- HDFS、parquet等列式存储
- 对更新、随机读写支持不好
- 但是scan性能比较好
- Hbase、Cassandra等数据库
- 随机读写性能好
- Scan性能不好
- 不支持SQL分析
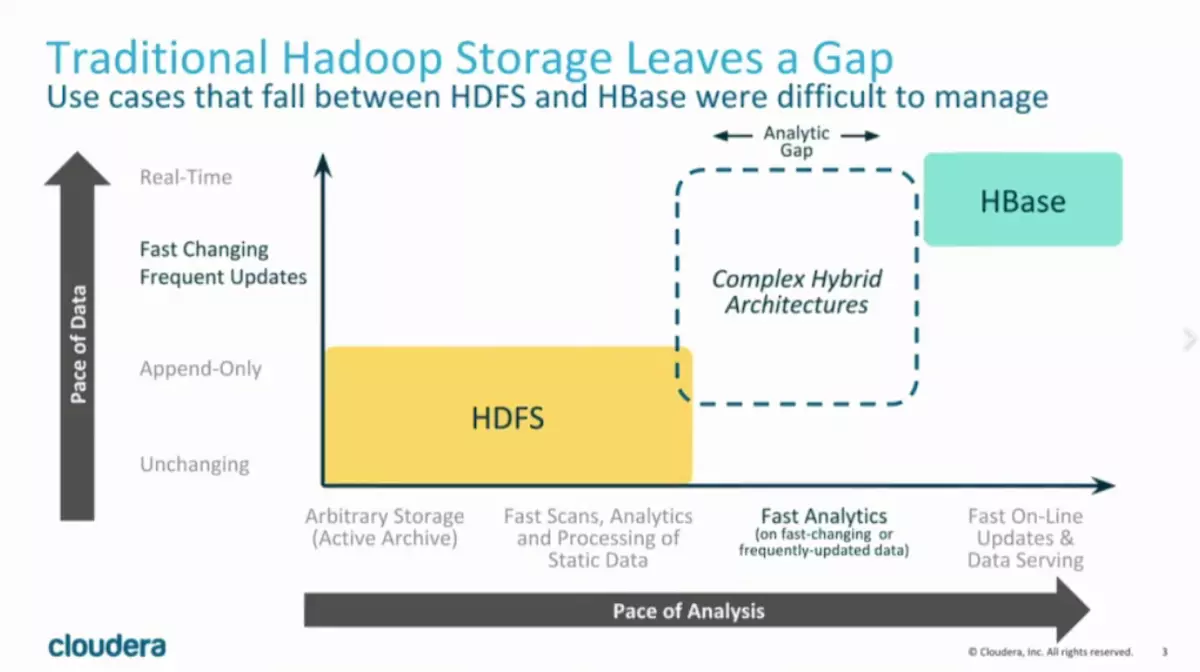
- Kudu: 上面两者的折中点?
- 对数据扫描(scan)和随机访问(random access)同时具有高性能,简化用户复杂的混合架构
- 高 CPU 效率,使用户购买的先进处理器的的花费得到 最大回报
- 高 IO 性能,充分利用先进存储介质
- 支持数据的原地更新,避免额外的数据处理、数据移动
- 支持跨数据中心 replica on
- Kudu使用列式存储,需要预先定义好schema(与Hbase不同)
- 这样的好处是便于编码和压缩
- 使用C++开发
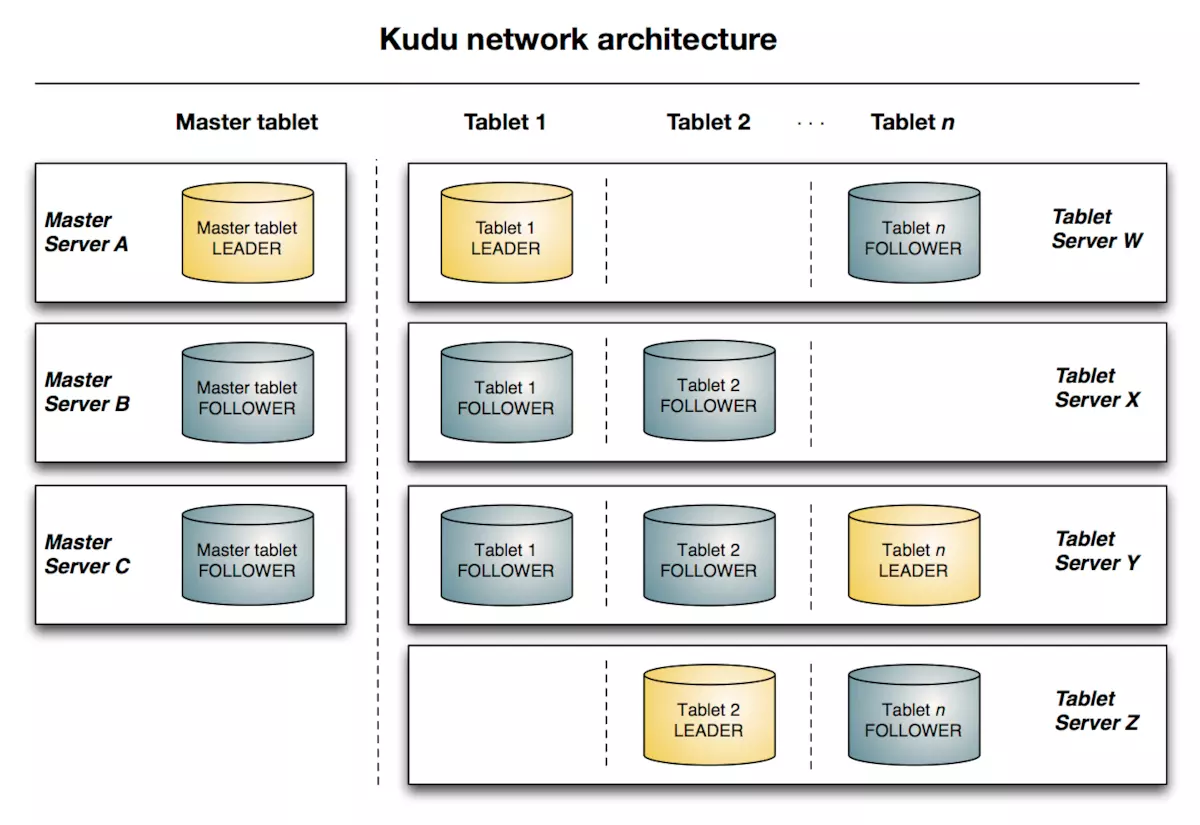
- Kudu splits tables into smaller units called tablets.
- 使用Raft来保证数据一致性
- Kudu实现的是既可以实现数据的快速插入与实时更新,也可以实现数据的快速分析。
- Kudu的定位不是取代HBase,而是以降低写的性能为代价,提高了批量读的性能,使其能够实现快速在线分析。

若有收获,就点个赞吧
0 人点赞
