分而治之
大任务分为多个小的子任务Map
并行执行任务后,合并结果Reduce
I think that you are my sunshine ha?
OK?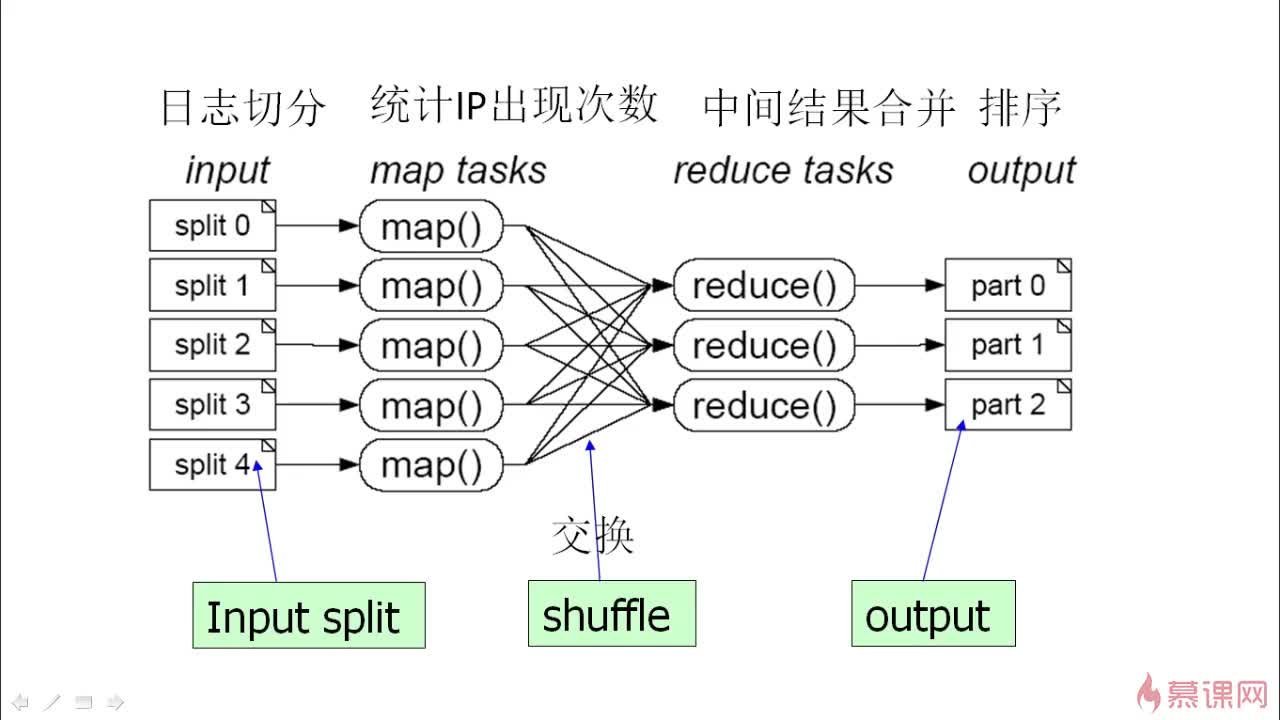
对100G日志文件进行分析,首先切割成一定分数日志,分开统计之后,再对相同特点的按照规则进行交换,再进行相同结果合并,最后排序
MapReduce处理数据过程主要分成2个阶段:Map阶段和Reduce阶段。首先执行Map阶段,再执行Reduce阶段。Map和Reduce的处理逻辑由用户自定义实现,但要符合MapReduce框架的约定。
在正式执行Map前,需要将输入数据进行”分片”。所谓分片,就是将输入数据切分为大小相等的数据块,每一块作为单个Map Worker的输入被处理,以便于多个Map Worker同时工作。
分片完毕后,多个Map Worker就可以同时工作了。每个Map Worker在读入各自的数据后,进行计算处理,最终输出给Reduce。Map Worker在输出数据时,需要为每一条输出数据指定一个Key。
这个Key值决定了这条数据将会被发送给哪一个Reduce Worker。Key值和Reduce Worker是多对一的关系,具有相同Key的数据会被发送给同一个Reduce Worker,单个Reduce Worker有可能会接收到多个Key值的数据。
在进入Reduce阶段之前,MapReduce框架会对数据按照Key值排序,使得具有相同Key的数据彼此相邻。如果用户指定了”合并操作”(Combiner),框架会调用Combiner,将具有相同Key的数据进行聚合。Combiner的逻辑可以由用户自定义实现。这部分的处理通常也叫做”洗牌”(Shuffle)。
接下来进入Reduce阶段。相同的Key的数据会到达同一个Reduce Worker。同一个Reduce Worker会接收来自多个Map Worker的数据。每个Reduce Worker会对Key相同的多个数据进行Reduce操作。最后,一个Key的多条数据经过Reduce的作用后,将变成了一个值。
MapReduce的运行流程
Job—>Task—>MapTask和ReduceTask
JobTracker:
作业调度
分配任务,监控任务执行进度
监控TaskTracker状态
TaskTracker:
执行任务
汇报任务状态
容错机制:2种
1)重复执行:
默认重复执行 4 次,若还是失败,则放弃执行
2)推测执行:
可以保证任务不会因为某1-2个机器错误或故障而导致整体效率下降
hadoop2.0之后已经取消jobTracker TaskTracker,用yarn架构替换
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
Hadoop MapReduceV2(Yarn) 框架简介
大数据(三) - YARN

若有收获,就点个赞吧
0 人点赞
