起因
在看技术分析报告的时候,我一般会把防预加载的一些URL处理还原回去。因为各个厂商的处理方式不一样,不统一看着有一点点不舒服。
昨天在看Kaspersky的一篇文章时发现其URL的hxxp并不一致,无法完全文本替换: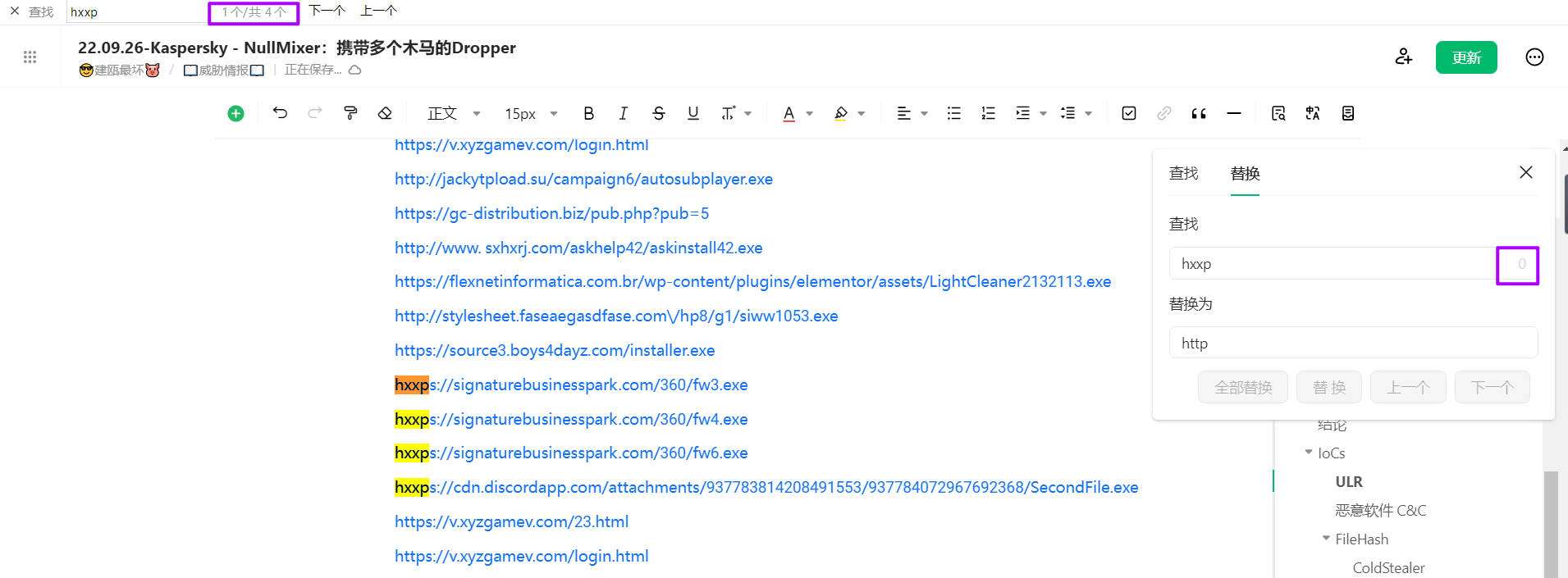
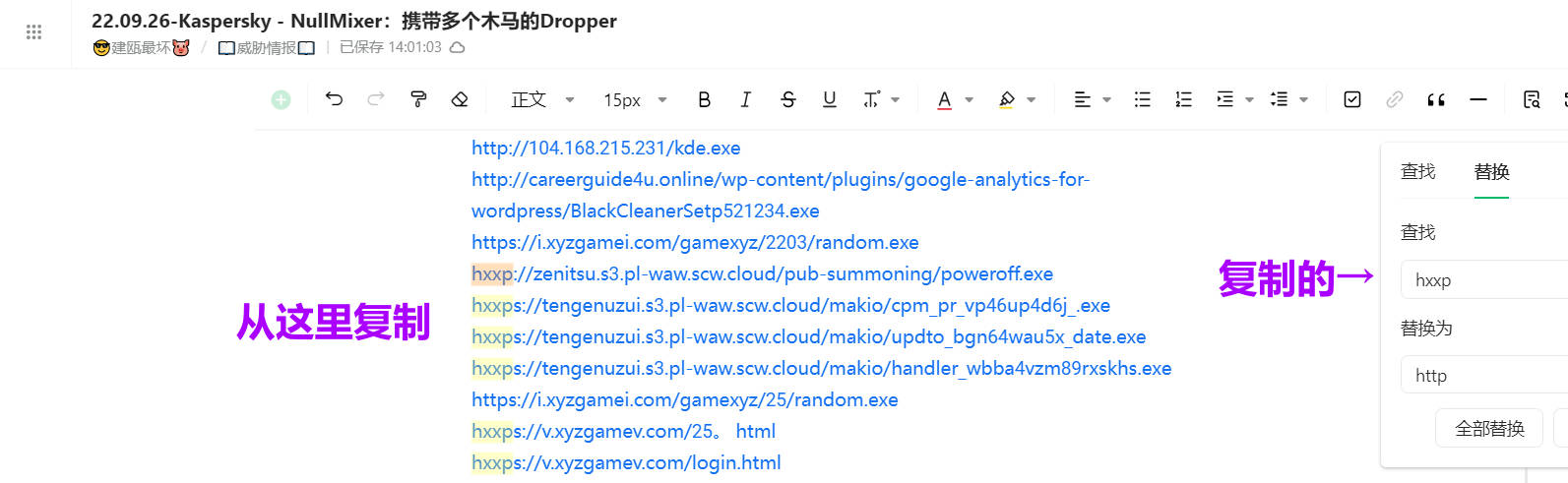
原文
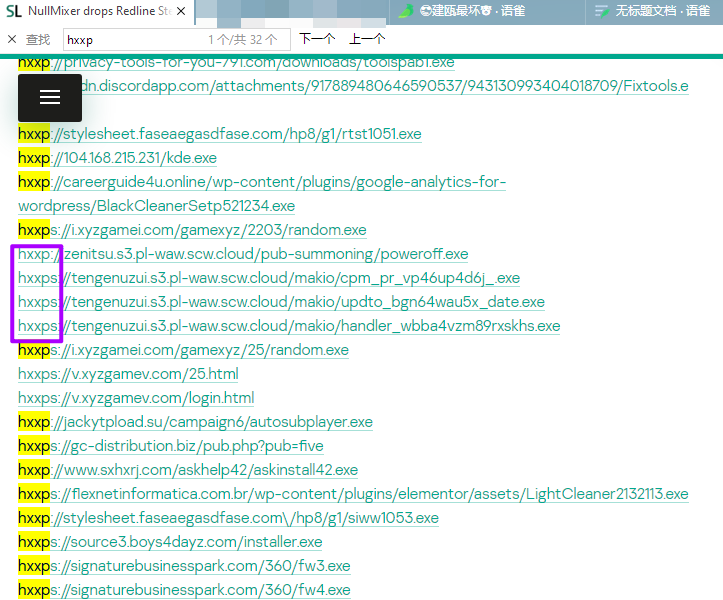
十六进制查看
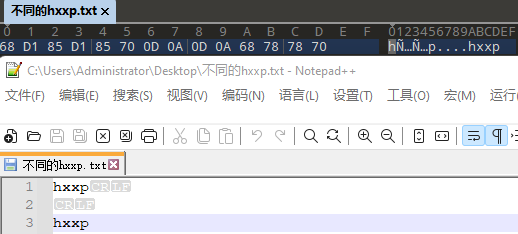
正常的hxxp
68 78 78 70
非正常的hxxp
68 D1 85 D1 85 70
不同处
“h”和“p”都相同,仅“x”不同,分别为:
- 正常:78h
- 非正常:D185h
D185h
百度和谷歌一下都没搜到十六进制的D185是啥: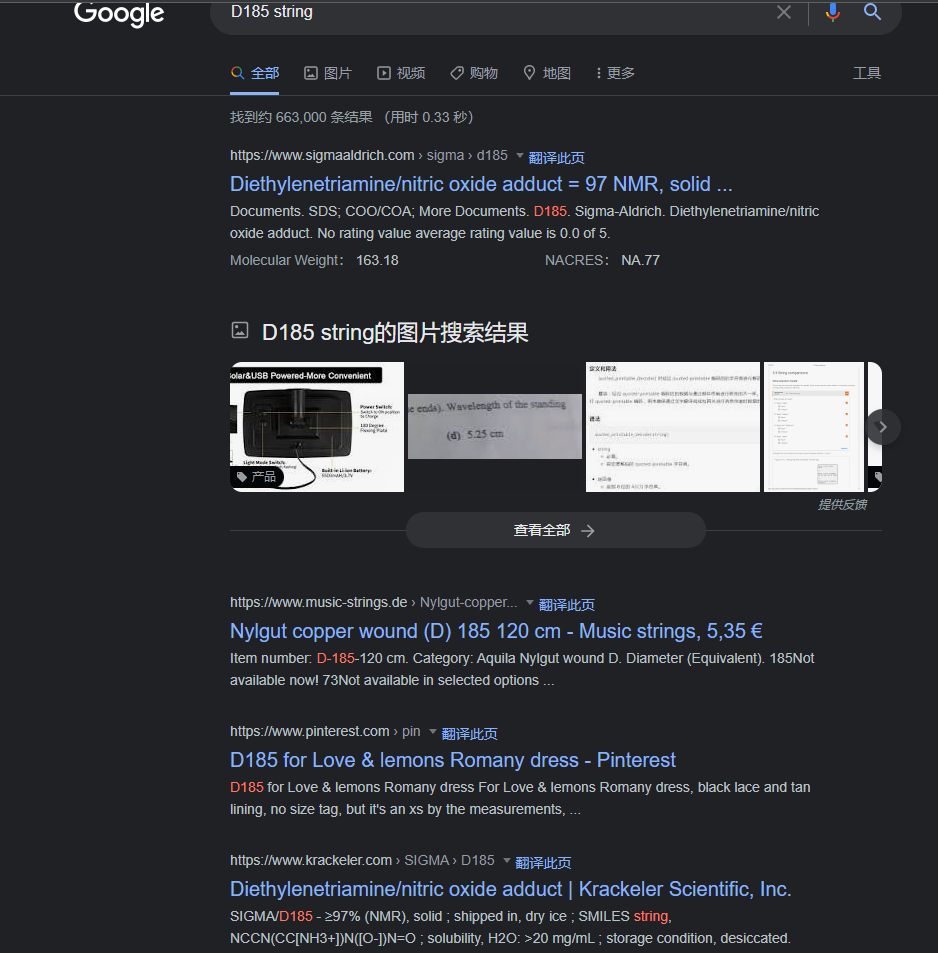
查看了一下D18[0-8],感觉“рстуфхцчш”像俄语的字母: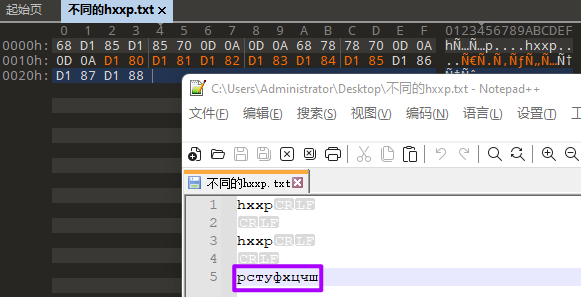
并且Kaspersky是俄罗斯安全公司,我还确认了一下,3个作者里面有2个明显是俄罗斯人:

西里尔字母
很接近了
此时我已经能确定是俄语的一种,但是其十六进制的值对不上:
查询到的是0425h。注意:其实错了,这里是大写的X。但是——错误更有意义 | 人生哪有一帆风顺
如果我此时正确的话,搜“D185 0445”是另一种找到答案的方式: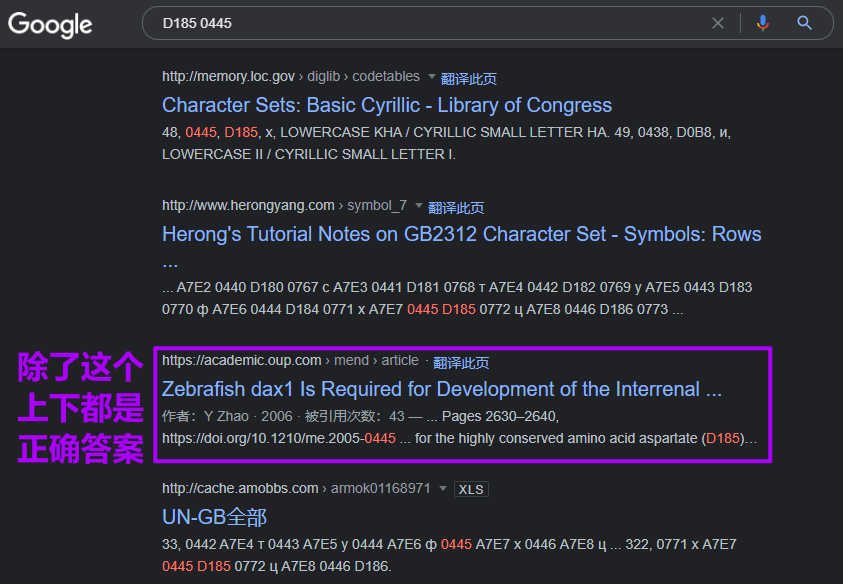
所以一定要认真仔细,多核对,不要乍一眼看就直接复制。真相大白
再搜索“西里尔字母 D185”: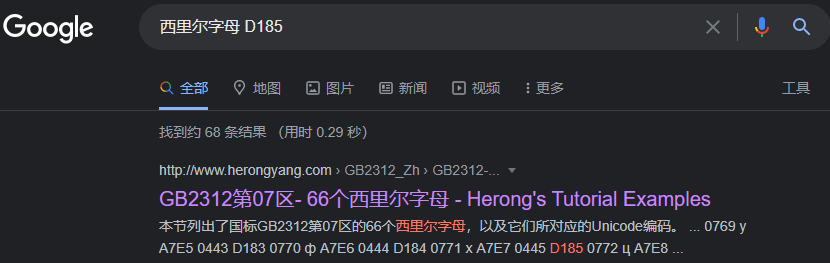
发现原来在三种编码里,十六进制不同,之前在百度搜到的很多文章里仅有Unicode编码,对应的十六进制是04[0-F]{2}。
D185是UTF-8的十六进制,所以就一直对不上: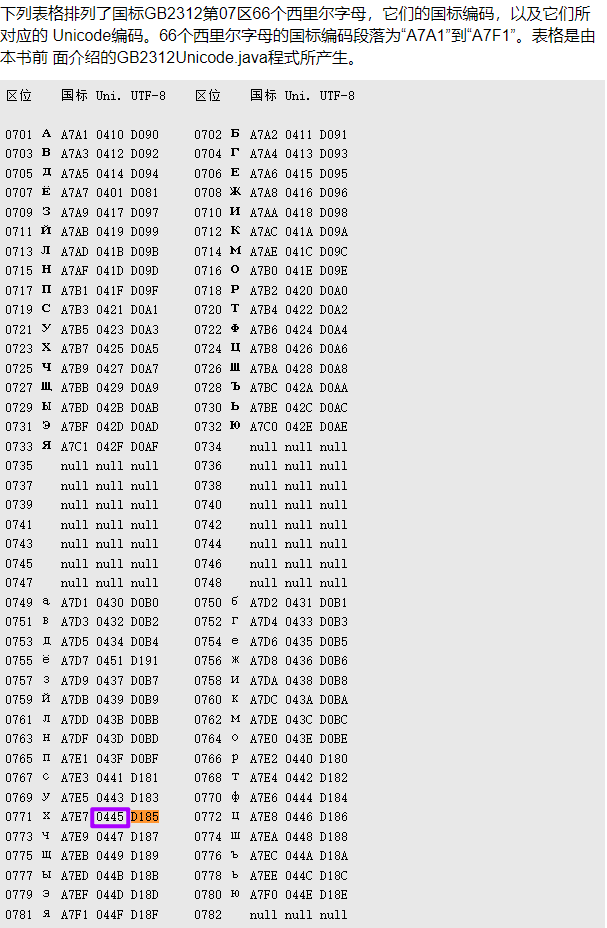
原来是UTF-8的D185
文件是以UTF-8保存的,我忽略了这个细节: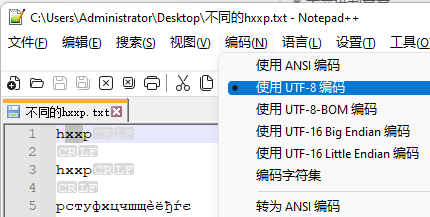
还有一个英语的亏
按道理在搜D185和其表示的时候,我就应该能直接找到,可惜我搜的表示是“string”: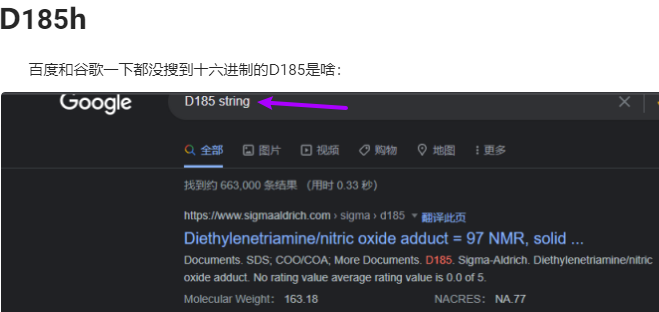
在“正确答案”里才发现更适合的表达是“character”,字符: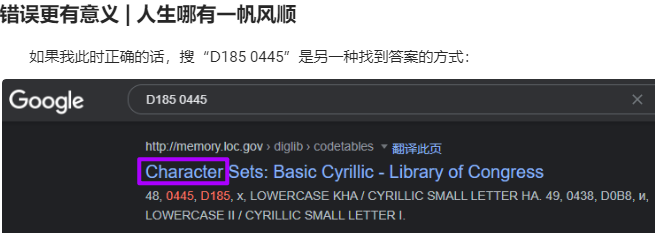
但好像也不太对
信心满满地一搜,发现咋是韩语: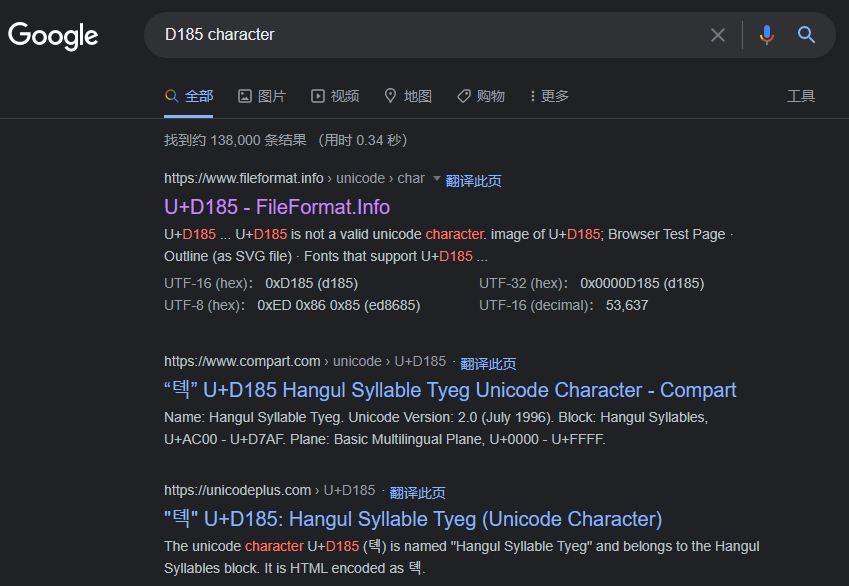
一看又是Unicode的十六进制
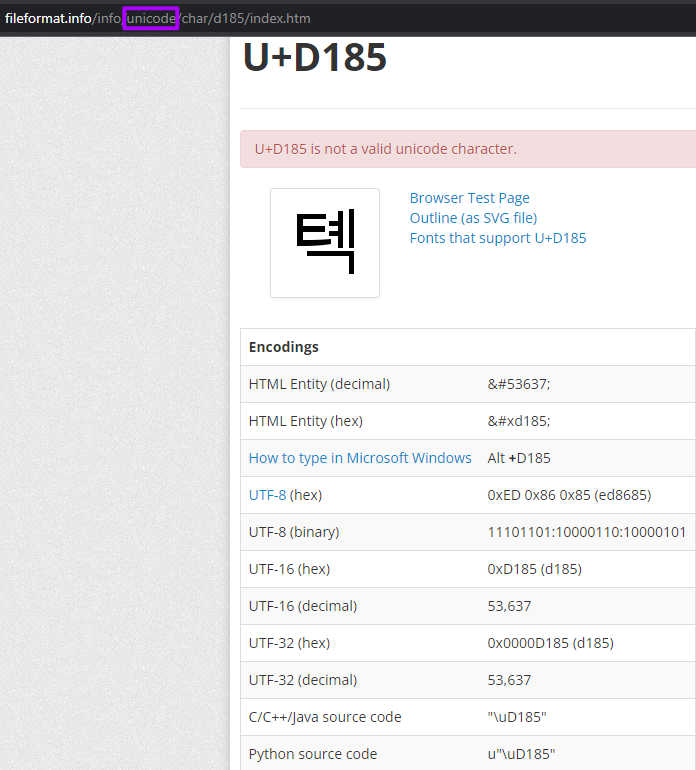
加上“UTF-8”呢
出现了对错同同时存在的情况,上面都是韩语,整个搜索结果页面就一个是西里尔的: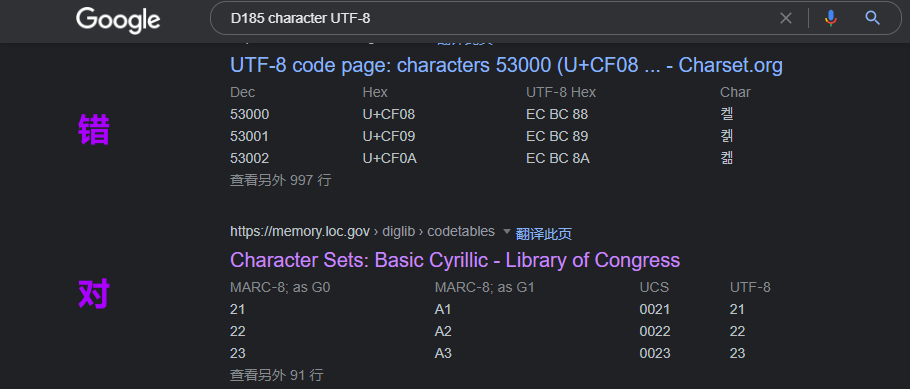
也不是我想的效果😑😑😑总结
回顾了一下,好像没办法在不知道正确答案的时候,很快就能直接一步登天到正确答案。
得靠多因素交叉+不断尝试才能找到正确答案。
其实在确定“hxxp”不同是因为2个不同语言(或许用编码形容更合适)也算找到答案,但我就不行,我这个倔脾气一定要找到😡😡😡我不止要找到技术原因,我还要找到人为原因(原因是作者是俄罗斯人。但他们也不应该在英语里夹俄语啊,也是很奇怪)
不太可能直接成功,需要不停的做无用尝试,或许人生也是如此吧(强行煽情
乾坤未定,你我皆是牛马(不是!!!!!!

若有收获,就点个赞吧
0 人点赞
