问题动机
细粒度识别的训练样本一般服从长尾分布,很多类别的训练样本很少或者没有。所以尝试在没有训练样本的情况下,通过捕获细粒度知识并将其从已知类别转移到未知类,而不过拟合已知类,是个非常有挑战的任务,不过也将细粒度识别推广到新类成了新的研究方向。
一般来说,零样本分类利用语义描述形式的辅助信息来推广到未知类,现有的工作尝试将视觉特征和其语义向量对齐,由此来对未知类分类,然而这些方法所依赖的特征往往不足以进行细粒度分类,因为判别信息往往在少数区域对应的少数属性中。特征合成技术使用类语义向量生成图像特征,但只能合成高级特征,无法捕捉已知/未知类的细粒度差异
简介
本文提出了一种基于密集属性的注意力机制,该机制针对每个属性关注最相关的图像区域提取基于该属性的特征,并构建特征向量,再每个特征与其对应的属性语义向量对齐,而不是让整个图像的特征组与类别语义向量对齐。根据每个属性的存在与否计算属性得分向量,让其与真实类别的向量相似度最大化,同时使用注意力模型调整每个属性得分,保证可以保证不同属性的判别力。
同时为了解决已知类数量不均衡的问题,本文还提出了自校准损失,用于应对已知类偏见,他可以调整未知类的概率来处理训练偏差。
作者在鸟、太阳、AWA、DeepFashion进行了零样本实验,证明本方法明显改进了现有零样本识别技术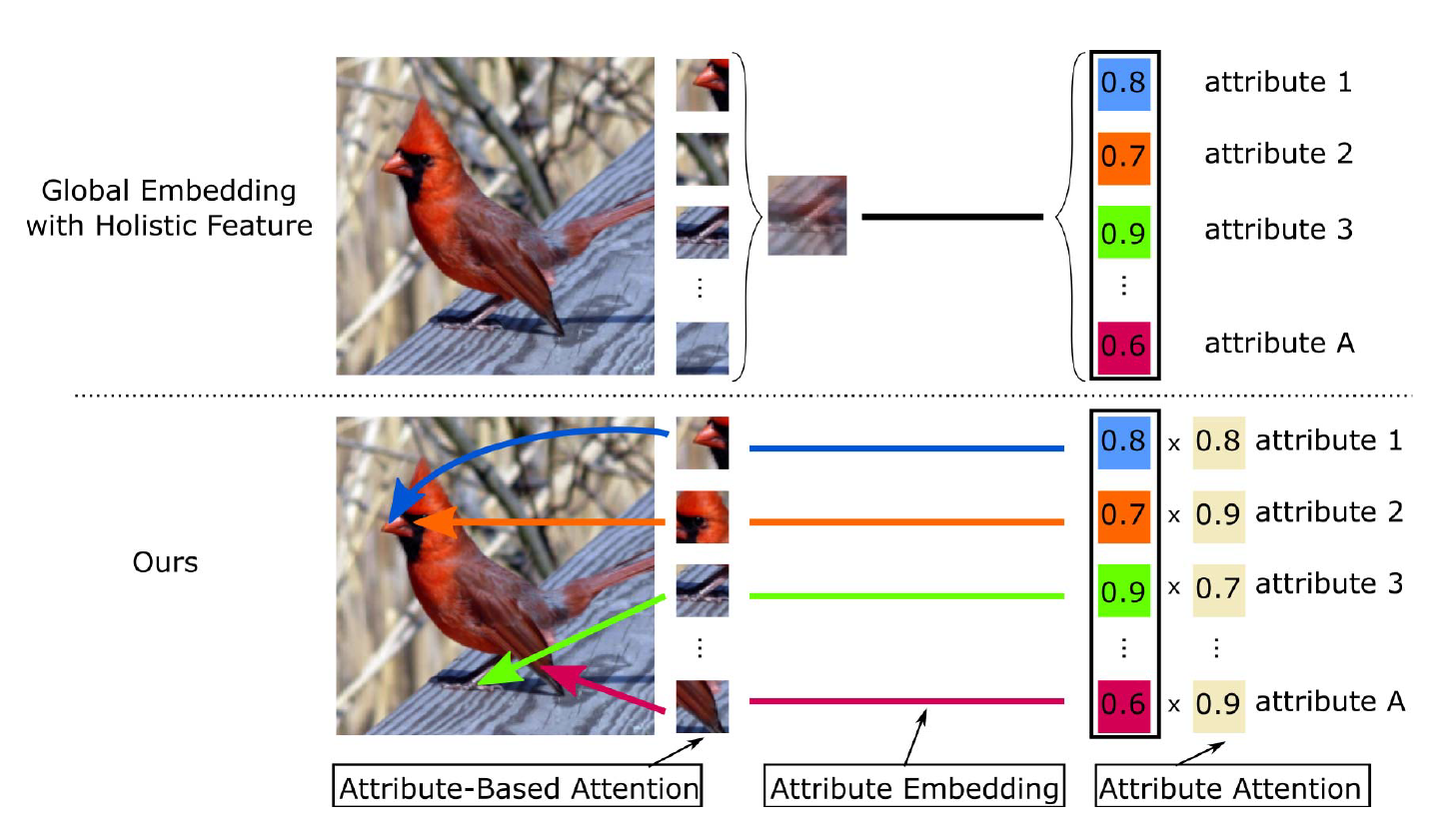
方法核心
网络架构
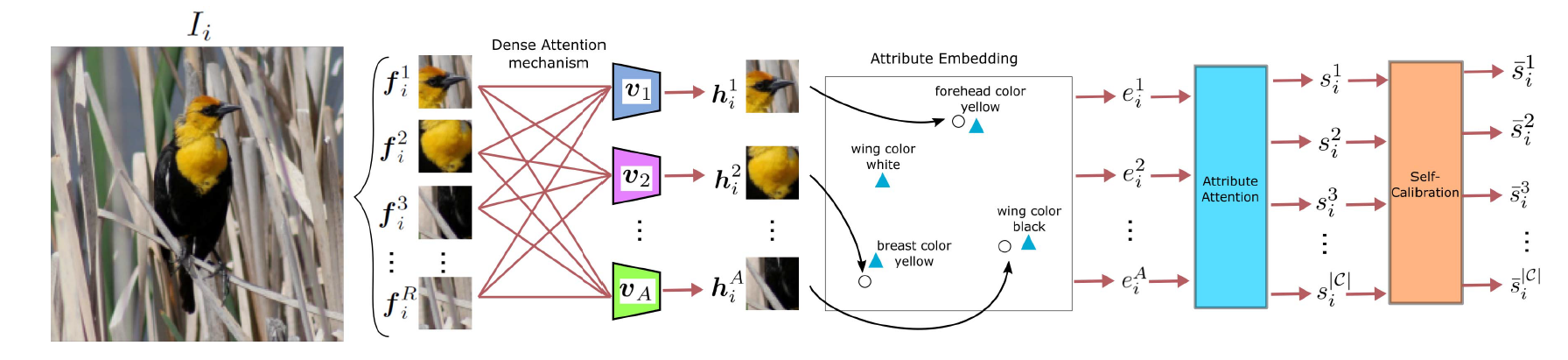
本文提出了密集注意力的零样本学习DenseAttention Zero-shot LEarning(DAZLE)。主要思路是先从图像中找到每个属性最相关的区域后,提取空间注意力特征,然后计算这些图像特征和所需要查找的属性向量的兼容性分数,并使用这个分数来计算本图属于某个类的分数。
为了更好地学习空间和属性注意力网络,本文提出了一个自校准损失来加强交叉熵损失,提高未知类的概率,防止已知类的预测偏差
属性定位
首先定义描述类的语义属性向量,具体来说是类c具有A个属性的语义向量,每个值表示该类具有第a个属性的分数。
在图像中找到每个属性最相关的区域,这里使用属性语义向量和视觉特征的乘积,再使用softmax输出某一区域特征关于该属性的注意力分数。对于每个属性,将每个区域的注意力分数和其特征向量相乘再求和,得到和这个属性最相关的视觉特征。
当图像中不存在某个属性时,视觉特征会捕获表示不存在这个属性的区域,比如为这个属性分配一个负分,用于表示不存在。
属性嵌入
有了每个属性最相关的特征后,就是要计算对与每个类别的分数,训练的目标就是最大化真实标签的分数,最小化不同标签的分数。在这里,我们不是比较整个类别的分数,而是对真实类别所拥有的的属性进行判断。这里定义属性分数,表示在输入图像中拥有某一属性的视觉特征的置信度。
当输入图像中存在某个真实类别所拥有的属性的视觉特征时,就会将其视觉特征投影到属性语义向量附近。对于每个属性,计算在真实类别中对应属性的强度和视觉特征存在的置信度的乘积的和得到对每个类别的分类分数。比如,某个类别c,具有属性a,我们定义,这时候我们就需要最大化存在该属性的置信度来获得更高的分数。
但是问题是,所有属性都有贡献,而且有时候只有少数属性不同,为了关注更重要的属性,这里需要对最相关的视觉特征进行调整。具体来说,如果相关特征和语义向量不对齐时,直接将该属性的分数置0,对每个属性使用sigmoid函数,这样理想情况下,只有对齐的向量得分为1,其余得分都为0。
损失函数
在仅包含已知类的训练图像上优化交叉熵会导致损失偏向于已知类,这样会导致模型在见到未知类的时候,仍会倾向于输出给已知类更高的概率,从而无法很好地处理在未知类数据。
为此,本文提出了校准损失,允许训练期间将一些预测概率从已知类转移到未知类,最简单的方法就是将所有未知类的预测概率加起来,按照未知类的正确概率值为1附加交叉熵损失。但是这样会导致在预测已知类的时候增加了未知类的分数。于是,为了保证未知类非零预测,同时保持其分数较低,这里使用边距函数来增加未知类的分数,减少已知类的分数。就是如果是已知类,将其上面提到的类别得分-1,再计算softmax概率,再计算未知类样本的交叉熵,如果是未知类,就将其类别得分+1。
总损失就是交叉熵校准损失
在预测时,选择类别分数最大的类作为最后的预测结果,不过这个类别分数也要加上上文提到的边界函数,即已知类-1分,未知类+1分
实验
数据集
因为主要是指针对零样本训练进行优化,所以在鸟、AWA2、SUN数据集训练,为了进一步证明有效性,作者还在DeepFashion数据集上训练,规模是上述数据集的8倍,同时拥有1000个属性,很适合用来验证本文的方法
作者将数据集中的一部分类别划分为未知类,这需要网络自行判断是否属于已知类
评估标准
传统的零样本学习
广义的零样本学习
测试图像同时包含已知类和未知类,然后评估已知类和未知类的精度,为了平衡已知类和未知类的权重,这里计算调和平均值
实验结果
传统零样本学习
首先在视觉差异很小的鸟数据集上测试了零样本性能,分割已知未知样本时也有标准分割和提议分割的方法,标准分割导致一些类别出现在ImageNet中,通常精度比提议分割要好。
在标准分割上,本文的方法比传统方法相比,至少有5.8%的提升,而且和使用了部件边界框的S2GA模型相比,略微低了不到1%,充分证明了本方法在捕获注意力的有效性,可以无需昂贵的判别性部件的注释也可以达到相似的水平。
在提议分割上,本文的方法优于过去所有零样本学习的模型,至少领先了4.9%,达到了65.9%的精度,特别是和目前先进的方法相比,他们缺少了融合图像局部判别区域的能力。同时,应用了自校准损失可以比不应用至少提高了3.6%的精度
广义零样本学习
在广义零样本学习上,本方法很好的很好的提高了未知类的分类精度,表明了密集注意力机制仅关注可变属性,而不是整体视觉特征,从而保证了未知类的有效性。
然而,在没有自校准损失的情况下,本方法的精度比较低,尤其是和一些生成特征的方法相比。使用了校准损失后,在鸟和AWA2数据集上调和平均精度和其他方法相比高了5.1%,4.5%,而在SUN数据集低于其他方法,主要是因为已知类别只有16个,无法很好的提取属性
消融实验
同时应用交叉熵和自适应损失,在DeepFashion数据集上调和精度提高了1.5%,同时,如果固定属性的语义向量,精度下降了1.9%,表明了语义属性也需要不断更新
同时,针对属性的数量进行实验,如果一个属性出现在每个类别中,那没就是无判别力的,如果只出现在一个类中,则是有判别力的。通过动态加权每个属性的重要性,本方法的精度进一步提高了1.3%
可视化
通过可视化鸟数据集上的注意力分布发现,本模型也可以在只有图像级标签的情况下获得细粒度的属性分类,同时可以正确的为不存在的属性赋予负分数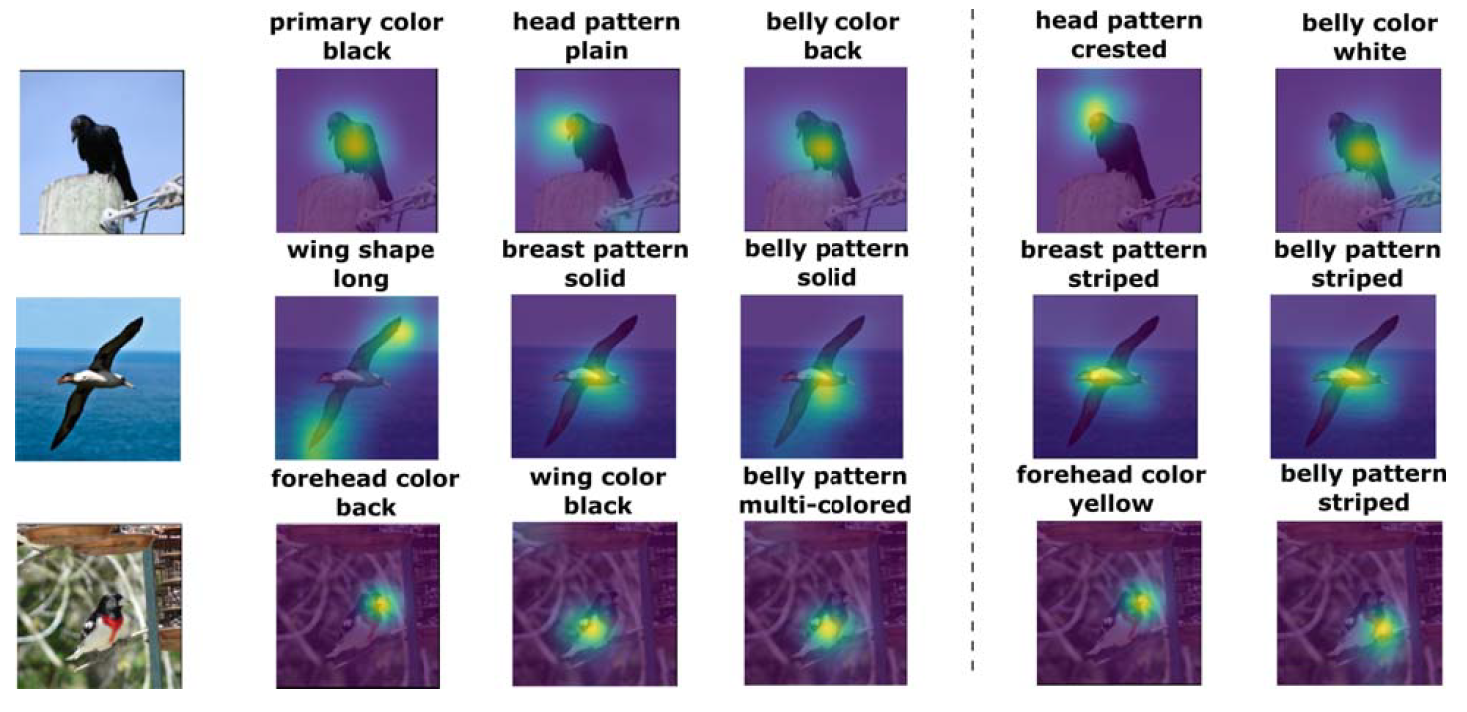
总结
本文尝试使用各个属性的存在与否判断细粒度图像的分类情况,这样的方法可以很好的判别那些没有出现过的类别,理论上来说,假如有100个属性,并且每个属性是同等重要的,那么可以判别个类别,本文为细粒度图像分类开辟了新的赛道,而且目前的相关研究较少,零样本识别的精度普遍不高,还有很广阔的突破空间。
本文提出的针对不可见样本的补偿值得参考,对其最终的类别得分进行简单的相加,但是对精度却有着很大的影响,同时作者提出了调和平均精度,这个新的判别标准对于本文专注于处理未知类是很有利的做法。这种新的评判标准有助于得到更好的实验结果。
本文最后计算每个属性的熵,由此来判别每个属性的重要性,我认为这个方法非常有参考价值,只有个别类别特有的属性才有更高的价值,可以尝试将其应用到未来的方法中。

若有收获,就点个赞吧
0 人点赞
