Basic
- Transforming HBase into a Relational Database
- Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications(typically Hbase )
- the power of standard SQL and JDBC APIs with full ACID transaction capabilities and
- the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store
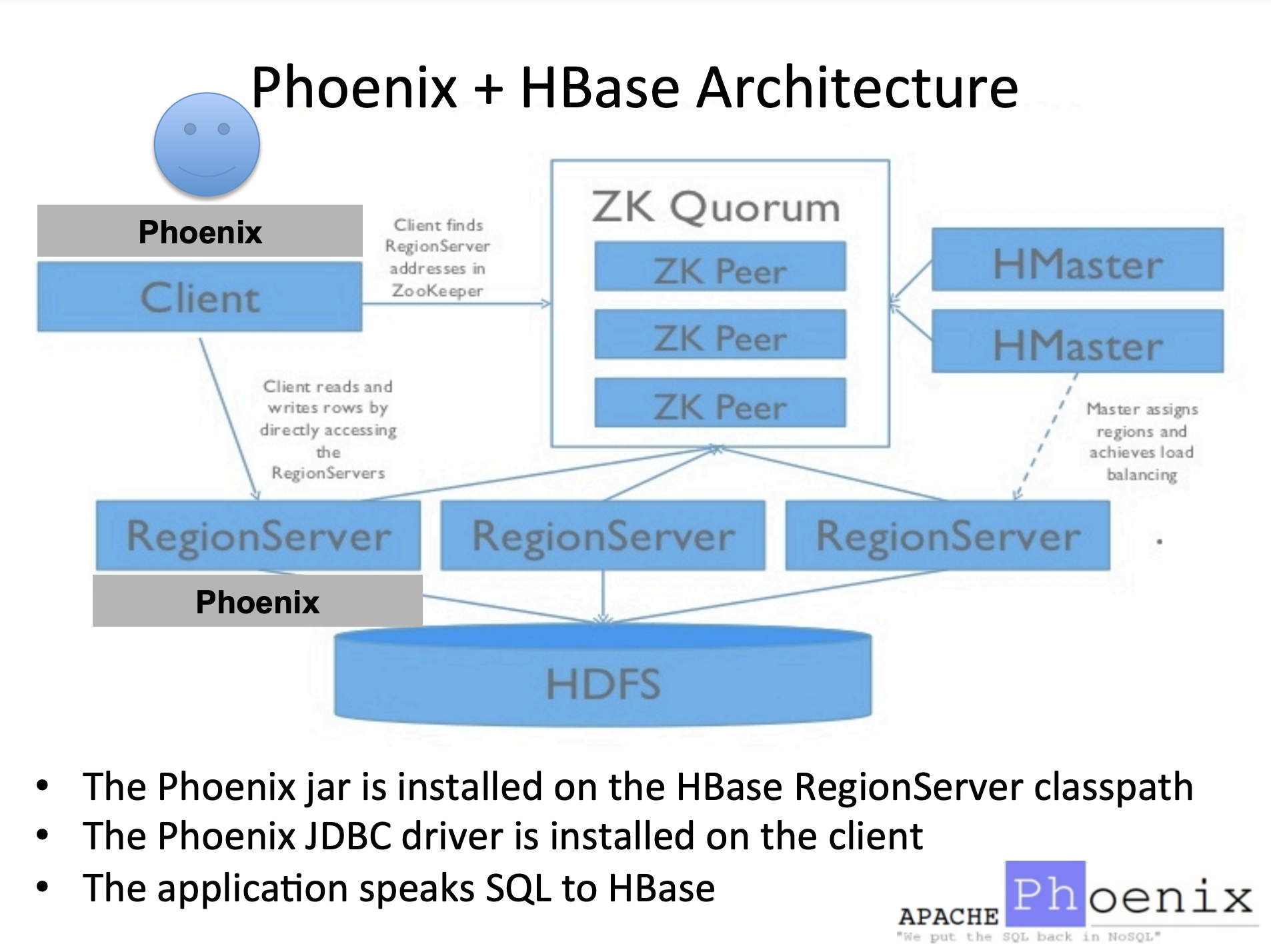
phoenix 没有服务,只需在服务端RegionServer加一个jar包,然后重启habse就好了。 Client这边加一个驱动jar包就可以连接了
Phoenix follows the philosophy of bringing the computation to the data by using:
- coprocessors to perform operations on the server-side thus minimizing client/server data transfer* custom filters to prune data as close to the source as possible In addition, to minimize any startup costs, Phoenix uses native HBase APIs rather than going through the map/reduce framework.
procedure
- compiling your SQL queries to native HBase scans
- determining the optimal start and stop for your scan key
- orchestrating the parallel execution of your scans
- bringing the computation to the data by
- pushing the predicates in your where clause to a server-side filter
executing aggregate queries through server-side hooks (called co-processors)
enhancements
secondary indexes to improve performance for queries on non row key columns
- stats gathering to improve parallelization and guide choices between optimizations
- skip scan filter to optimize IN, LIKE, and OR queries
optional salting of row keys to evenly distribute write load
Spark-Phoenix
Although Spark supports connecting directly to JDBC databases, it’s only able to parallelize queries by partioning on a numeric column. It also requires a known lower bound, upper bound and partition count in order to create split queries.
(貌似只有对数字列的查询才能被并行化?)所以一般spark jdbc读取phoenix,都是一个并发?- In contrast, the phoenix-spark integration is able to leverage the underlying splits provided by Phoenix in order to retrieve and save data across multiple workers. All that’s required is a database URL and a table name. Optional SELECT columns can be given, as well as pushdown predicates for efficient filtering.
Apache Spark Plugin
- The phoenix-spark plugin extends Phoenix’s MapReduce support to allow Spark to load Phoenix tables as DataFrames, and enables persisting them back to Phoenix.

若有收获,就点个赞吧
0 人点赞
