Spark的Shuffle过程介绍
https://www.cnblogs.com/jxhd1/p/6528540.html
Spark Shuffle概念及shuffle机制
Spark Shuffle原理及相关调优
1、基于Hash的Shuffle写操作
1、基于排序的Shuffle写操作
sortByKey
ReduceByKeyGroupByKey的区别
- 返回值类型不同:reduceByKey返回的是RDD[(K, V)],而groupByKey返回的是RDD[(K, Iterable[V])],举例来说这两者的区别。
- 比如含有一下数据的rdd应用上面两个方法做求和:(a,1),(a,2),(a,3),(b,1),(b,2),(c,1);reduceByKey产生的中间结果(a,6),(b,3),(c,1);而groupByKey产生的中间结果结果为((a,1)(a,2)(a,3)),((b,1)(b,2)),(c,1),(以上结果为一个分区中的中间结果)可见groupByKey的结果更加消耗资源
- 作用不同,reduceByKey作用是聚合,异或等,groupByKey作用主要是分组,也可以做聚合(分组之后)
- map端中间结果对键对应的值得聚合方式不同
- 前者性能好,后者在大数据量下,可能出现资源过度消耗的问题,性能差
- reduceByKey在每个分区移动数据之前,会对每一个分区中的key所对应的values进行本地聚合(combine)操作,然后再利用reduce对所有分区中的每个键对应的值进行再次聚合。整个过程如图:
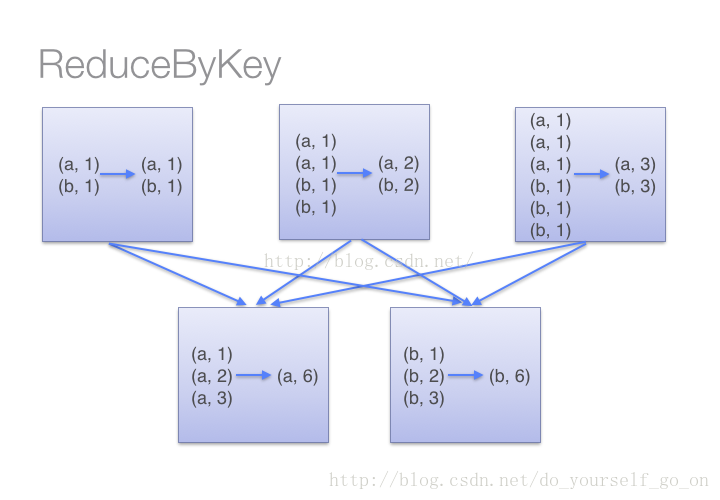
- groupByKey是把分区中的所有的键值对都进行移动,然后再进行整体求和,这样会导致集群节点之间的开销较大,传输效率较低,也是上文所说的内存溢出错误出现的根本原因
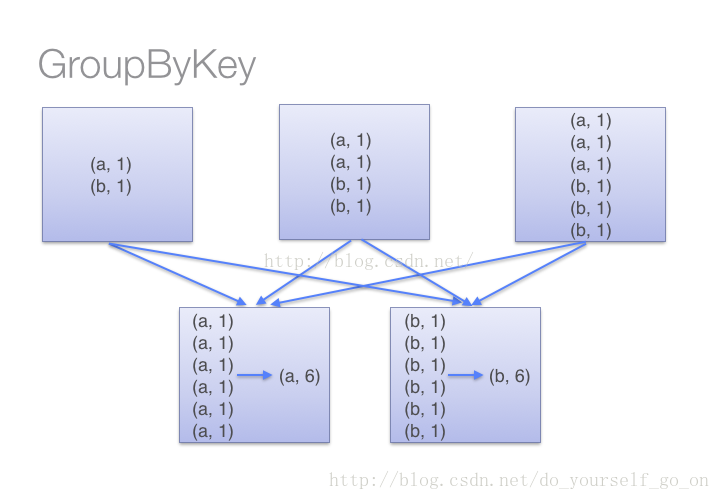
- 注意combineByKey,一个相对底层的基于键进行聚合的基础方法
- reduceByKey,groupByKey都是用它实现的
- 传入参数更加复杂,也可以实现更底层,更自定义的操作。

若有收获,就点个赞吧
0 人点赞
