取出来。
硬标签
软决策树中,所有叶子节点对预测都有贡献,而硬决策树中只有路径上的节点才能进行最终预测,这使得网络比软决策树更容易解释。所以在训练过程中使用软决策树,测试期间转换为硬决策树。本文使用了两种方法,并评估了各自的精度
- 选择路径概率最高的叶子节点
- 从根节点开始贪婪的遍历树,选择概率大于0.5的那个方向向下遍历
实验
精度和可解释性
作者在鸟和车数据集上进行了实验,实验结果都优于之前的可解释模型ProtoPNet,同时作者使用了3-5个神经原型树进行集成预测,精度一样优于前模型,精度毕竟其他不可解释的模型,同时提供了可靠的局部解释和全局解释树的高度
原型较少的模型更容易解释,不过也只能应用在不是很复杂的任务上,作者对树的高度做了消融实验,当树到9层以后精度趋于平稳,同时增加高度对车数据集影响更大,因为车辆之间类内相似度较低,容易产生不平衡的树。集成学习显著增加了精度,不过也降低了可解释性修剪
由于训练算法是最小化预测和独热编码的误差,因此大多数叶子节点都趋近于均匀分布,将阈值设置为(均匀分布的2倍)就可以获得所有可解释的叶子节点,实验表明,修剪掉多余的叶子对精度几乎没有影响。修剪操作将叶子节点数降低到了原来的10%,差不多每个类只保留一个原型
原型替换对于精度也几乎没有影响,因为每个原型距离最近的小块距离几乎为0,说明原型树已经优化了原型,使之无限逼近特征图的小块,也证实了在一个批量训练完之后更新补丁即可硬标签方法
实验了软标签和两种硬标签的性能,几种方法的差距十分小,其中最大概率法精度最高,不过也可以证实,软决策树可以安全的转换为硬决策树,保真度仍然接近1。使用确定性预测后,在鸟数据集上,参与决策的原型最多减少到9个,和以前2000个比是飞跃性的进步可视化
通过可视化决策过程,作者发现原型通常和感知相关,并成功的将相似的特征类别聚集到一起,但是仍然有部分原型选择的是背景内容导致了分类偏差,未来可以研究如何人工的降这些错误的原型剪除。通过进一步分析发现,网络和人判别图片的思路不完全相同,其中颜色和形状在网络中占有更大权重,其中部分原型和图片相似的地方也无法直观解释。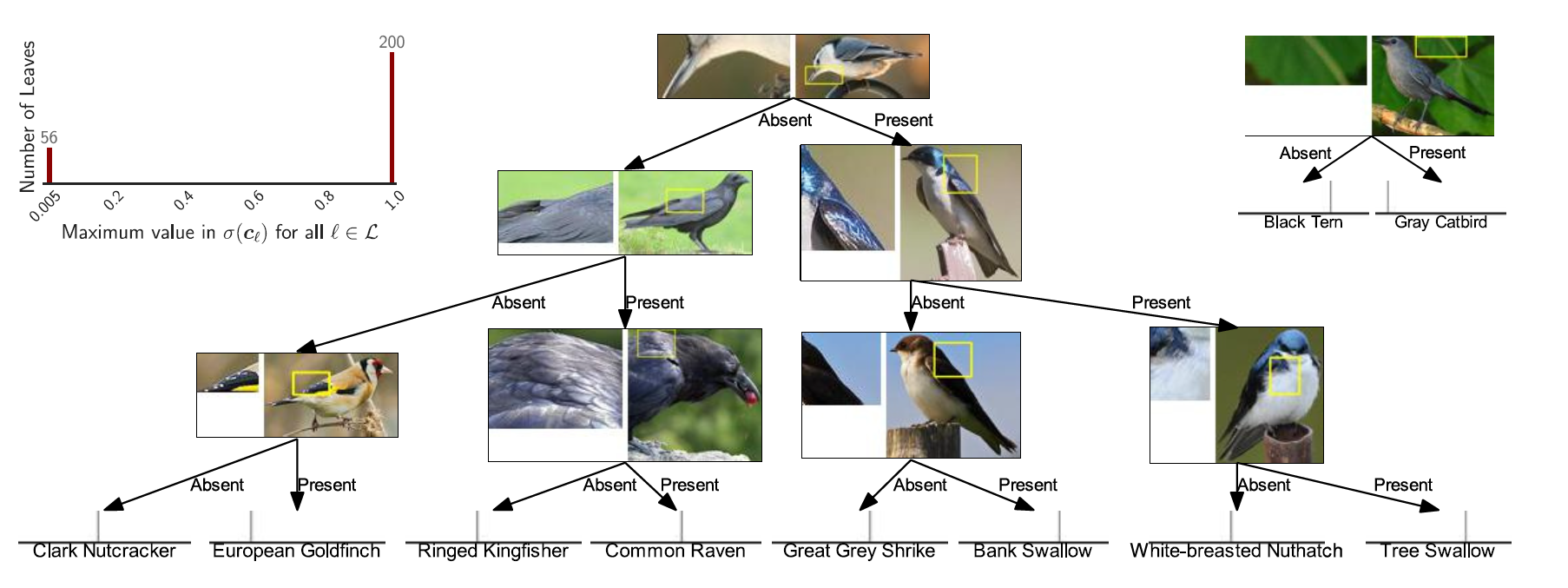

总结
本文使用了类似猜人游戏方法,通过多个二元问题对图像进行可解释的分类。使用将二叉决策树和神经网络相结合,通过训练来学习输入图像的原型部件作为分类依据,路径作为分类规则,叶子节点表示分类结果的概率分布,经过优化和压缩,可以将原型总数压缩到8个,保证了计算速度、精度、可解释性的平衡
之前我也想到使用类似的方法,在akinator这款游戏里,仅需15个左右的问题,就精准的定位到现实、游戏里的任意一个角色,充分证明了该架构的无限可能性。本文使用的是二叉树搜索结构,那能否移植到多个分支的树形结构中呢。二叉树的问题是如果在上层节点判断错误后,后续很难正确分类。这里在拓展到多分支之后,可以使用蒙特卡洛树搜索算法,找出最可能若干个分支节点进行搜索。这里可以参考AlphaGo的搜索策略。
本文的另一个创新点在于成功将图像分类问题转换为搜索问题,将新问题转换为老问题,可以在这个基础上应用更为传统的方法,可以尝试将深度网络和其他传统算法相结合,拓宽了未来研究的方向

若有收获,就点个赞吧
0 人点赞
