问题动机
原生的ViT在细粒度图像分类任务上表现并不是那么出众,主要是因为ViT中每个小块的大小固定,感受野的大小无法有效拓展,限制了每个小块中所携带的注意力,深层的类标签专注于全局感受野从而无法生成更多尺度的特征。
简介
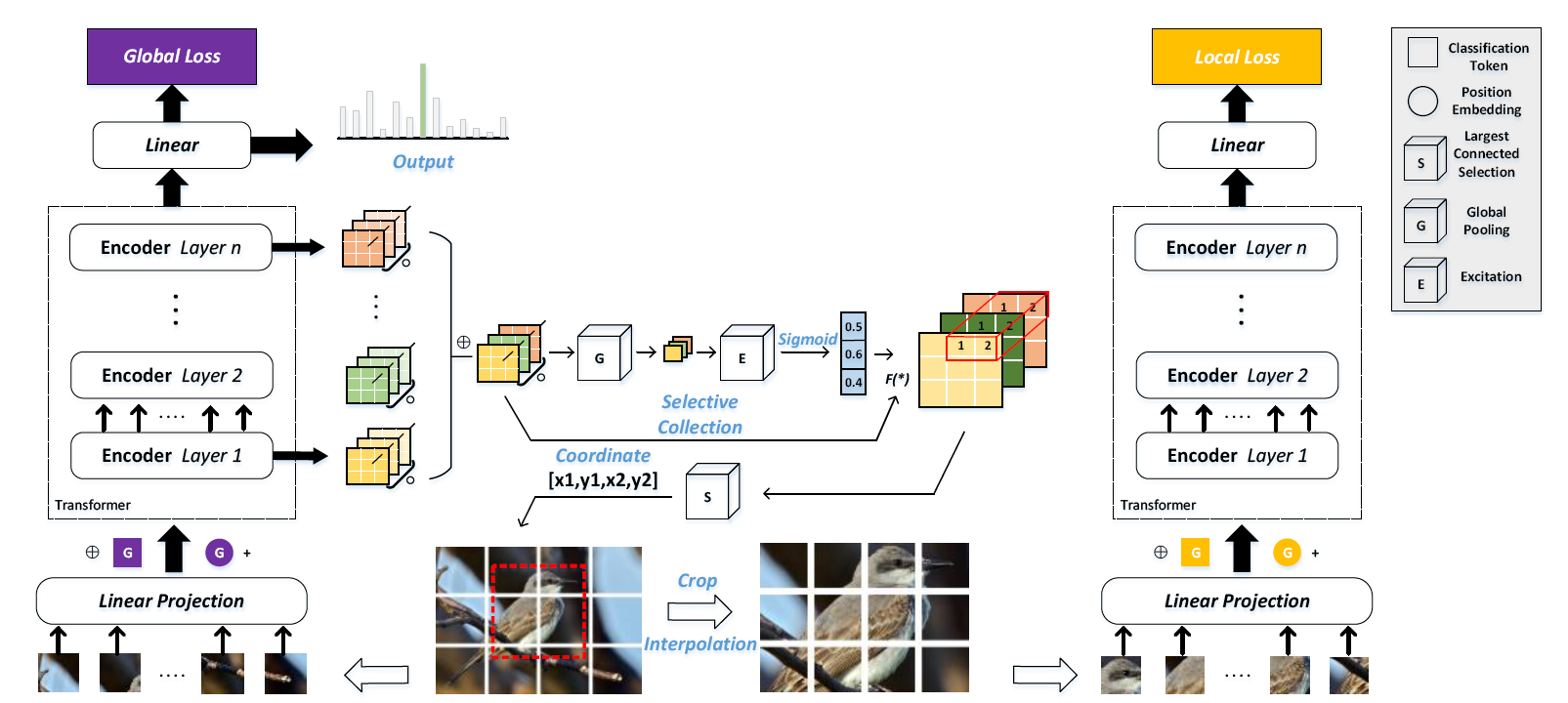
本文提出了一种自适应注意力多尺度融合ViT(AF-Trans),本模型的选择性注意力收集模块(SACM)利用ViT的注意力图权重自适应的为注意力图应用不同权重,使用阈值过滤注意力图的信息后,使用最大连通子图获得判别性区域坐标。通过全局和局部通道共享编码器权重,可以实现端到端训练
通过实验证明,AFTrans可以在鸟、狗、iNat2017上实现最先进水平
方法核心
选择性注意力收集模块
为了更有效的寻找原始图像的局部判别性区域,本文提出了选择性注意力收集模块,核心方法是收集每个Transformer层多头自注意力的权重,并自适应地微调他们对注意力图的感知贡献。通过计算获得注意力图
作者认为对每个头的注意力图进行Hamada积计算可以累加和放大该层的注意力,所以将每个Transformer层的每个头的注意力图进行按位相乘,得到每层的注意力图 ,然后将每层的注意力图连接起来得到注意力权重图
,然后将每层的注意力图连接起来得到注意力权重图 ,尺寸为
,尺寸为(N,L)
为了寻找所有注意力图中的最重要的部分,对L层注意力图做选择性注意力计算。
- 首先对
 做全局平均汇聚运算,此时尺寸为
做全局平均汇聚运算,此时尺寸为(1,1,L) - 使用带ReLU激活函数的多层感知机和缩放因子
r将其维度缩小r倍,尺寸为1,1,L/r - 在使用多层感知机将其注意力重新映射为
L,得到层注意力向量 ,尺寸为
,尺寸为(1,1,L) - 然后将层注意力向量和注意力权重图相乘,相当于对各层的注意力图做了一次注意力运算
此时新注意力权重图 反应了各层图像标记之间的相关性,为了选择有效的标记进行分类,对
反应了各层图像标记之间的相关性,为了选择有效的标记进行分类,对 进行阈值操作,生成连通二值图,对所有层的连通图使用最大连通区域搜索算法,提取
进行阈值操作,生成连通二值图,对所有层的连通图使用最大连通区域搜索算法,提取 的最大连通分量,从而可以在原始图像中获得局部判别性区域的定位坐标。
的最大连通分量,从而可以在原始图像中获得局部判别性区域的定位坐标。
多尺度融合
为了提高不同尺度图像的稳健性和分类能力,本文还使用了多尺度的特征提取方法做为基本框架。首先将原始图像输入到ViT中,得到全局损失,在得到判别区域的小块定位后,对原图进行剪裁得到局部图像,通过双线性插值缩放到标准尺寸,然后与自己的类别标签一起再次输入到原本的ViT中,得到局部损失。总损失是两者的加权和。其中局部损失可以引导选择性注意力收集模块寻找更具有判别力的区域,从而使得网络能够同时根据对象的整体特征和局部特征进行预测,在推理阶段时,使用全局预测的结果作为最后结果。
实验
本文将原始图像尺寸缩放为448×448,局部区域缩放为224×224。
实验结果
将AFTrans和目前的最先进水平进行比较,在鸟、狗数据集上取得了最先进水平,和ViT相比有1.3%的提升,和TransFG相比实现了0.6%的提升,其中在狗数据集上强于ViT的水平0.4%,和TransFG相比提高了1.2%,超出,在汽车数据集上仅次于最先进水平,因为背景较少,所以定位的效果不佳,也因为自适应注意机制在捕捉不同物体上的差别。
在大规模数据集iNaturalist2017上,背景和计算十分复杂,传统模型很少使用iNat2017进行测试,不过ViT本身就是为了超大型数据集而生的,AFTrans比ResNet-152高9.0%,和TransFG相比有0.9%的提升
消融实验
如果不使用选择性注意力收集模块定位局部区域,并使用局部损失更新,本方法就退化为ViT,精度下降了1.1%,可能是因为自适应的融合了注意力图贡献的感知,并且注意力图的重要性大于输入小块的重要性
在最后预测的时候,只使用主干网络预测的效果最好,因为是从全局的角度观察整个输入图像,获得的信息更多。
阈值 的影响,作者从0.1到0.5分别测试,发现0.4时效果最好,巧合的是,TransFG中对比损失的阈值也是0.4的时候最好,甚至在之前的一篇水文分段线性激活函数里,最好阈值也是0.4,值得进一步研究。
的影响,作者从0.1到0.5分别测试,发现0.4时效果最好,巧合的是,TransFG中对比损失的阈值也是0.4的时候最好,甚至在之前的一篇水文分段线性激活函数里,最好阈值也是0.4,值得进一步研究。
在获得了经过阈值筛选的各层二值图之后,一种方法是选择坐标转换的极值作为边界点,另一种是提取坐标的最大连通分量,其中连通分量法获得了更好的性能。
可视化

AFTrans提议的局部区域包含了丰富的细粒度信息,其中边界框是通过SACM融合的注意力图获得的,比如捕捉到了鸟类的头部、翅膀等。但是这个机制也有着比较严重的问题,它只能捕捉一部分判别性部件的区域,比如只能捕捉头或者翅膀,没有包含整个主体,同时只生成了一个区域。
总结
本文的思路比较特别,对注意力图再次进行注意力计算,然后使用数字图像的最大连通子图算法选择图像的的重点区域,再次使用相同的网络进行预测,并使用局部损失更新网络,在最后预测阶段,因为可以不用额外的计算,计算开销和普通ViT相同。
本文的方法和TransFG有着本质的区别,和我设想的对所有头选择最重要小块的方法也有着明显的区别,我认为使用这么一系列复杂的操作,只为了找出物体主题所在的区域,有效性和效率有待提高,像实验中一样,捕获的连通区域往往只覆盖了部分判别性部件。
如果只是为了寻找图像中的主题区域,完全可以使用DETR直接进行定位,可以在Transformer中一次性完成,至于多尺度融合,其实相当于对ViT的局部注意力额外增加了一次主体的注意力,这样更新网络的方法可以参考。
未来可以结合Transformer的主体定位、部件定位、最重要小块等多种方法来强化判别性部件在Transformer的权重,也可以参考本文的方法,对局部区域进行分类时共享同一个网络,再使用局部损失更新网络。同时可以优化注意力图,保证网络的可解释性。

若有收获,就点个赞吧
0 人点赞
