大规模时空数据分析 - IEEE VIS 2018 Best paper 解读
拜读了 IEEE VIS 2018 的 Best paper,TPFlow: Progressive Partition and Multidimensional Pattern Extraction for Large-Scale Spatio-Temporal Data Analysis。这是一篇 Vast (可视分析)。
在多维地理-时序(ST)数据集上,一个数值的度量是由对应时序、地点、其他维度信息决定的。传统的方法是通过使用在多坐标系视图中进行交互可视化,从而交互这种数据集。多坐标系视图中的每个视图展示一个或两个维度。通过在视图上进行 brushing 等交互,分析师可以获取小关系信息。然而,这种方法常常不能为分析师分辨在数据子集中隐藏的 pattern 提供高效率的引导。在没有先验设想的情况下,分析师需要手动选择、交互来寻找答案,这样的交互需要在不同的部分进行迭代,这可能会是一个乏味、过长的过程。在这篇文章中,作者将多维度的 ST 数据建模成为张量(tenser,可以理解成多维度的矩阵容器),并且提出了分段一阶张量分解算法,从而提供将数据自动切片到同质的部分并提取、对比、视觉性总结潜在的 pattern。简单来说,就是提供了多维数据的聚类、分析、展示方法。该算法优化了被提取的 pattern 在视觉上表达原始数据的可行度。基于这种算法,作者提出了一个可视分析框架,该框架为 level-of-detail 的多维度 ST 数据探索提供可支持自上而下的、逐步划分的工作流程。
以一个德国各区域、各时间销售商品的数据为例。首先分析领域专家希望看到什么信息(用户任务)。作者通过调研,发现专家对发展更好的市场策略的三个方面感兴趣:1. 商品的分类,区分在时间和地域上分布相似的商品,从而寻找将商品交叉绑定销售的可能性。2. 时序对比,对比不同商品在选定的时间区间的销售情况。3. 市场分割,将行政区域根据相同的特性划分成小组,例如对一系列商品的共同需求,或销售相似的时序变化。
下图(图1)视图 a 中的流图是用户从根节点通过交互(右击菜单如 a4)选择分类维度、类数得到逐层分类结果。通过多选流图上的节点(粉、绿、橙、蓝),得到 b 、c 、d 视图中的对比。b 中的多个柱状图展示了不同商品分类在不同时间的销售情况,c 折线图也同样展示了上述信息。d 中但地图上每个行政区都带有一个 donut chart,大小代表了销售量,可以看出本次商品分类方法是根据地域划分的(与用户在 a5 中选择的 state 对应)。

图 1
图 2
【任务1:商品分类】(图 2) a 中大量深蓝色代表了全部商品中有一大部分的变化量(variations)不大,对应 a1 中柱状图尾部的 error bar。【交互1】当用户选定了 b 中的几个节点,这几个分类被赋以绿、橙、蓝、粉四个颜色,b1 中出现了对应的带有 error bar 的柱状图、带有浮动范围的折线图、带有donut chart 和 error bar 的地图。在 b1 中的粉色部分的 error bar 发现这部分的各个维度变化量不大,说明该类商品在时间和地域上的销售情况相似。在折线图的 b3 中可以发现,蓝色类商品(仅包含一种商品)在 2015 年销售量骤降为0,而橙色类的商品(包含两种商品)从 2015 年开始突破 0 销售。【交互2】因此用户选择了橙色再进行划分得到 c 中两个部分,被赋予绿色和橙色,对应得到 c1 折线图及其右侧的地图,可以发现绿色类商品在德国北部几个州的销售量远大于橙色。
【任务2:时序对比】(图 2)当用户再一次在流图上交互,选择了 d 的上级通过时间将其分类了两个类,它们被赋为橙和绿,在 d3 地图上可以发现每个区域对绿、橙两个时间段商品的需求量不同。
【任务2:市场分割】(图1)用户将 a 的最右侧节点通过 state 分类为 4 种商品,被赋予粉、绿、橙、蓝。d 中展示了根据地域的分组信息。在折线图 c1 中可以发现,在非粉色的区域中,月销售趋势相似。然而,粉色的行政区域基本上位于德国东北部,与其他行政区域的行为不同。特别是粉色商品在折线图的 c2 部分表现出了在 6 月份出现了销售巅峰,与 b1 柱状图对应。
思考
该论文大量篇幅在描述张量建模和分段一阶张量分解算法,并不是单纯设计开发了一个可视化交互界面。我想,它能够成为可视化顶会的最佳论文,其原因不仅仅是一个可视化界面,而是根据特定场景和数据设计的完备算法、可视化、交互、分析链路,完全贴合用户需求。因此,一个好的可视分析框架的核心仍然是优秀的核心算法和对用户行为的透彻解析。该文章总共描述了 3 个场景在该框架中的应用,上面我只列举了其中一个。文章还提到曾对某个场景进行了长达 8 个月的调研和观察。只有对用户期待、任务、行为有了深刻的分析和理解,才能够设计出贴合场景、数据需求、用户需求的可视分析工作流。
by @十吾(shiwu-5wap2)
TorFlow
将图数据、地理空间及时序结合起来进行可视化,实时地探索分析不同区域,不同时间段内的数据,听起来是不是很吸引人。
TorFlow就是这样一款软件,将数据渲染到地理空间中,支持实时修改节点透明度、修改节点大小、渲染的节点数量、Label的样式等,点击各个区域,会以统计数据的形式展示具体数据情况。通过底部的时间选择器,可以筛选某一时间进行分析。
地理空间、图数据、统计信息及时间范围上的所有的操作都是相互联动的,通过这种联动操作,用户可以很方便地筛选到需要的数据,分析出数据之间的关联关系。
by @聚则(moyee-bzn)
帮助视障用户、机器人理解可视化
可视化这门学科是建立在人类视觉获取信息的占比高达 95% 的基础之上,可视化的目的也是增强人体视觉获取信息的效率。那么对于视障用户、或者机器人如何去理解可视化?
论文《Visualizing for the Non-Visual: Enabling the Visually Impaired
to Use Visualization》提出了一种基于深度神经网络的方法,自动识别可视化中的关键元素,包括可视化类型、图形元素、标签、图例,以及最重要的可视化中传递的原始数据,我们利用这些提取的信息为视障人士提供提取信息的阅读。
对于可视化组件库来说,其本身可以拿到所有的数据,如果能提供对应的 visual accessibility API,可以大大提升数据提取准确率,对于视障用户,或者机器人爬虫,更加友好。
by @逍为(hustcc)
当历史和艺术碰上可视化
最近发现上海博物馆的一些网上展览用到了可视化。当历史和艺术碰上可视化,诞下了一些有意思的作品。这里主要介绍两个展览中出现的可视化作品。
在“丹青宝筏:董其昌书画艺术大展”中,可以探索董其昌先生的生平和交游。点开生平之后,可以看到如下图所示的一张视图。
整个视图基于时间轴绘制。最上方用红色代表书法,青色代表绘画,反映了他创造这两种艺术作品的数量随时间的变化。我们从中间的时间轴上可以看到董其昌先生一生中发生的重要事件,以及与之发生在相同时间的明朝和欧洲的大事。此外,一些交互操作也被应用到这个视图中。比如,点击各种事件查看详情,点击年龄查看当年详情,点击年份查看年龄等。
他的交游情况则通过关系图展示出来。
在“遗我双鲤鱼”中,也有对吴门书画家书信往来关系的可视化。
相关链接:上海博物馆网上展览
by @珂甫(pddpd)
嵌入式交互
用于数据可视化的用户界面通常包括两个主要组件:用于用户交互的控制面板和可视化表示面板。最近的可视化趋势是将用户交互直接嵌入到可视化表示中。 例如,代替使用控制面板来调整可视化参数,用户可以直接调整基本图形编码(如改变散点图中的点之间的距离)来执行类似的参数化。
这种嵌入式交互有以下明显的优点:无需将注意力从视觉特征上转移;显著缩短交互时间;与心理模型的一致性(所思所见既所得)。数据可视化启用嵌入式交互需要深入了解用户交互如何影响准确控制和感知图形编码的能力,TVCG2017的文章 Evaluating Interactive Graphical Encodings for Data Visualization 研究了12种常见的图形编码在作为交互方法时的有效性。
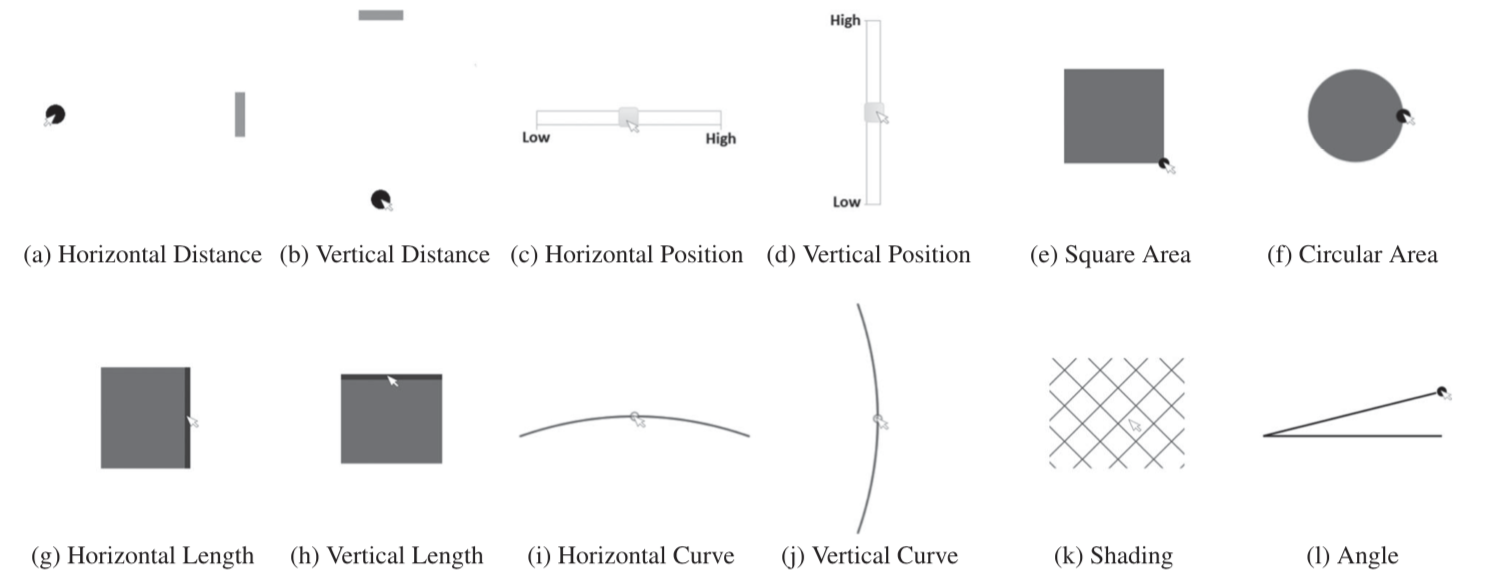
文章的一些实验结论可以运用到交互设计中。例如,距离、位置、长度和角度这些图形编码具有高精度,可以在设计交互中加入;而一些低精度的编码,需要给用户提供一些额外的反馈信息来提升交互的准确性。
在另外一篇infoVis 18年的文章Embedded Merge & Split Visual Adjustment of Data Grouping ,设计了一套直观简便的嵌入式交互,用于进行统计直方图或柱状图的调整,包括合并,分割,和改变柱子数量。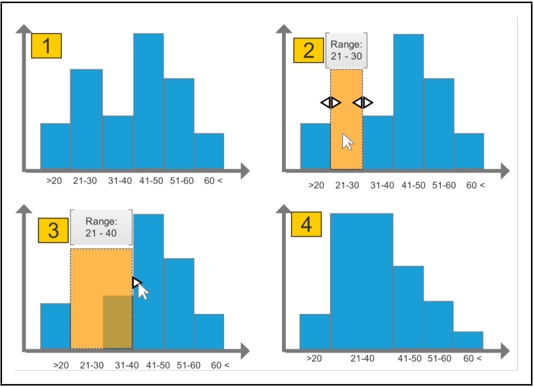
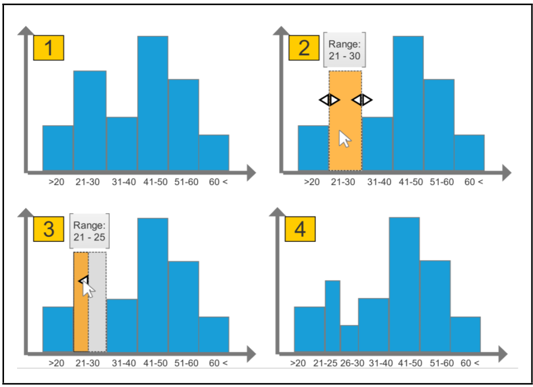
通过实验定量分析发现,与Tableau相对比,这种方法在时间和准确性上都有显著增强。所以在进行交互设计时,可以考虑加入一些精心设计的嵌入式交互来增强用户体验。
by @顾己(esora)
Webapck bundle可视化
前端工程化构建后,业务中经常遇到需要分析模块之间引用关系。于是调研了几种webpack bundle可视化的工具。
webapck bundle analyzer:用树图(treemap)可视化,可以看到import了哪些模块,以及每个模块的大小(size),但是看不到模块之间的引用关系。

webpack visualizer:webpack visualizer类似于webpack bundle analyzer,只不过使用分层饼图可视化。

webpack analyse:webpack analyse使用node-link图可视化的方式,不能看到每个模块的大小,但是可以看到模块之间的引用关系(通过节点之间的有向边来表示模块的引用关系)。使用了力导布局,但是布局效果不太理想,而且收敛速度有点慢。
汉字星球
我们根据视觉相似度绘制了8,615个汉字(hànzì)。 通过“拼音”拼写搜索字符,通过缩放到具有相似外观字符的群集来探索地图。 选择一个文字后,发音相同汉字都会也突出显示,以展示中文书写系统的复杂性。在线demo
主要采用结构相似性指数算法文本聚类,力导向布局。结构相似性聚类方法在处理非常简单的字符子集(写入的笔划数量较少)或非常复杂(大量笔划)时具有局限性。文字被聚集到一个大类中,但是彼此之间没有明显的关系。
上图可以看到口字旁的文字聚合在了一起,发音 han的字符突出显示。
by @ThinkGIS(xiaofengcanyue)

若有收获,就点个赞吧
0 人点赞
