一条数据的HBase之旅,简明HBase入门教程-开篇
一条数据的HBase之旅,简明HBase入门教程-Write全流程
一条数据的HBase之旅,简明HBase入门教程-Flush与Compaction
一条数据的HBase之旅,简明HBase入门教程-Read全流程
HBase高性能随机查询之道 – HFile原理解析
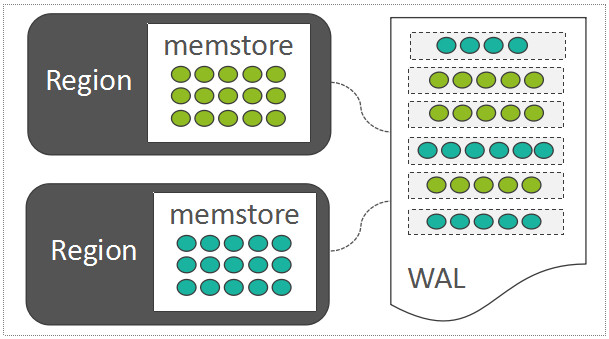
HBase也采用了LSM-Tree的架构设计:
LSM-Tree利用了传统机械硬盘的“顺序读写速度远高于随机读写速度”的特点。随机写入的数据,如果直接去改写每一个Region上的数据文件,那么吞吐量是非常差的。
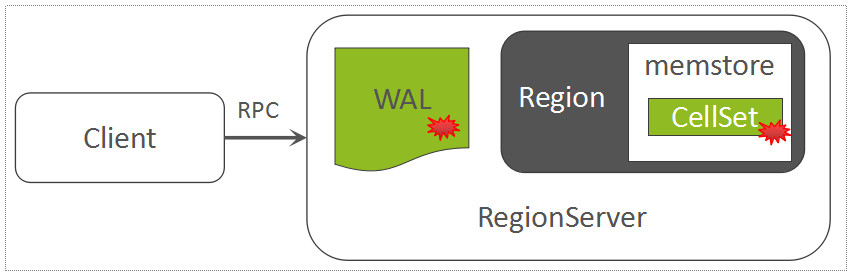
因此,每一个Region中随机写入的数据,都暂时先缓存在内存中(HBase中存放这部分内存数据的模块称之为MemStore;为了保障数据可靠性,将这些随机写入的数据会顺序写入到一个称之为WAL(Write-Ahead-Log)的日志文件中,WAL中的数据按时间顺序组织。
WAL
- WAL(Write-Ahead-Log), 用于保障数据可靠性,默认一个RegionServer有一个WAL
- WAL Roll 当正在写的WAL文件达到一定大小以后,会创建一个新的WAL文件,上一个WAL文件依然需要被保留,因为这个WAL文件中所关联的Region中的数据,尚未被持久化存储,因此,该WAL可能会被用来回放数据。
- WAL Archive 如果一个WAL中所关联的所有的Region中的数据,都已经被持久化存储了,那么,这个WAL文件会被暂时归档到另外一个目录中。注意,这里不是直接将WAL文件删除掉,这是一种稳妥且合理的做法
Multi-WAL Multi-WAL可以在一个RegionServer中同时启动几个WAL Writer,可按照一定的策略,将一个Region与其中某一个WAL Writer绑定,这样可以充分发挥多块盘的性能优势。
MemStore
每一个Column Family,在Region内部被抽象为了一个HStore对象,
- 每一个HStore拥有自身的MemStore,用来缓存一批最近被随机写入的数据,这是LSM-Tree核心设计的一部分。
- MemStore中用来存放所有的KeyValue的数据结构,称之为CellSet
- 而CellSet的核心是一个ConcurrentSkipListMap
- 2.0版本后,Region中的写入顺序是先写WAL再写MemStore
Flush和Compaction
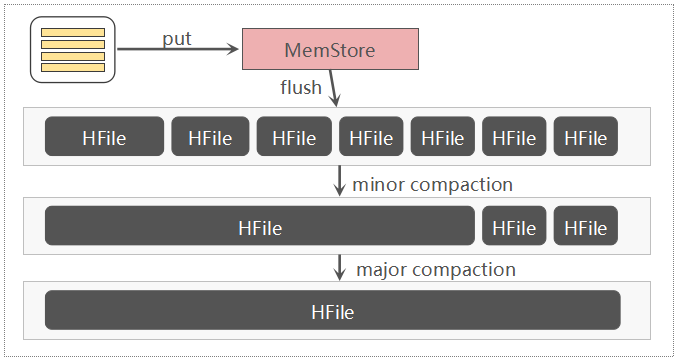
2.0版本以前的flush和compaction流程
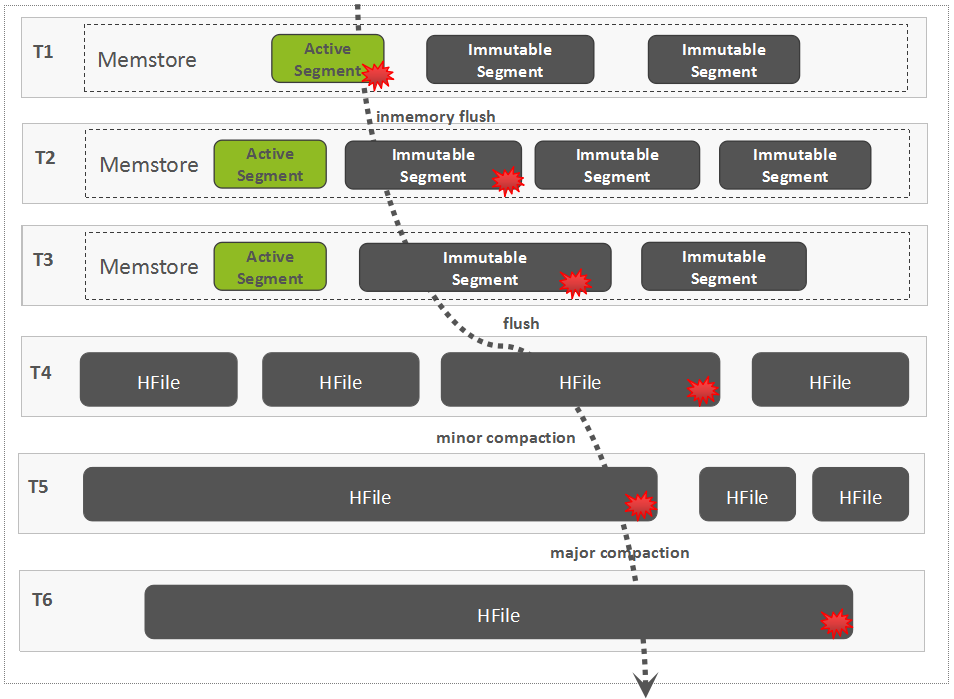
2.0版本后的InMemory Flush和Compaction流程
2.0后默认策略,每一次只Flush超出阈值大小的Column Family,如果都未超出大小,则所有的Column Family都会被Flush。
Compaction 会导致写入放大:随着不断的执行Minor Compaction以及Major Compaction,可以看到,这条数据被反复读取/写入了多次,这是导致写放大的一个关键原因,这里的写放大,涉及到网络IO与磁盘IO,因为数据在HDFS中默认有三个副本
- Compaction的好处:
- 减少HFile文件数量,减少文件句柄数量,降低读取时延
- Major Compaction可以帮助清理集群中不再需要的数据(过期数据,被标记删除的数据,版本数溢出的数据)
存储结构
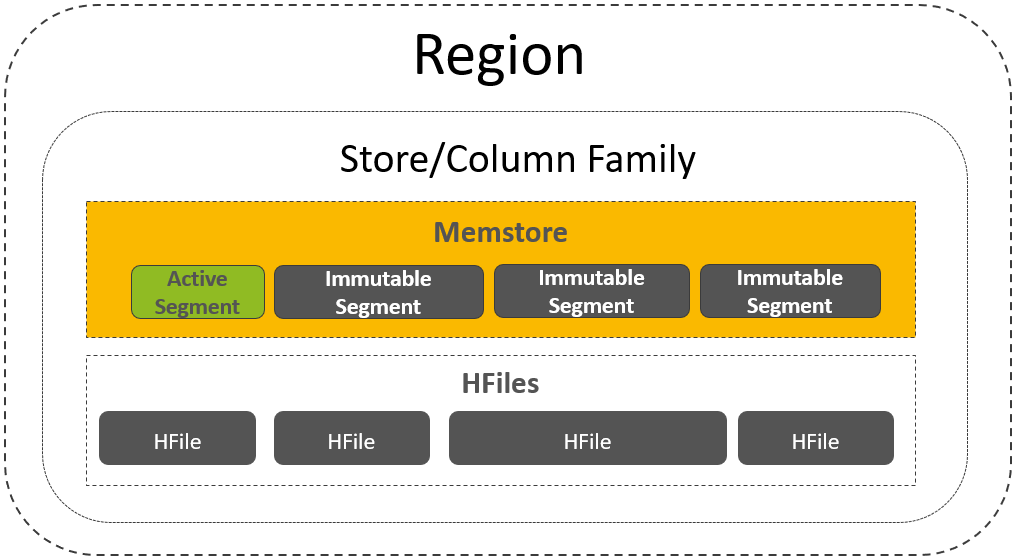
Region中一个CF的存储结构
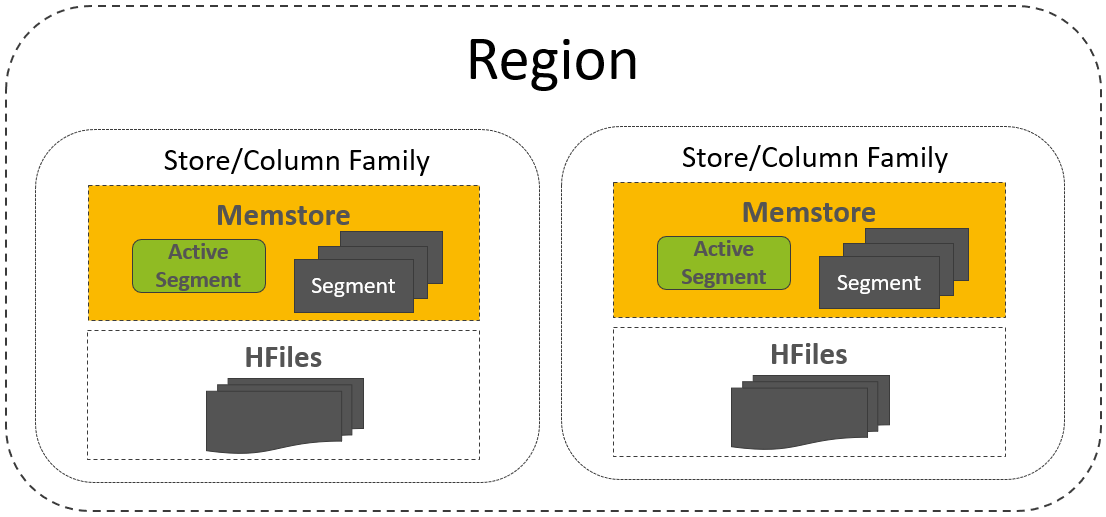
一个Region中支持多个CF(即Store)
- HBase Read的核心问题是:如何从包含1个或多个列族(每个列族包含1个或多个MemStore Segments,以及1个或多个HFiles)的Region中读取用户所期望的数据?默认情况下,这些数据必须是未被标记删除的、未过期的而且是最新版本的数据。
ResultScanner
Client侧使用一个ResultScanner来抽象地描述一次Scan操作,ResultScanner屏蔽掉了往RegionServer发送请求以及一个Region读取完成以后切换到下一个Region等细节信息。
这部分的代码概念较多,流程复杂
待完善
RegionServer侧关于Scan的处理流程:
- 如何用Scanner来抽象描述关于Region的读取操作
- 关于读取KeyValue的基础Scanner接口定义
- RegionScanner初始化时的关键操作
- Client侧的一次次scan请求如何驱动RegionScanner内部的读取操作
- 从StoreFileScanner/SegmentScanner中读取出来的原始KeyValue如何被合理的校验
- Scanner读取时如何跳过一些不必要的数据

若有收获,就点个赞吧
0 人点赞
