致谢
感谢杰哥不厌其烦地回答我的提问!
还帮我把逐个写入后排序,改成保存为二维数组后排序⬆⬇
兼容性更新
PE
无法计算ImpHash的PE文件
出现无法计算ImpHash的PE文件,会造成列表的元素数量不对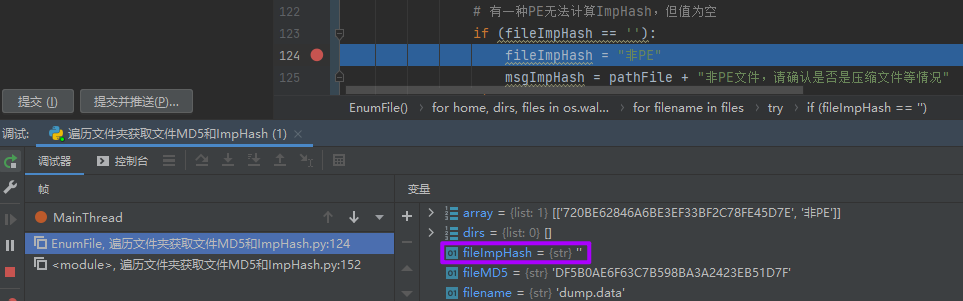
解决方案
重写计算ImpHash的逻辑,写在“try except异常处理”内,再加上对ImpHash的判断
🐍Python脚本🐍
逻辑
- 遍历文件夹
1.1 获取文件MD5
1.2 获取ImpHash
1.2.1 获取到ImpHash
if判断ImpHash是否为Null
非Null保存,Null同1.2.2
1.2.2 获取不到ImpHash
提示可能非PE文件
- 将数据保存到二维数组
2.1 以二维数组的第二元素排序(默认升序)
2.2 将排序后的数组写入Excel表格
- 表格处理
3.1 对表格第2列(ImpHash值)进行合并
3.2 对单元格设置样式为上下居中
代码
#coding=utf-8import osimport hashlibimport gotoimport pefileimport pandas as pdfrom openpyxl import load_workbookfrom openpyxl.styles import Alignmentdef Excel2Write(dataMD5, dataImpHash):excel = pd.read_excel(pathExcel)# 先创建一个DataFrame,用来增加进数据框的最后一行newDF = pd.DataFrame({'MD5': dataMD5, 'ImpHash': dataImpHash}, index=[0])#print(newDF)excel = excel.append(newDF, ignore_index=True)excel.to_excel(pathExcel, index=False)def Excel2Merge(pathExcel, nColumn):# 列数映射为字母strColumn = chr(nColumn + 64)# 加载Excel和Sheetwb = load_workbook(pathExcel)sheet = wb["通过ImpHash聚类"]# 获取列中单元格的数据listCellValue = []i = 2while True:valueCell = sheet.cell(i, nColumn).valueif valueCell:listCellValue.append(valueCell)else:breaki += 1# 判断合并单元格的始末位置cellStart = 0flag = listCellValue[0]for i in range(len(listCellValue)):if listCellValue[i] != flag:flag = listCellValue[i]cellEnd = i - 1if cellEnd >= cellStart:# 合并sheet.merge_cells(strColumn + str(cellStart + 2) + ":" + strColumn + str(cellEnd + 2))cellStart = cellEnd + 1if i == len(listCellValue) - 1:cellEnd = isheet.merge_cells(strColumn + str(cellStart + 2) + ":" + strColumn + str(cellEnd + 2))wb.save(pathExcel)print("已按照" + strColumn + "列完成合并")def Excel2View(pathExcel):# 加载Excel和Sheetwb = load_workbook(pathExcel)sheet = wb["通过ImpHash聚类"]nRows = sheet.max_rownCols = sheet.max_columnfor j in range(1, nCols + 1):for i in range(2, nRows + 1):theCell = sheet.cell(row=i, column=j)theCell.alignment = Alignment(vertical='center')wb.save(pathExcel)print("已居中处理")def GetFileMD5(filename):if not os.path.isfile(filename):# print(filename)returnstrMD5 = hashlib.md5()f = open(filename, 'rb')while True:fContent = f.read()if not fContent:breakstrMD5.update(fContent)f.close()return strMD5.hexdigest().upper()def PE_isPE(filename):try:file = pefile.PE(filename)if file.is_exe():return 1if file.is_dll():return 2if file.is_driver():return 3else:return 0except:return 0def PE_GetImpHash(filename):file = pefile.PE(filename)return file.get_imphash().upper()def EnumFile(pathDir):array = []for home, dirs, files in os.walk(pathDir):for pathDir in dirs:print("文件夹:" + pathDir)for filename in files:pathFile = os.path.join(home, filename)# 获取MD5fileMD5 = GetFileMD5(pathFile)print("文件MD5:" + fileMD5)# 查看是否是PE文件,是则获取其ImpHashisPE = PE_isPE(pathFile)try:# 尝试获取ImpHashfileImpHash = PE_GetImpHash(pathFile)msgImpHash = "PE文件ImpHash:" + fileImpHash# 有一种PE无法计算ImpHash,但值为空if (fileImpHash == ''):fileImpHash = "非PE"msgImpHash = pathFile + "非PE文件,请确认是否是压缩文件等情况"except:# 提示非PEfileImpHash = "非PE"msgImpHash = pathFile + "非PE文件,请确认是否是压缩文件等情况"print(msgImpHash + "\r\n")# 将MD5和ImpHash写入Excel表格# Excel2Write(fileMD5, fileImpHash)# 保存为二维数组array.append([fileMD5, fileImpHash])# 对二位数组维度中第2个元素进行排序dfSorted = pd.DataFrame(sorted(array, key=lambda x: x[1]))ws = pd.ExcelWriter(pathExcel)dfSorted.to_excel(ws, sheet_name="通过ImpHash聚类", index=None, header=["MD5", "ImpHash"])ws.save()print("\r\n全部MD5和ImpHash写入完成")# 输出的Excel路径pathExcel = '提取MD5和ImpHash.xlsx'# 此处输入文件夹路径pathFolder = (r'路径')if __name__ == '__main__':EnumFile(pathFolder)Excel2Merge(pathExcel, 1)Excel2Merge(pathExcel, 2)Excel2View(pathExcel)

若有收获,就点个赞吧
0 人点赞
