基本概念
索引Index - 数据库
类型Type - 数据表
文档Document -一行表记录
- 节点Node
- 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
- 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
- 协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
- 分片Shard
- 相当于水平分表
- 一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎
- ES实际上就是利用分片来实现分布式。
- 一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
ES写入速度会不会很慢?
答:只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,
可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的
写入流程
- 写入请求到达
- 新文档写入内存In-Memory buffer
- 同时写入一个translog文件(transaction log
- 此时还不能搜索到
- 每1s进行一个
refresh操作,- refresh后,清空内存 -> 数据进入filesystem cache
- 这一秒写入的文档,将构成一个segment
- segment中的数据此时可以搜索到
- 此时尚未入磁盘,断电会丢失
- 每30min左右执行或者tranlog变得很大,执行
fsync(或者称flush操作)- filesystem cache的segment全部写入磁盘(出现commit point概念)
- 删除这段时间的translog
在两次fsync操作之间,存储在内存和文件系统缓存中的文档是不安全的,一旦出现断电这些文档就会丢失。所以ES引入了translog来记录两次fsync之间所有的操作,这样机器从故障中恢复或者重新启动,ES便可以根据translog进行还原。
当然,translog本身也是文件,存在于内存当中,如果发生断电一样会丢失。因此,ES会在每隔5秒时间或是一次写入请求完成后将translog写入磁盘。
可以认为一个对文档的操作一旦写入磁盘便是安全的可以复原的,因此只有在当前操作记录被写入磁盘,ES才会将操作成功的结果返回发送此操作请求的客户端。
- segment的合并
- 由于每一秒就会生成一个新的segment,很快将会有大量的segment。对于一个分片进行查询请求,将会轮流查询分片中的所有segment,这将降低搜索的效率。
- 因此ES会自动启动合并segment的工作,将一部分相似大小的segment合并成一个新的大segment。合并的过程实际上是创建了一个新的segment,当新segment被写入磁盘,所有被合并的旧segment被清除。
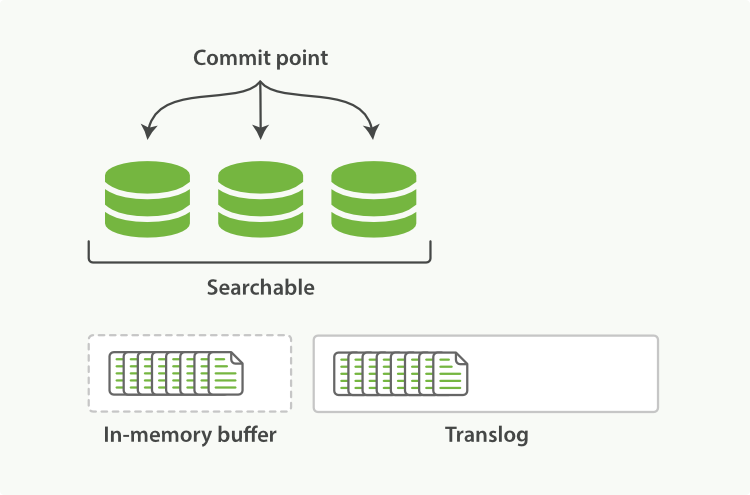
commit point,记录着当前filesystem cache中还没有持久化到磁盘的所有Segment

es写入的几个关键概念 fresh,flush,translog,merge commit
- fresh:In-Memory buffer -> filesystem cache中的segment,每1s执行,此时才开始可以被搜索到,断电会丢失
- flush:filesystem cache -> 磁盘上,translog会被删除
- merge:合并segment
hbase写入的关键流程: flush compation split
- flush : 包括inmemory flush, MemStore->hfile
- compation: 合并hfile
- spit:数据量太大, 拆分region
注意es写入,是先到内存,再到tranlog,与hbase相反
删除流程
- ES的索引是不能修改的,因此更新和删除操作并不是直接在原索引上直接执行
- 删除并不是真删除,是标记删除
- 每个segment中有一个del文件,标记要删除的文档
- 查询时,标记删除的文档,将被过滤
-
更新流程
找到老文档
- 写入新文档
-
查询流程
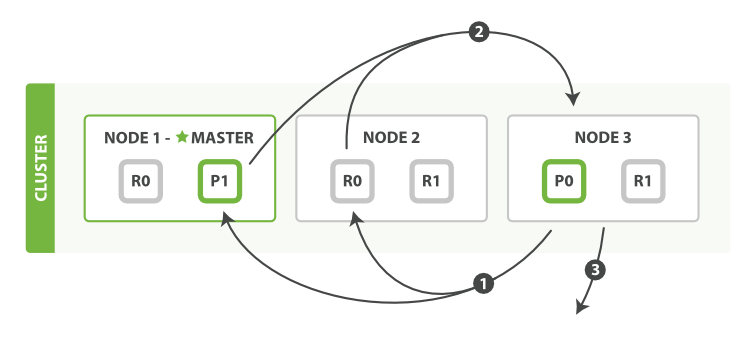
查询阶段query
- 当一个节点接收到一个搜索请求,则这个节点就变成了协调节点
- 协调节点,广播请求到所有分片
- 分片返回特定条数数据的轻量级数据(包含结果集中的每一个文档的ID和进行排序所需要的信息)
- 协调节点汇总,协调节点排序,确定要输出的数据记录和及其排序

- 取回阶段fetch
- 确定查询阶段已经获取到的哪些记录需要被返回
- 协调节点向特定分片发送请求
- 特定分片返回数据
- 协调节点汇总数据并返回客户端
- 相关性计算
- 在搜索过程中对文档进行排序,需要对每一个文档进行打分,判别文档与搜索条件的相关程度。
- 在旧版本的ES中默认采用TF/IDF(term frequency/inverse document frequency)算法对文档进行打分。
其他参考
Elasticsearch内核解析 - 写入篇
Elasticsearch内核解析 - 查询篇
segmentfault上的总结文章 ES分布式架构及底层原理
高质量博客 Elasticsearch原理剖析

若有收获,就点个赞吧
0 人点赞
