前情提要
同事在一行一行的提取网页元素形成表格,我觉得应该有现成的库和函数才对: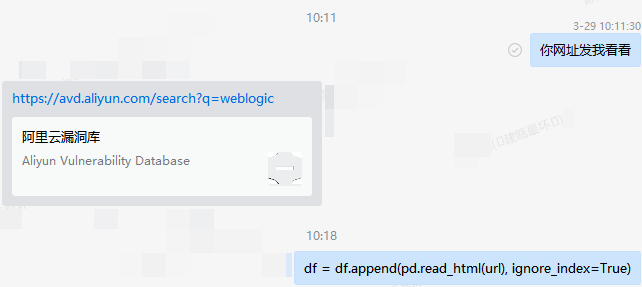
搜索
pd.read_html(iURL)
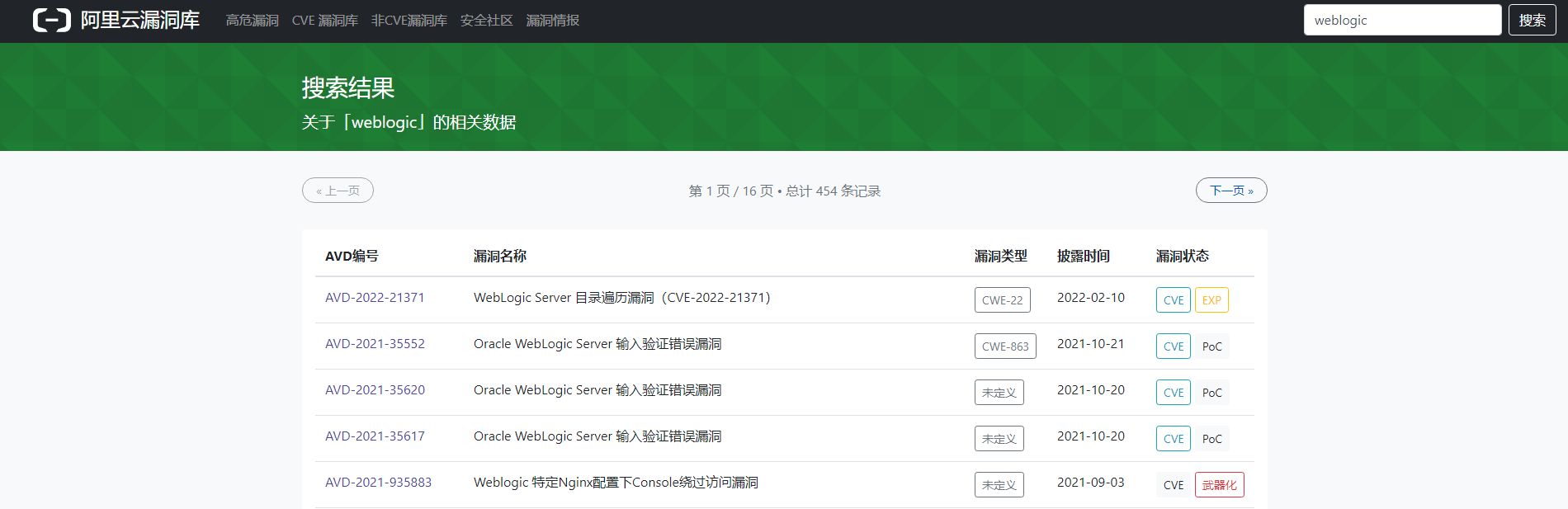
网页
🐍Python脚本🐍
- 获取数量
- 网页页数
- 总表格列数
- 生成网页页数表格并遍历
- “
pd.read_html”读取表格并追加至DataFrame
- “
- 遍历后对比DataFrame的列数和网页显示的总表格列数 ```python import re
import pandas as pd import requests
def GetTable( URL ): dfAll = pd.DataFrame() GetNumber( URL ) for i in range( nPage ): iURL = URL if (i != 0): iURL = URL + “&page=” + str( i + 1 ) print( “提取URL:” , iURL ) dfAll = dfAll.append( pd.read_html( iURL ) )
nRow = dfAll.shape[0]if (nNum != nRow):print( "😑😑😑个数不一致😑😑😑请核对个数" )print( dfAll )return dfAll
def GetNumber( URL ): respURL = requests.get( URL ) strHTML = respURL.text
global nPagenPage = int( re.findall( r"第 1 页 / ([\d]{1,}) 页" , strHTML )[0] )global nNumnNum = int( re.findall( r'总计 ([\d]{1,}) 条记录' , strHTML )[0] )
def DataFrame2CSV( df ): df.to_csv( pathFileCSV , index = False ) print( “DataFrame保存为CSV” )
strURL = “https://avd.aliyun.com/search?q=weblogic“ pathFileCSV = “WebLogic漏洞.csv” if name == ‘main‘: DataFrame2CSV( GetTable( strURL ) ) ```
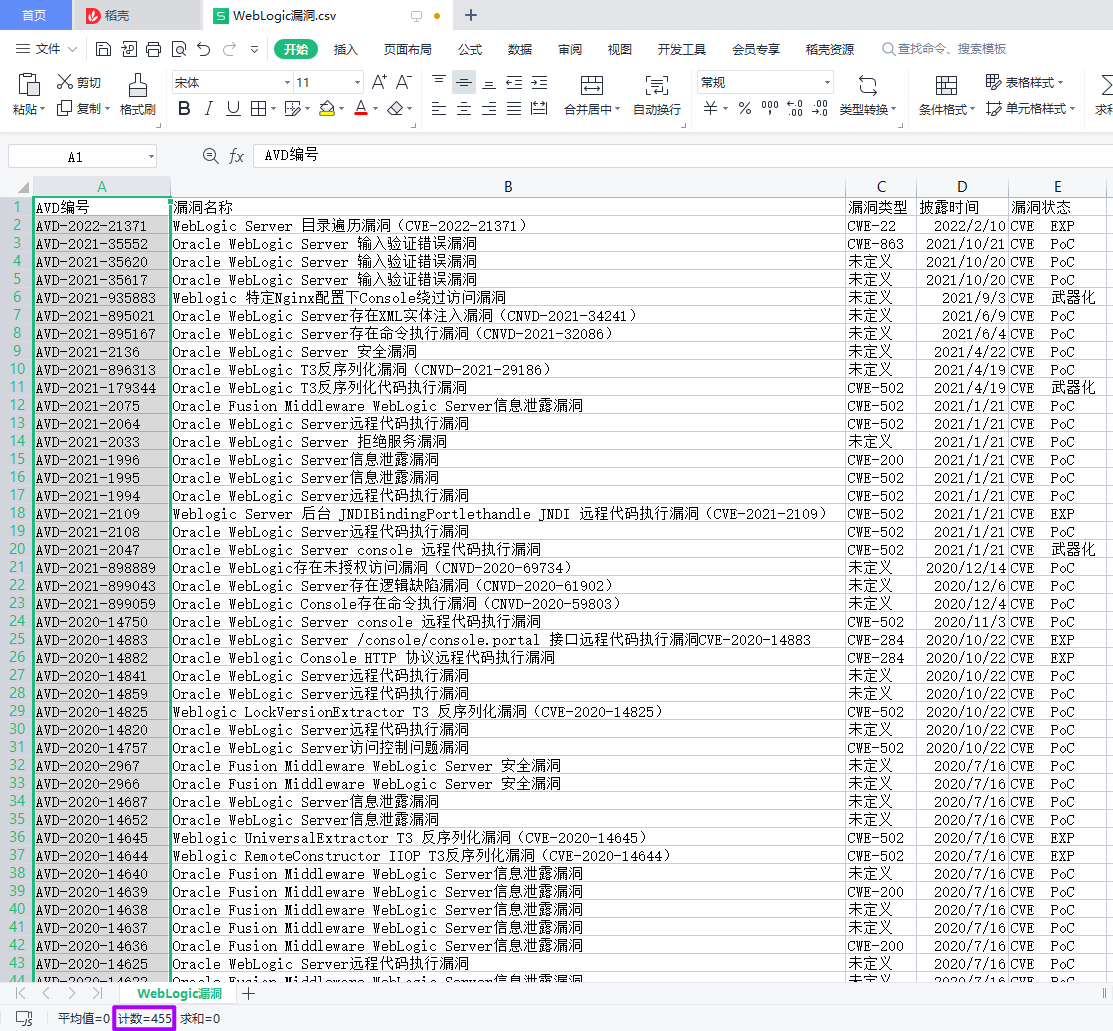
运行结果
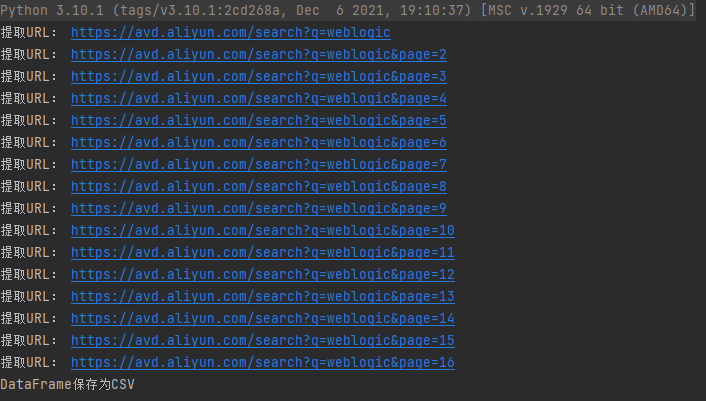
CSV

若有收获,就点个赞吧
0 人点赞
