实现功能
- 添加按钮
- 获取想要添加的位置
- 画按钮
- 提取知识库页面的标题和超链接
- 支持筛选标题 / 超链接
- 筛选使用for的情况须有:break或continue
- 给筛选后超链接
- 追加拼接参数“
/markdown?attachment=true&latexcode=false&anchor=true&linebreak=true”拼接为指定类型资源链接
- 追加拼接参数“
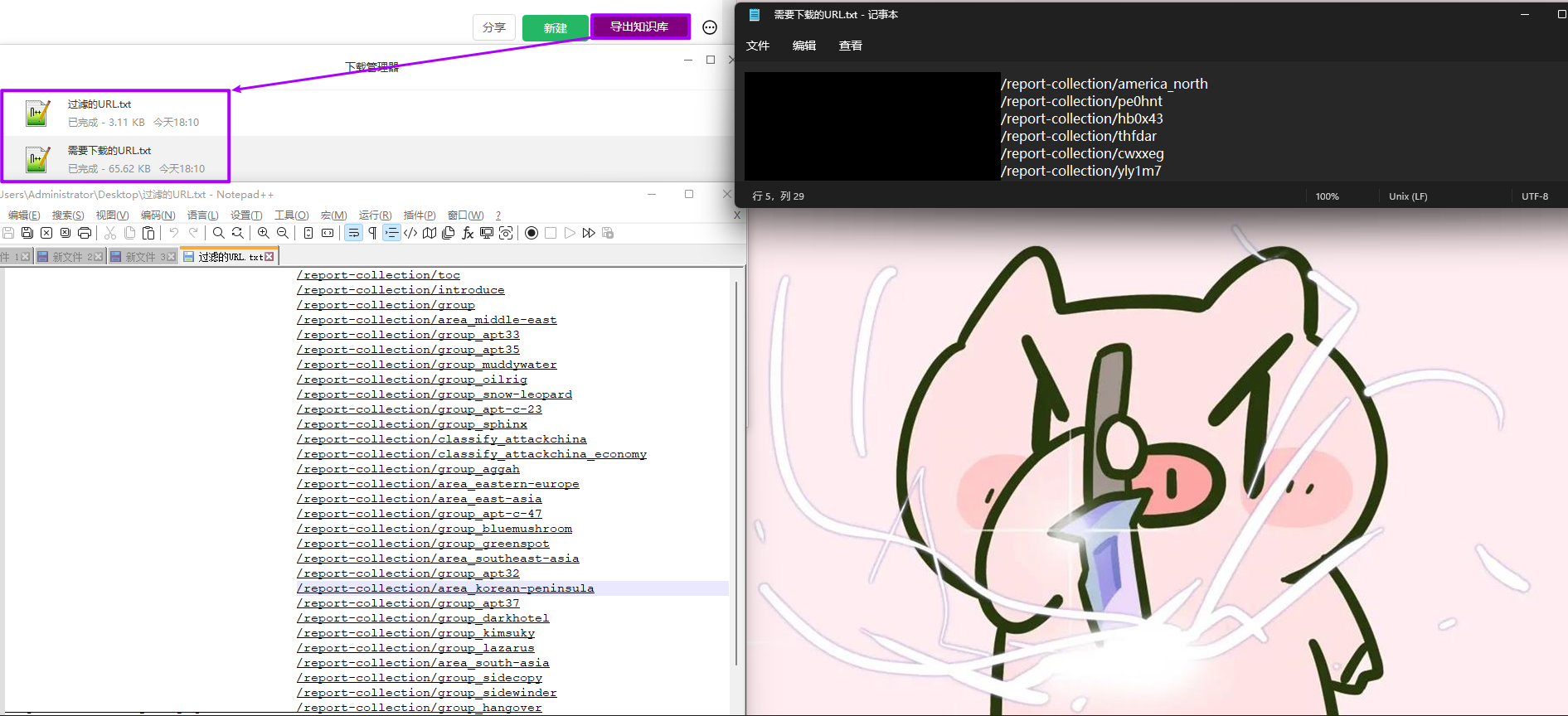
- 将3中的URL数据导出超链接数据到本地文件(要求为一行一个的txt文件)
- 下载3中指定类型资源(参考《前端下载文件的几种方式》)
JavaScript脚本
```javascript // ==UserScript== // @name 😎建瓯最坏🐷导出指定语雀知识库指定文档的标题和链接并下载MarkDown // @namespace https:// www.yuque.com/jianouzuihuai // @version 22.05.20 // @description 通过油猴脚本导出语雀知识库中带锚点和换行的MarkDown文件 // @author 😎建瓯最坏🐷 // @include .yuque.com/lwb6kc/ // @exclude .yuque.com/// // @icon https:// cdn.nlark.com/yuque/0/2021/png/1632223/1635923818567-7f54e0a1-144e-4fd0-9856-a24e5b2664c5.png // ==/UserScript==
(function() { “use strict”
setTimeout(function(){// alert("设置按钮")var buttonExport = document.createElement("button"); // 创建一个按钮buttonExport.textContent = "🖨️ 导出知识库 🖨️"; // 按钮内容buttonExport.style.width = '138px'; // 按钮宽度buttonExport.style.height = '32px'; // 按钮高度buttonExport.style.marginLeft = '16px'; // 距离左边16pxbuttonExport.style.color = '#BA7CFF'; // 按钮文字颜色buttonExport.style.border = '2px #BA7CFF solid'; // 边框buttonExport.style.font = 'bold'; // 文字加粗buttonExport.style.background = '#EEC6FF'; // 按钮底色buttonExport.style.borderRadius = '4px'; // 按钮四个角弧度var eleButton = document.getElementsByClassName("favor-wrapper")[0]eleButton.appendChild(buttonExport)// 过滤的数组var list2Filter = []// 保留的数组var listLinkReport = []// 当前知识库链接var strBaseURI = document.baseURI// 定位到文档树形列表中var eleTreeList = document.getElementsByClassName("ant-tree-list-holder-inner")[0]// 文档树形列表中的<a>标签var arrTagA = eleTreeList.getElementsByTagName('a')var nTagA = arrTagA.lengthvar iTitle, iLinkvar arrReport = []// 遍历子元素for(var i = 0; i < nTagA; i++){var iTagA = arrTagA[i]// 2. 无“target”属性// var bTarget = iTagA.getAttribute('target')// if (bTarget == null)// or 有“draggable” / “title”属性 的<a>标签var bTitle = iTagA.getAttribute('title')if (bTitle){// 获取报错<a>标签中的“title”属性iTitle = iTagA.getAttribute('title')if (iTitle.indexOf("#") != -1){// 井号会导致导出的数据被截断iTitle = iTitle.replace("#", "-")}// 获取报错<a>标签中的“href”属性iLink = iTagA.getAttribute('href')arrReport.push([iTitle, iLink])}}/*console.log(listLinkReport)console.log(list2Filter)*/// 遍历链接进行筛选arrReport.forEach(FilterLinks)// 按键点击事件buttonExport.onclick = function (){// 指定下载组织列表var arrAPT = ['APT32', 'APT37', 'DarkHotel', 'Kimsuky', 'Lazarus', '白象', '毒云藤', '蓝宝菇', '蔓灵花', '旺刺', '响尾蛇']var nLink = listLinkReport.lengthvar nAPT = arrAPT.length// ——————————导出文件——————————// Data2File("所有APT报告的标题和URL.csv", listLinkReport)// Data2File("过滤的URL.csv", list2Filter)// ——————————下载文件——————————var iTitle, iURL, iExportvar listLink2Down = []for(var d = 0; d < nLink; d++){iTitle = listLinkReport[d][0]iURL = listLinkReport[d][1]// 遍历是否是下载列表中的组织Loop2FilterAPT2DownLoad:for(var p = 0; p < nAPT; p++){var strAPT = arrAPT[p]if (iTitle.startsWith(strAPT) == true){listLink2Down.push([iTitle, iURL])// console.log(iTitle, "\r\n", iURL)iExport = iURL + "/markdown?attachment=true&latexcode=false&anchor=true&linebreak=true"// console.log("下载链接:", iExport)// 下载代码// window.open(iExport)// 弹窗体验感不好// setTimeout(window.location.href = iExport, 999)// window.location.href = iExport// 多文件不延时下载会重置// selfSleep(999)break Loop2FilterAPT2DownLoad}}}Data2File("11个APT报告的标题和URL.csv", listLink2Down)}// alert("脚本结束")function FilterLinks(iArr){/*for 过滤1. if 过滤1.1 for 保留1.1.1 if (保留){保留后break outer}1.1.2 if (不保留){不保留后break outer}2. if 不过滤2.1 if (次数和数组个数一样){保留}*/var iTitle = iArr[0]var iHref = iArr[1]// 排除的文章var arrURI2Filter = ['toc?tempStore=1', 'toc', 'introduce']// 排除的字符串(前缀)var arrStr2Filter = ['area', 'group', 'theme', 'summary', 'classify']// 不排除的字符串(前缀)var arrStr2Save = ['theme_', 'summary_']// 取最后一个“/”后的字符串var arrSplit = iHref.split("/");var strURI = arrSplit[arrSplit.length-1];if (strURI.length){// alert("切分后元素:" + strURI)var strURL = strBaseURI + "/" + strURI;// URI字符串是否在过滤【文章】数组中var bURIinArr = (arrURI2Filter.indexOf(strURI) != -1)if (bURIinArr){// 在字符串数组中,直接过滤list2Filter.push([iTitle, strURL])}else{// 不在,继续判断// 是否在【过滤前缀】数组中var bInArry = 0var nFilterStr = arrStr2Filter.lengthLoop2Filter:// 排除的字符串(前缀)for(var i = 0; i < nFilterStr; i++){var iStr2Filter = arrStr2Filter[i]if (strURI.startsWith(iStr2Filter)){// 如果前缀需要过滤// 继续判断是否在【不过滤前缀】数组中var nSaveStr = arrStr2Save.lengthvar bInArrySave = 0Loop2Save:for(var j = 0; j < nSaveStr; j++){var iStr2Save = arrStr2Save[j]if (strURI.startsWith(iStr2Save)){// 保留的路径listLinkReport.push([iTitle, strURL])// 跳出外层循环(outer改为Loop)break Loop2Filter}else{bInArrySave += 1}}if (bInArrySave == arrStr2Save.length){// 过滤的路径list2Filter.push([iTitle, strURL])// 跳出外层循环(outer改为Loop)break Loop2Filter}}else{// 不匹配次数bInArry += 1}// 不匹配次数和数组元素个数一致时,才是需要保留的URLif (bInArry == nFilterStr){// 保留的路径listLinkReport.push([iTitle, strURL])}}}}}}, 1666)// 1.666秒后执行//自定义js延时function selfSleep(nTime){var timeNow = Date.now();while((Date.now() - timeNow) <=parseInt(nTime)){};}// 数据保存为文件function Data2File(filename, data){var data2Write = data.join("\n")var elementSaveFile = document.createElement('a')/*以Json格式// elementSaveFile.setAttribute('href', 'data:text/plaincharset=utf-8, ' + JSON.stringify(data))以CSV格式elementSaveFile.setAttribute('href', 'data:text/csv;charset=utf-8,' + data2Write)*/// 以原格式(数组)elementSaveFile.setAttribute('href', 'data:text/plaincharset=utf-8, ' + data2Write)// alert("导出文件开始")// 利用A标签的download属性完成下载文件功能elementSaveFile.setAttribute('download', filename)// 设置为不显示的元素elementSaveFile.style.display = 'none'// 添加A标签元素document.body.appendChild(elementSaveFile)// 触发A标签元素的点击事件elementSaveFile.click()// A标签元素利用后释放document.body.removeChild(elementSaveFile)// alert("导出文件结束")}}
)()
```
建议先从单个导出开始写:
JavaScript - 通过油猴插件添加脚本功能给指定域的URL添加参数 | 一键语雀(单个)文档导出
运行效果
升级
22.03.25
为了能导出别人的知识库,修改脚本执行页面的“@include/@exclude/@match”。
由于在别人的知识库处,无ClassName = “doc-*”的元素,改为在客主知识库页面都有的收藏按键“favor-wrapper”旁。
去掉按钮旁边的边界“.style.border = 'none'”:
去掉前:
22.03.28
越来越漂亮噜🤗🤗🤗

若有收获,就点个赞吧
0 人点赞
