🐍PDF2DOCX🐍
🐍单文件版本🐍
import osimport pathlibfrom pdf2docx import ConvertermsgStart = r"——————————Python脚本开始——————————"msgEnd = r"——————————Python脚本结束——————————"def ChoosePath_Absolute(pathPDF):print("输入PDF文件路径:", pathPDF)# Python脚本目录nameFile = pathlib.Path(pathPDF).stempathDOC = nameFile + ".docx"print("输出DOC文件到Python脚本目录:", pathDOC)PDF2DOC(pathPDF, pathDOC)def ChoosePath_SameDirectory(pathPDF):print("输入PDF文件路径:", pathPDF)# PDF文件同目录(fileDir, fileNameWithExtension) = os.path.split(pathPDF)(fileName, fileExtension) = os.path.splitext(fileNameWithExtension)pathDOC = fileDir + "\\" + fileName + ".docx"print("输出DOC文件到PDD文件目录:", pathDOC)PDF2DOC(pathPDF, pathDOC)def PDF2DOC(pathPDF, pathDOC):converter = Converter(pathPDF)converter.convert(pathDOC, start=0, end=None)converter.close()pathPDF = r"C:\Users\Administrator\Desktop\穷奇.pdf"if __name__ == '__main__':print(msgStart)# 如果需要输入# pathInput = input("请输入PDF文件路径地址:")# print(pathInput)## if pathInput == '':# print("输入为空,使用脚本内置测试路径:", pathPDF)# else:# pathPDF = pathInput# 路径二选一,选一行不用的注释掉# ChoosePath_Absolute(pathPDF)ChoosePath_SameDirectory(pathPDF)print(msgEnd)
🐍文件夹版本🐍
import osfrom pathlib import Pathfrom pdf2docx import ConvertermsgStart = r"——————————Python脚本开始——————————"msgEnd = r"——————————Python脚本结束——————————"strNewLine = "\r\n"def EnuPDFirGetPDFFilePath(pathDir):print("需要遍历的路径:", pathDir, strNewLine)listPathPDF = []# 遍历.PDF文件for filePDF in Path(pathDir).rglob('*.PDF'):# print("PDF:", filePDF)listPathPDF.append(filePDF)# 选择一种路径保存DOCXChoosePath_SameDirectory(filePDF)# ChoosePath_Absolute(filePDF)print("“.PDF”文件列表:")print(listPathPDF)# return listPathPDFdef ChoosePath_Absolute(pathPDF):print("输入PDF文件路径:", pathPDF)# Python脚本目录nameFile = Path(pathPDF).stempathDOC = nameFile + ".docx"print("输出DOC文件到Python脚本目录:", pathDOC)# PDF2DOC(pathPDF, pathDOC)def ChoosePath_SameDirectory(pathPDF):print("输入PDF文件路径:", pathPDF)# PDF文件同目录(fileDir, fileNameWithExtension) = os.path.split(pathPDF)(fileName, fileExtension) = os.path.splitext(fileNameWithExtension)pathDOC = fileDir + "\\" + fileName + ".docx"print("输出DOC文件到PDD文件目录:", pathDOC, strNewLine)# PDF2DOC(pathPDF, pathDOC)def PDF2DOC(pathPDF, pathDOC):converter = Converter(pathPDF)converter.convert(pathDOC, start=0, end=None)converter.close()pathPDF = r"C:\Users\Administrator\Desktop\穷奇.pdf"pathDir = r"C:\Users\Administrator\Desktop"if __name__ == '__main__':print(msgStart)# 如果需要输入pathInput = input("请输入PDF文件路径地址:")print(pathInput)if pathInput == '':print("输入为空,使用默认测试路径:" + strNewLine + pathPDF + strNewLine + pathDir + strNewLine)passelse:pathPDF = pathInputpathDir = pathInput# 遍历文件夹EnuPDFirGetPDFFilePath(pathDir)# 路径二选一,选一行不用的注释掉# ChoosePath_Absolute(pathPDF)# ChoosePath_SameDirectory(pathPDF)print(msgEnd)
3.10Python版本修改
报错
ImportError:cannot import name 'Iterable' from 'collections'
参考
版本>3.7时
pdf2docx\test\Line.py第18行collections添加.abc改为collections.abc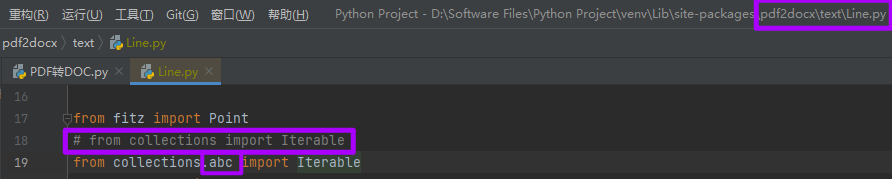

若有收获,就点个赞吧
0 人点赞
