InnoDB 是如何存储数据的?
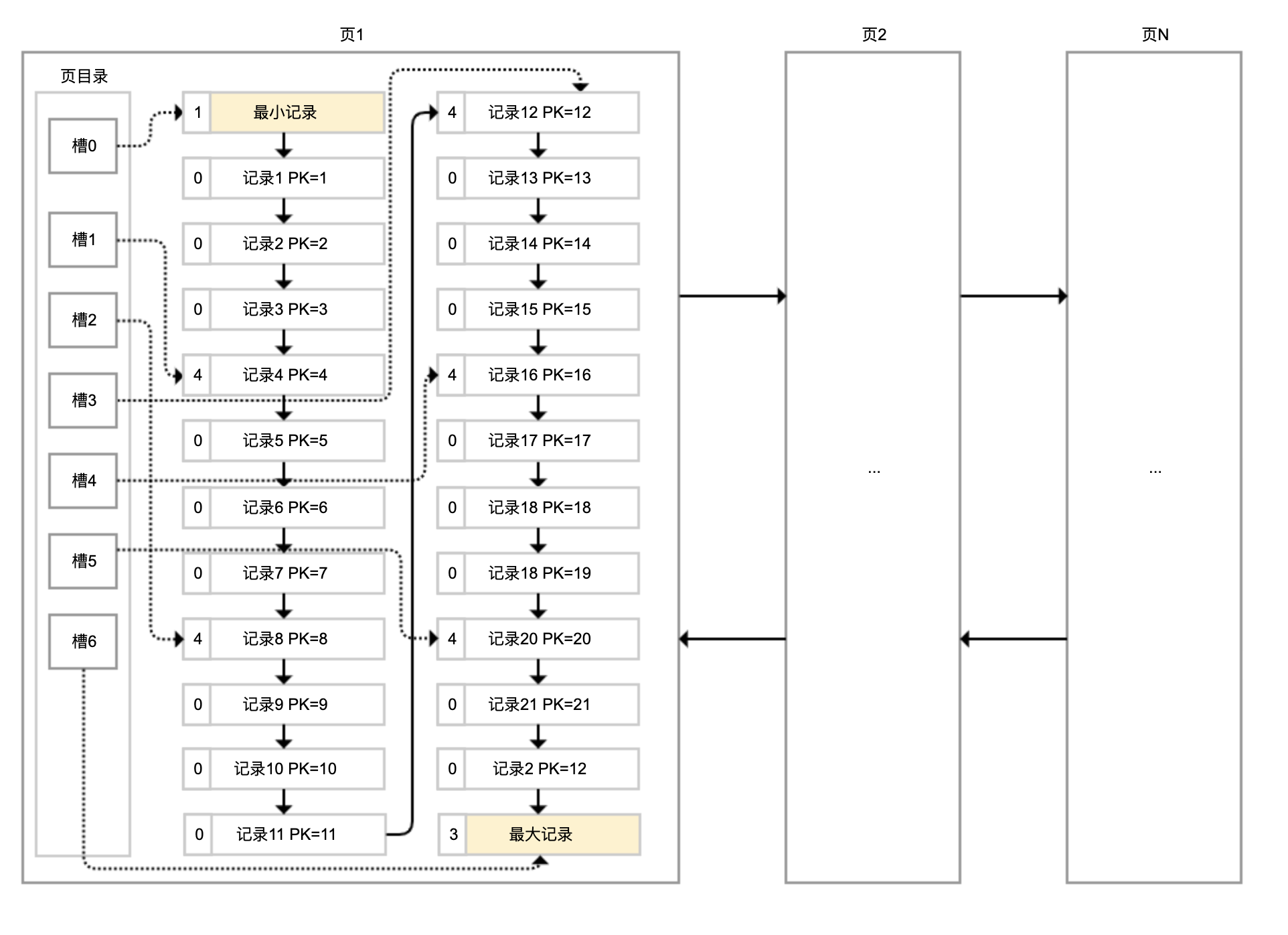
简化的InnoDB存储结构
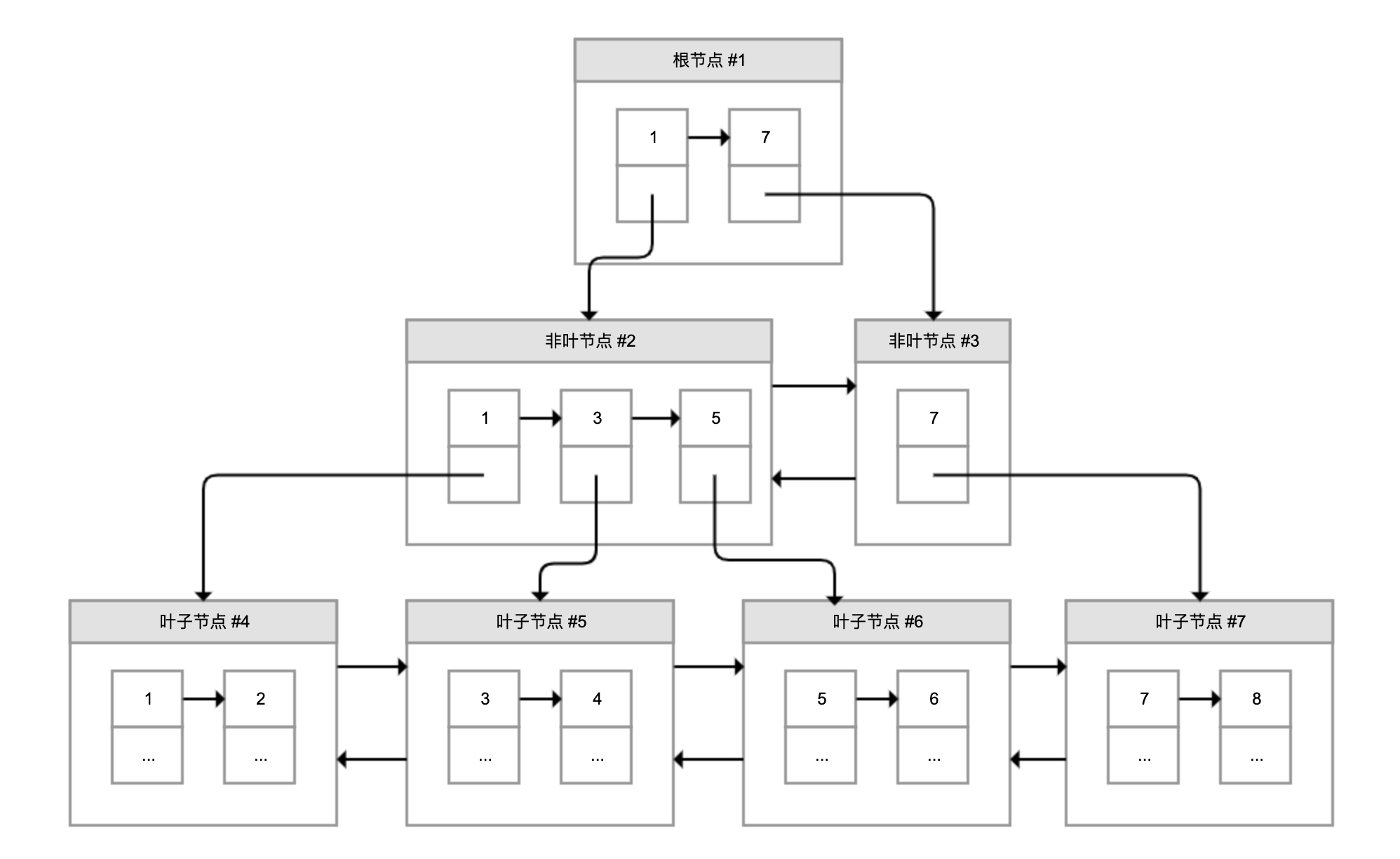
含有B+树的InnoDB存储结构(即聚簇索引)
B+ 树的特点包括:
- 最底层的节点叫作叶子节点,用来存放数据;
- 其他上层节点叫作非叶子节点,仅用来存放目录项,作为索引;
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
- 所有节点按照索引键大小排序,构成一个双向链表,加速范围查找。
InnoDB 会自动使用主键(唯一定义一条记录的单个或多个字段)作为聚簇索引的索引键(如果没有主键,就选择第一个不包含 NULL 值的唯一列)。上图方框中的数字代表了索引键的值,对聚簇索引而言一般就是主键。
为了实现非主键字段的快速搜索,就引出了二级索引,也叫作非聚簇索引、辅助索引。
考虑额外创建二级索引的代价
- 首先是维护代价。创建 N 个二级索引,就需要再创建 N 棵 B+ 树,新增数据时不仅要修改聚簇索引,还需要修改这 N 个二级索引。
- 其次是空间代价。虽然二级索引不保存原始数据,但要保存索引列的数据,所以会占用更多的空间。
- 最后是回表的代价。二级索引不保存原始数据,通过索引找到主键后需要再查询聚簇索引,才能得到我们要的数据。
关于索引开销的最佳实践吧。
- 第一,无需一开始就建立索引,可以等到业务场景明确后,或者是数据量超过 1 万、查询变慢后,再针对需要查询、排序或分组的字段创建索引。创建索引后可以使用 EXPLAIN 命令,确认查询是否可以使用索引。
- 第二,尽量索引轻量级的字段,比如能索引 int 字段就不要索引 varchar 字段。索引字段也可以是部分前缀,在创建的时候指定字段索引长度。针对长文本的搜索,可以考虑使用 Elasticsearch 等专门用于文本搜索的索引数据库。
第三,尽量不要在 SQL 语句中 SELECT *,而是 SELECT 必要的字段,甚至可以考虑使用联合索引来包含我们要搜索的字段,既能实现索引加速,又可以避免回表的开销。
不是所有针对索引列的查询都能用上索引
索引只能匹配列前缀
SELECT * FROM person WHERE NAME LIKE '%name123' LIMIT 100前缀模糊匹配,会是全表扫描,不走索引
- 条件涉及函数操作无法走索引
- SELECT * FROM person WHERE LENGTH(NAME)=7
- 联合索引只能匹配左边的列。
- 也就是说,虽然对 name 和 score 建了联合索引,但是仅按照 score 列搜索无法走索引
- 需要注意的是,因为有查询优化器,所以 name 作为 WHERE 子句的第几个条件并不是很重要。
数据库基于成本决定是否走索引
其实,MySQL 在查询数据之前,会先对可能的方案做执行计划,然后依据成本决定走哪个执行计划。这里的成本,包括 IO 成本和 CPU 成本:
- IO 成本,是从磁盘把数据加载到内存的成本。默认情况下,读取数据页的 IO 成本常数是 1(也就是读取 1 个页成本是 1)。
- CPU 成本,是检测数据是否满足条件和排序等 CPU 操作的成本。默认情况下,检测记录的成本是 0.2。
MySQL 选择索引,并不是按照 WHERE 条件中列的顺序进行的;
即便列有索引,甚至有多个可能的索引方案,MySQL 也可能不走索引。
在 MySQL 5.6 及之后的版本中,我们可以使用 optimizer trace 功能查看优化器生成执行计划的整个过程。有了这个功能,我们不仅可以了解优化器的选择过程,更可以了解每一个执行环节的成本,然后依靠这些信息进一步优化查询。
思考总结
索引除了可以用于加速搜索外,还可以在排序时发挥作用,你能通过 EXPLAIN 来证明吗?你知道,在什么情况下针对排序索引会失效吗?
SQL中带order by且执行计划中Extra 这个字段中有”Using index”或者”Using index condition”表示用到索引,并且不用专门排序,因为索引本身就是有序的;
如果Extra有“Using filesort”表示的就是需要排序;排序时:MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。sort_buffer_size(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
上述排序中,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。 但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
所以如果单行很大,这个方法效率不够好。
max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。称为 rowid 排序;rowid排序简单的描述就是先取出ID和排序字段进行排序,排序结束后,用ID回表去查询select中出现的其他字段,多了一次回表操作,
对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。

若有收获,就点个赞吧
0 人点赞
