背景
也可以用attackcti库,但是因为本次目的是给人看,不是单纯做数据库,所以需要输出为表格(看个人喜好,我选MarkDown格式)。
知道pandas有“read_html”,但是我要获取Detections后重构表格,把Detections插入到它的Technique或 Sub Technique下,并且还希望保留其中的超链接,所以最后考虑还是正则提取内容,用MarkDown重构表格后保存~
重新爬取
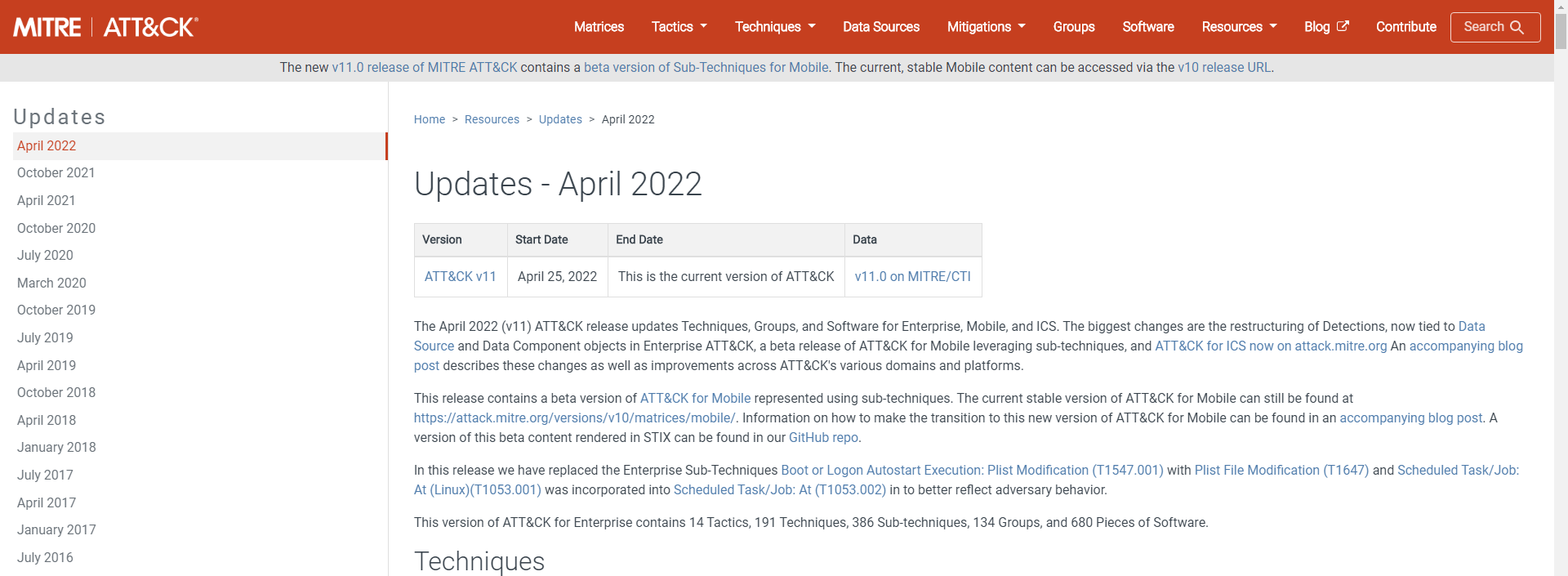
Mitre公司时常会更新ATT&CK矩阵(和其他产品),不建议用人工方式爬取和对比,直接用最新的覆盖。
2022年4月25日更新V11,平均一年更新2-3次: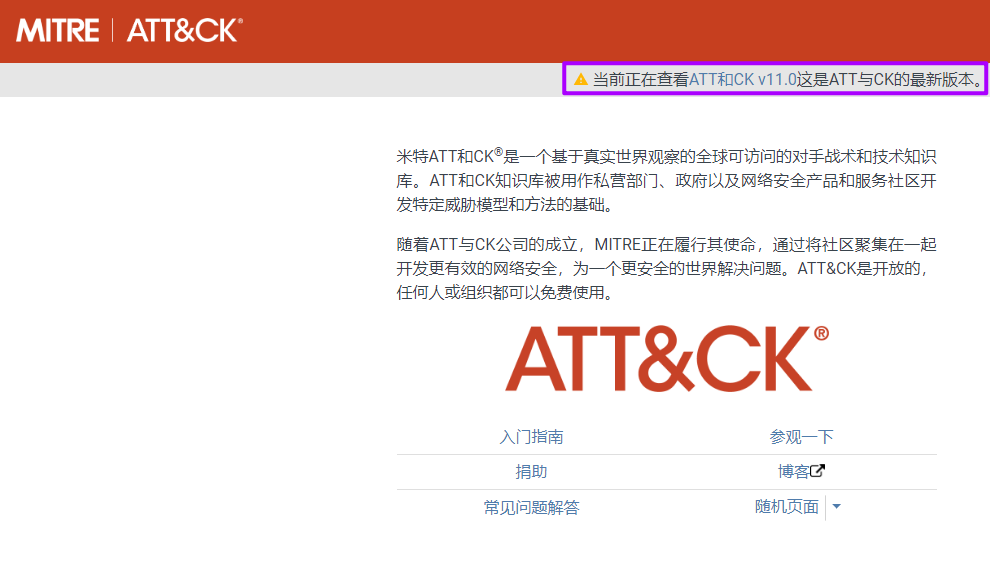
还有一些问题
因为用的是PyCharm开发,有一些用代理的问题:
- 写了谷歌API翻译中文的脚本,需要代理
- 爬ATT&CK,不能挂代理
所以目前不能在一个Python里面完成。
后续翻译需要另外完成:文件使用谷歌浏览器打开后,再基于浏览器的谷歌插件翻译。
收集分类-Techniques(技术和子技术)
T开头是技术,0.开头是这个技术下的子技术。
目前共14个技术分类:侦察、资源开发、初始访问、执行、坚持、权限提升、防御规避、凭证访问、发现、横向运动、募捐、指挥和控制、漏出、影响
工具:导出ATT&CK攻击分类.js
导入为浏览器插件:如何导入
使用方式:在如“侦察”等攻击分类页面可以导出页面“Techniques”下的表格,建议联合使用浏览器的机翻(推荐谷歌)后再导出: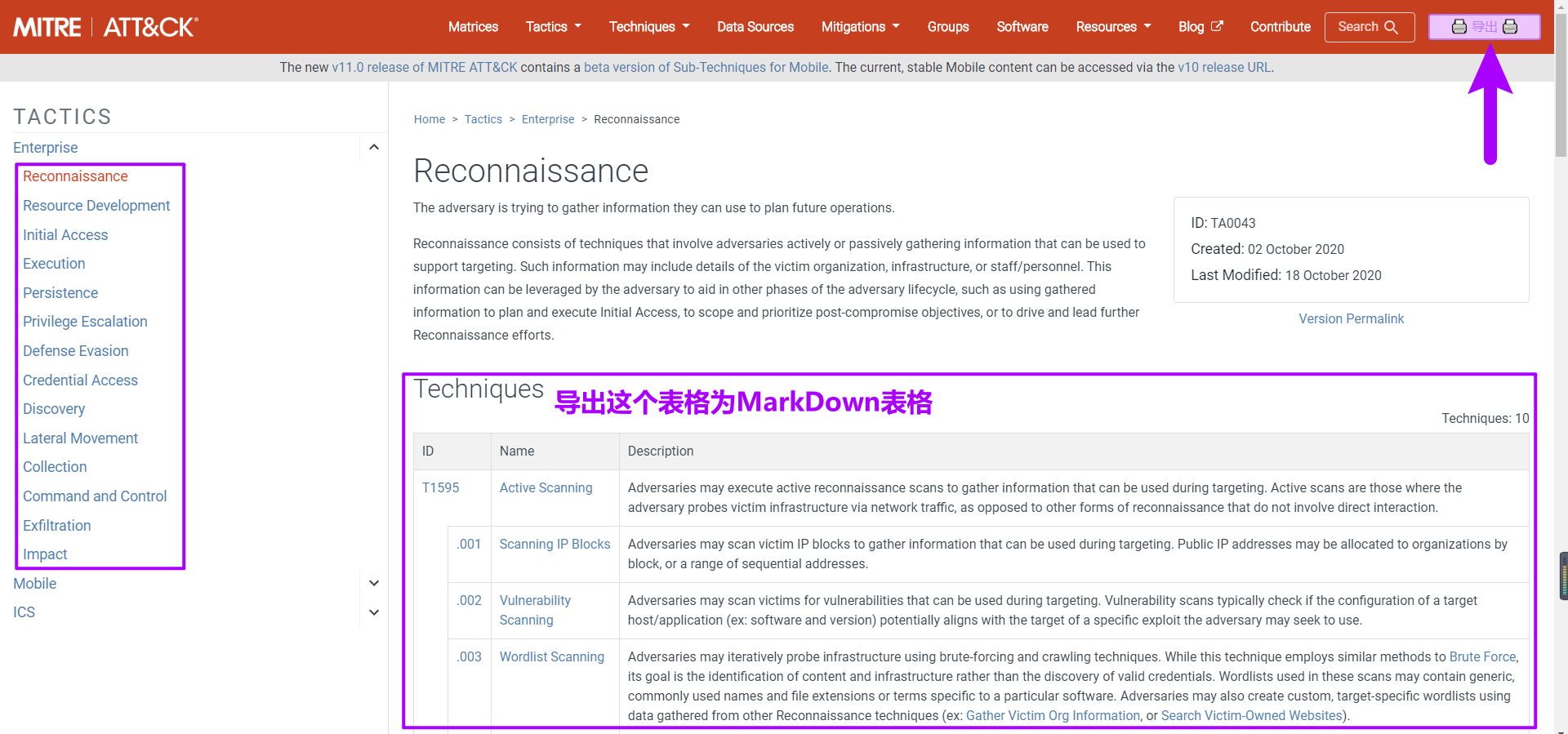
也可以用Python开发,但是前期已经先写了JS,暂时没有全自动化的必要,就没再额外花时间用Python重写。
Python爬取-Detection(检测点)
在浏览器页面导出“Techniques”容易,操作不会很多,但是检测点就是每个单个的技术都要取一次,手工做太累了。
目前采用的爬取方式是,把上方js导出的MarkDown表格放到一个目录内,遍历这个目录中的“.md”文件。脚本会提取每行的链接,访问,从返回的文本中,提取其中的“Detection”。
提取后会将“Detection”插入到“Techniques”,重新制表(MarkDown格式)后再输出到同目录下“提取Detection后”,文件名:原文件名+“-Python爬取Detection”:
1个技术分类大约需要1分钟,全部爬完大约10分钟。
🐍Python脚本🐍
离职再放😂😂😂
难点
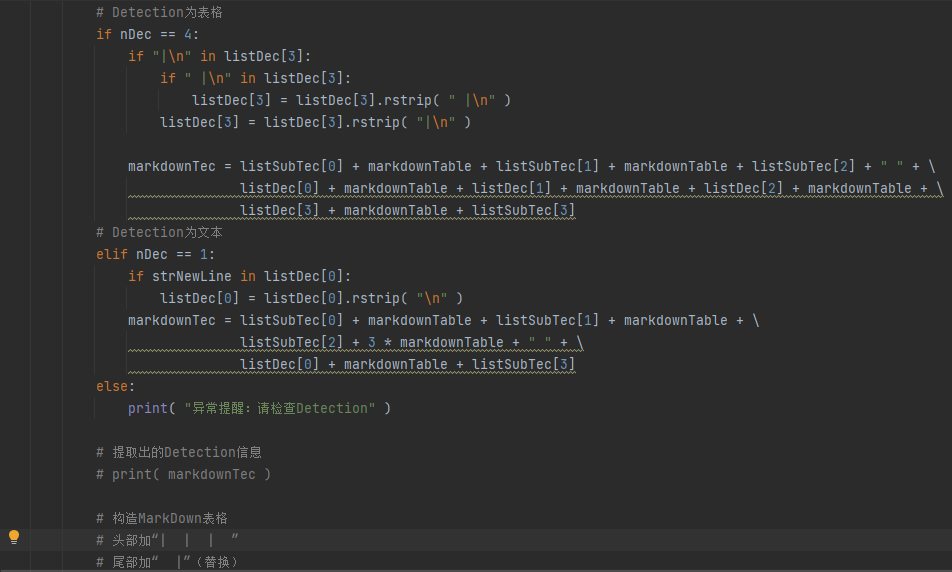
Detections一共有三种数据格式
处理方式
获取到Detections后进行判断,判断后处理为4列统一的MarkDown表格文本,以便后续插入到其技术下。
输出
Bug总结
要准确!
能用“startswith”就不要用“in”,能准确就不要宽松!
“in”也太宽松了!浪费了我两天😑😑😑
性能优化
反复调试代码,需要反复访问网页吗?
可以不用,第一次把网页的.text返回后写到本地保存,如有需要可以只保存部分内容。
文件名可以用URL.split(“\”)[-1]+”.html”

若有收获,就点个赞吧
0 人点赞
