State
- 有些算子只处理当前时刻的某一条记录
- 有些别的算子需要记录多个记录间的信息,这些operation是就被称为stateful
- flink需要对state有感知和处理,以通过checkpoint和savepoints实现容错性
- Queryable State
Keyed State
- Keyed State is further organized into so-called Key Groups.
- Key Groups are the atomic unit by which Flink can redistribute Keyed State;
- there are exactly as many Key Groups as the defined maximum parallelism. 【Group和最大并行度一样多】
- During execution each parallel instance of a keyed operator works with the keys for one or more Key Groups.
State Persistence
- flink实现容错
- stream replay
- checkpoint
- The checkpoint interval is a means of trading off the overhead of fault tolerance during execution with the recovery time (the number of records that need to be replayed).
- 即检查点间隔的设定,需要在容错开销和恢复时间时间找平衡点
- 间隔大,容错开销小,但是恢复时间长
- 间隔小,容错开销大,但是恢复时间少
- 默认情况下,checkpoint是关闭的
- 容错保证(Fault Tolerance Guarantees) 与数据源也有关,要求 data stream source 支持数据流的rewind(即调整读取点?)
CheckPointing
Barrier
- Chandy-Lamport algorithm for distributed snapshots
- 基于检查点的容错是Flink的关键特征之一,正式基于这样的设计,Flink才可以统一批流处理。Flink 容错机制的核心就是持续创建分布式数据流及其状态的一致快照。这些快照在系统遇到故障时,充当可以回退的一致性检查点(checkpoint)
- 分布式快照引入了数据栅栏(barrier)的概念,barrier 被插入到数据流中,作为数据流的一部分和数据一起向下流动。Barrier 不会干扰正常数据,数据流严格有序。一个 barrier 把数据流分割成两部分:一部分进入到当前快照,另一部分进入下一个快照。每一个 barrier 都带有快照 ID,并且 barrier 之前的数据都进入了此快照。Barrier 不会干扰数据流处理,所以非常轻量。多个不同快照的多个 barrier 会在流中同时出现,即多个快照可能同时创建。
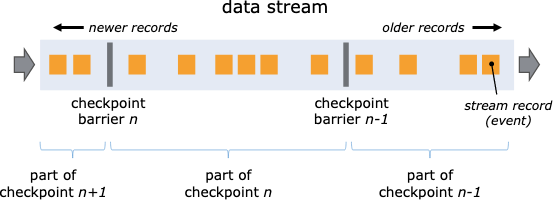
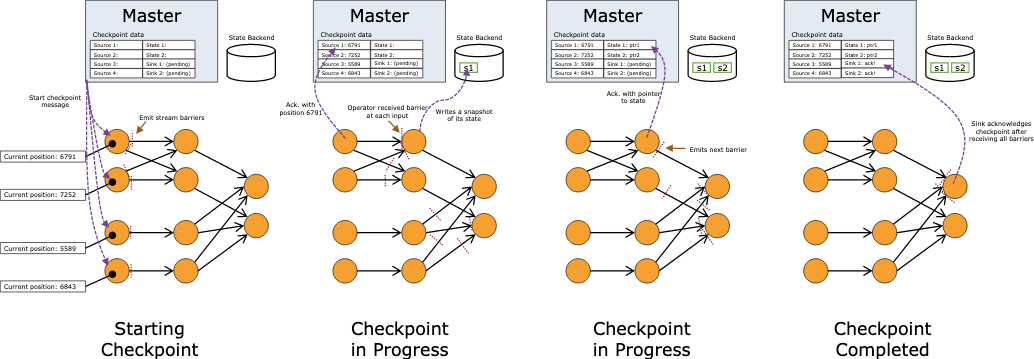
Barrier 在数据源端插入,当 snapshot n 的 barrier 插入后,系统会记录当前 snapshot 位置值 n (用Sn表示)。例如,在 Apache Kafka 中,这个变量表示某个分区中最后一条数据的偏移量。这个位置值 Sn 会被发送到一个称为 checkpoint coordinator 的模块。
然后 barrier 继续往下流动,当一个 operator 从其输入流接收到所有标识 snapshot n 的 barrier 时,它会向其所有输出流插入一个标识 snapshot n 的 barrier。当 sink operator (DAG 流的终点)从其输入流接收到所有 barrier n 时,它向 the checkpoint coordinator 确认 snapshot n 已完成。当所有 sink 都确认了这个快照,快照就被标识为完成。
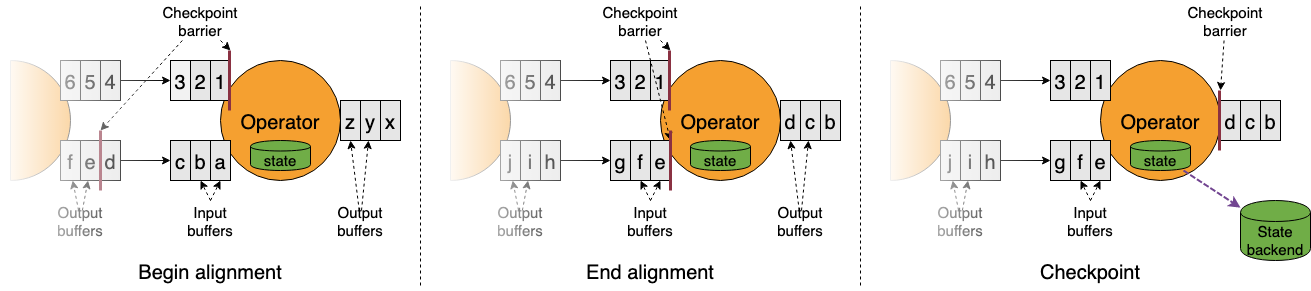
接收超过一个输入流的 operator 需要基于 barrier 对齐(align)输入。参见上图:
- operator 只要一接收到某个输入流的 barrier n,它就不能继续处理此数据流后续的数据,直到 operator 接收到其余流的 barrier n。否则会将属于 snapshot n 的数据和 snapshot n+1的搞混
- barrier n 所属的数据流先不处理,从这些数据流中接收到的数据被放入接收缓存里(input buffer)
- 当从最后一个流中提取到 barrier n 时,operator 会发射出所有等待向后发送的数据,然后发射snapshot n 所属的 barrier
- 经过以上步骤,operator 恢复所有输入流数据的处理,优先处理输入缓存中的数据
Snapshotting Operator State
- state也要作为shapshot的一部分
- state快照的时机:已经接受到输入流的所有barrier后,还没有发射输出流的barrier
- state快照的存储:一般在JobManager的内存中,生产环境下可以配置在特定的storage backend
- 目前来看我们的快照包括
- 对于每一个stream,stream中快照开始的地址(offset或者是position)
- 对于每一个operator,state存储的指针(pointer)
Recovery
- 全量快照:rewind to checkpoint k
-
Unaligned Checkpointing
之前说的都是aligned checkpoint
- unaligned 是flink1.1.1新推出的
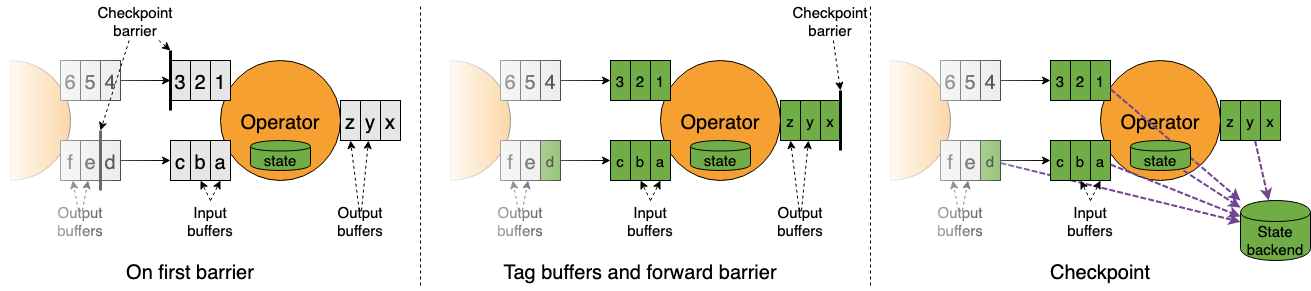
- 好处:
- 保证barriers尽量到达sink
- 对于有一些 slow moving data path的任务很有效(其alignment时间可以达到数小时)
- 不足:
- 会增加额外的IO压力
- 对于IO瓶颈的任务没有帮助
-
State Backend
in-memory hashmap
- RocksDB as the kv store

Save Point
- 作用:升级程序,或者升级flink集群?
- 是手动触发的checkpoints,依赖于常规的checkpoint机制
- 跟checkpoint的区别
- 由用户触发
- 新的checkpoint出来时不会过期expire
Exactly Once vs. At Least Once
没太懂

若有收获,就点个赞吧
0 人点赞
