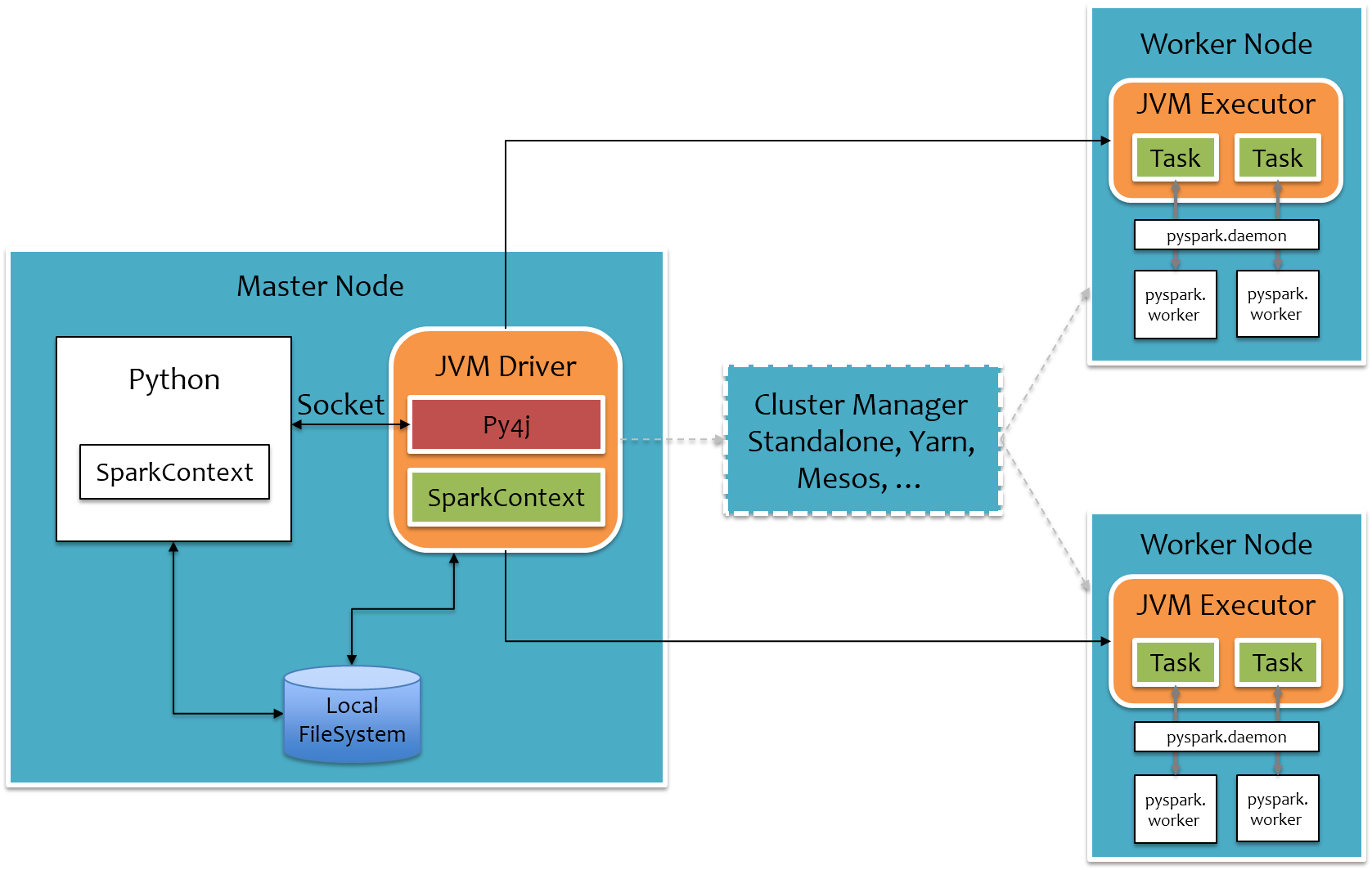
- 总体上来说,PySpark是借助Py4j实现Python调用Java,来驱动Spark应用程序,本质上主要还是JVM runtime
- Java到Python的结果返回是通过本地Socket完成。
虽然这种架构保证了Spark核心代码的独立性,但是在大数据场景下,JVM和Python进程间频繁的数据通信导致其性能损耗较多,恶劣时还可能会直接卡死,所以建议对于大规模机器学习或者Streaming应用场景还是慎用PySpark,尽量使用原生的Scala/Java编写应用程序,对于中小规模数据量下的简单离线任务,可以使用PySpark快速部署提交。
临时任务跑pyspark,线上例行化任务还是推荐scala,另外pyspark依赖的第三方包也比较烦躁,需要单独打包

若有收获,就点个赞吧
0 人点赞
