1 Driver端流程
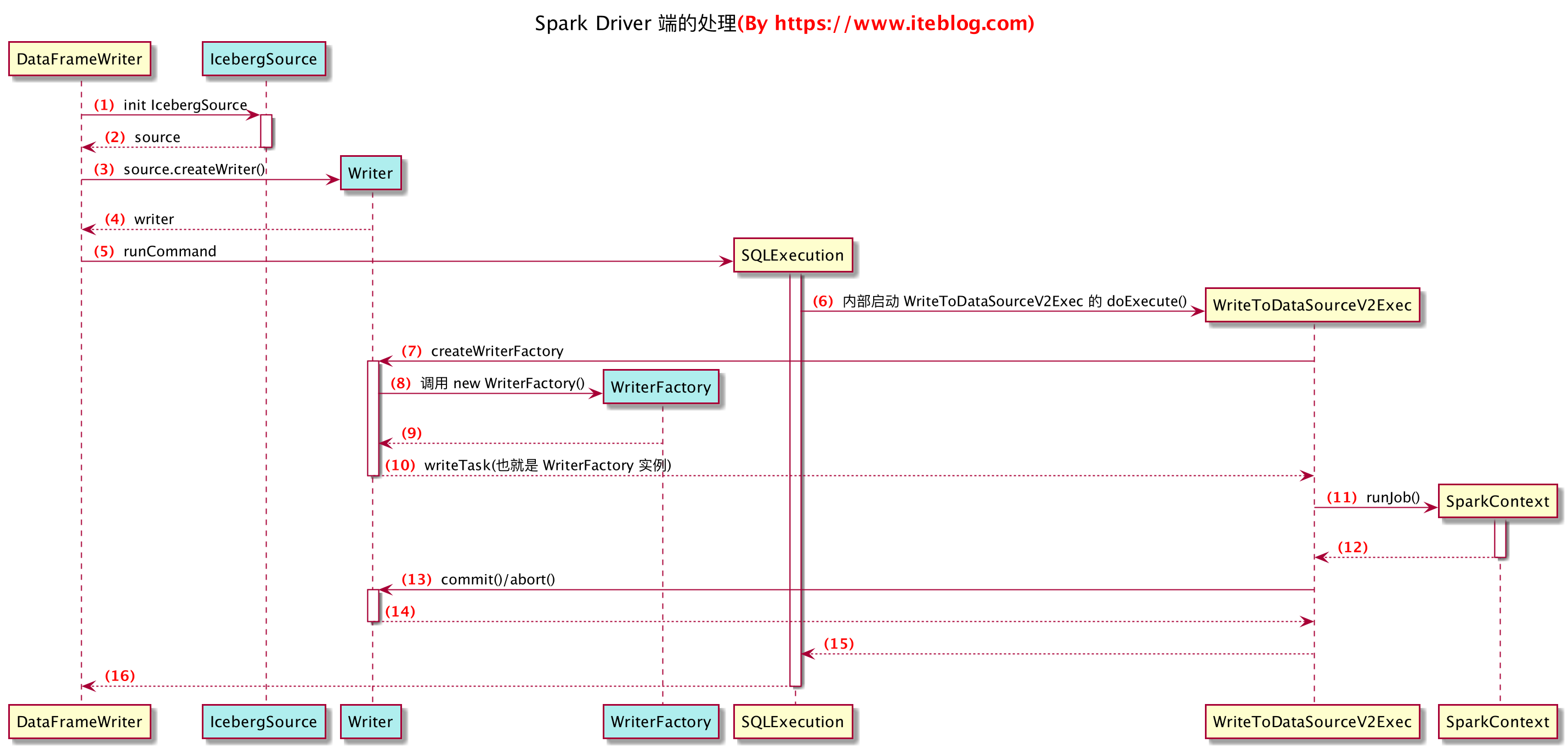
- 首先我们代码中
spark.write创建了DataFrameWriter DataFrameWriter.save()方法会依次执行图中的1-5步骤- 注意其中的
createWriter方法会找到特定的WriteSupport子类去初始化writer- 初始化时,会找到org.apache.iceberg.spark.source.IcebergSource类
- 关注其
createWriter方法,会返回一个 org.apache.iceberg.spark.source.Writer - 这个Writer需要集成spark的DataSourceWriter,实现特定的commit abort方法
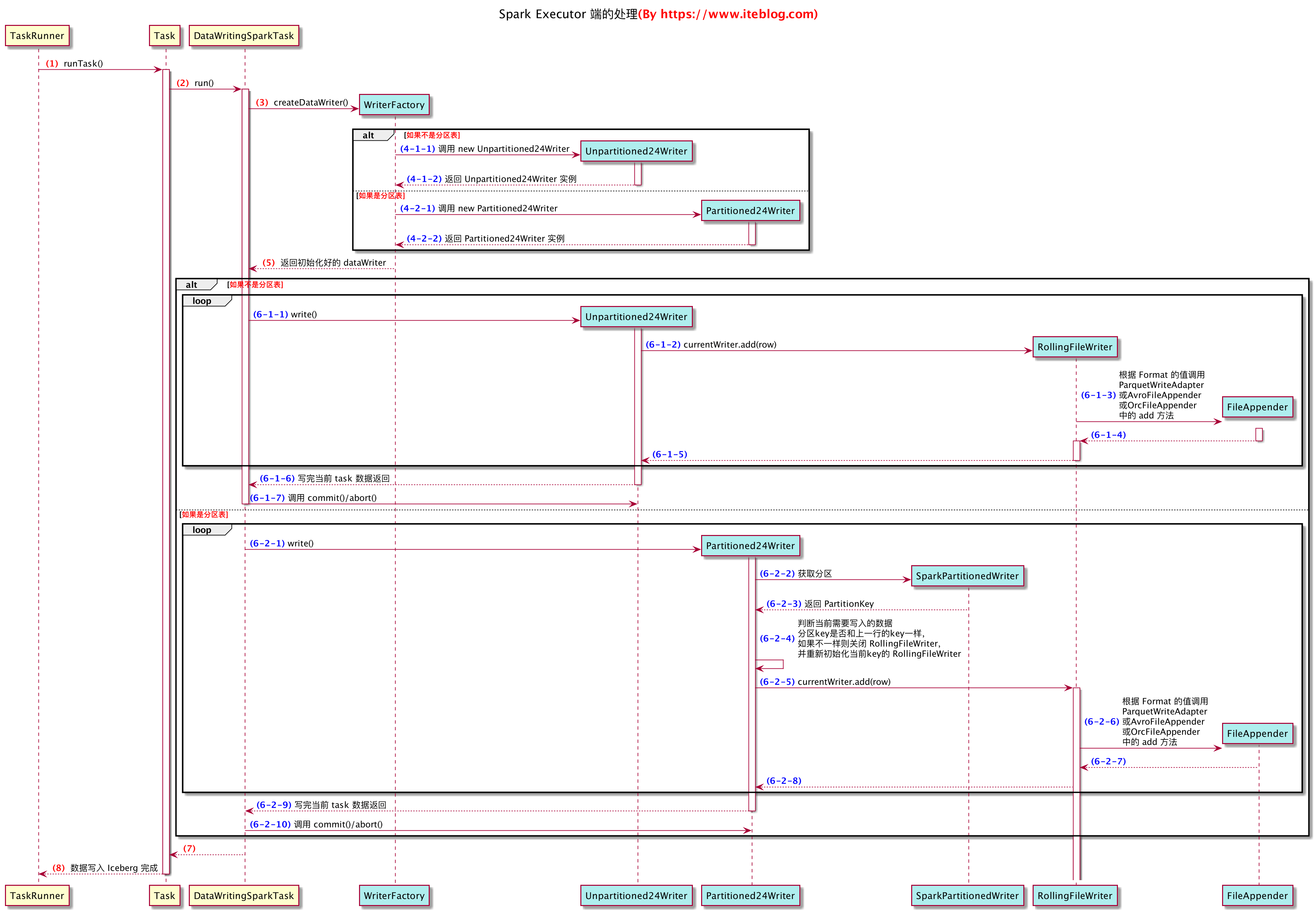
- iceberg实现了这个writer,还提供了还几种不同的子类,如Partitioned24Writer 和Unpartitioned24Writer,我们后面会讲到
- 执行DataFrameWriter的runCommand,会去执行WriteToDataSourceV2的doExecute方法
- SparkContext的的runJob,会真正启动job,下发给executor
sparkContext.runJob(rdd,//func: (TaskContext, Iterator[T]) => U, 在rdd的每个分区上都执行的方法//这里定义的是,在每个分区中都执行DataWritingSparkTask.run方法(context: TaskContext, iter: Iterator[InternalRow]) =>DataWritingSparkTask.run(writeTask, context, iter, useCommitCoordinator),// 希望跑Task的分区rdd.partitions.indices,// resultHandler: (Int, U) => Unit) 每个分区任务执行完成后的,Driver的回调函数// Int指是哪个分区返回的消息,U是消息,(index, message: WriterCommitMessage) => {messages(index) = messagewriter.onDataWriterCommit(message)})

若有收获,就点个赞吧
0 人点赞
