goatest - 一个处理批量数据python脚本的分享
脚本包含功能:json数据转excel文件,自定义正则表达式提取批量数据,两个excel文件进行数据匹配,批量数据的编码解码等。
环境准备
执行脚本提示缺少模块,使用命令‘pip install 模块名’ 或 ‘pip3 install 模块名’即可:
import reimport openpyxlfrom openpyxl import Workbookimport base64from urllib import parseimport pypinyin
功能实现
功能分类
1. json2excel() #从一串josn{}{}中获取到想要的结果,可匹配任意数量的变量,并写入指定的excel文件中2. re2excel() #从文本中使用正则表达式筛选出信息到excel文件中,正则表达式需自定义3. excel2_pipei() #匹配两个excel,以key为匹配参数从excel2中检索信息填写在excel1的某一列中4. encode_decode() #对单条数据或多条数据进行编码解码处理,包含base64,url,unicode,拼音处理
json2excel()
从一串josn{}{}中获取到想要的结果,可匹配任意数量的变量,并写入指定的excel文件中。
使用场景:
通常用于批量数据处理分析、暴力破解快速获得用户名使用。
示例json数据:
{"rows":[{"Id":3170,"UserName":"test1","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183},{"Id":3172,"UserName":"user2","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183},{"Id":3173,"UserName":"user3","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183},{"Id":3174,"UserName":"user4","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183},{"Id":3175,"UserName":"user5","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183},{"Id":3185,"UserName":"user6","CreateDate":"2021-11-12 14:34","RoleName":"测试","RoleId":183}]}
使用方法1-全部提取: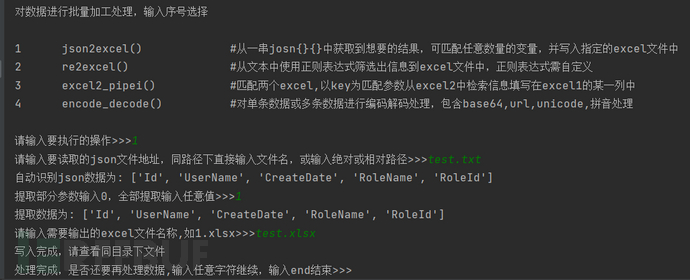
处理结果: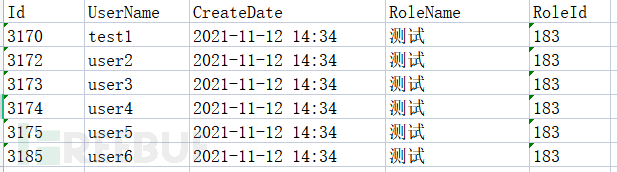 使用方法2-部分提取:
使用方法2-部分提取:
当json数据中一条数据参数过多,而你只想提取某个参数时,使用该方法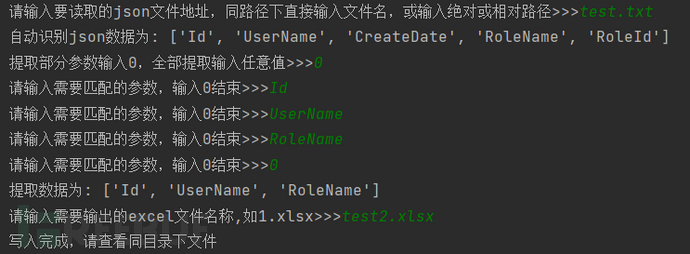
处理结果: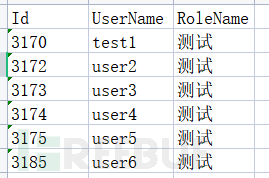
re2excel()
从文本中使用正则表达式筛选出信息到excel文件中,正则表达式需自定义。
使用场景:
对于非json数据,如需批量获得具有类似数据的值,可使用该方法处理,需具备一定正则表达式的知识。
示例处理数据:
<li> <a href="https://www.cnblogs.com/test1">机器学习<span class="tag-count">(72)</span></a> </li> <li> <a href="https://www.cnblogs.com/test2">人工智能<span class="tag-count">(64)</span></a> </li> <li> <a href="https://www.cnblogs.com/test3">前端<span class="tag-count">(21)</span></a> </li>
使用方法:
由于在cmd下直接输入正则表达式容易误输入中文字符,建议现在notepad++上尝试是否能匹配到。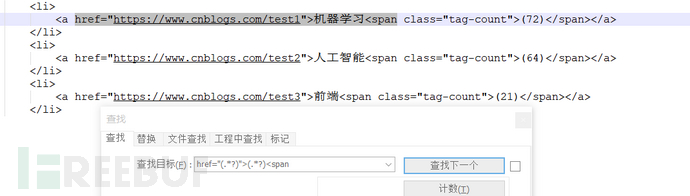
处理结果: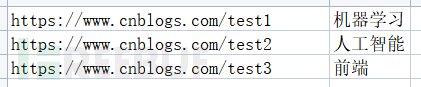 3.3 excel2_pipei()
3.3 excel2_pipei()
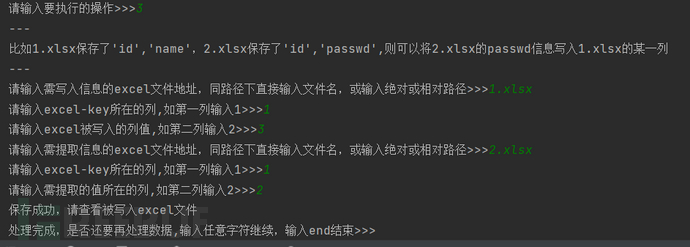
匹配两个excel,以key为匹配参数从excel2中检索信息填写在excel1的某一列中。
使用场景:
excel1保存了id、username,excel2保存了id、password,可使用该方法将两个excel的数据进行匹配,获得比较全的数据,在企业自测口令安全中使用较多。
示例数据:
excel1
| id | username |
|---|---|
| 1001 | 张三 |
| 1002 | 李四 |
| 1003 | 王五 |
excel2
| id | password |
|---|---|
| 1001 | 123456 |
| 1003 | 111111 |

encode_decode()
对单条数据或多条数据进行编码解码处理,包含base64,url,unicode,拼音处理
使用场景:
处于内网环境,无法在线使用编码解码工具,根据姓名输出可能的密码字典
使用方法1-base64编码解码处理: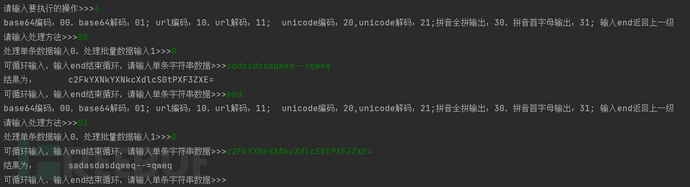
使用方法2-url编码解码处理: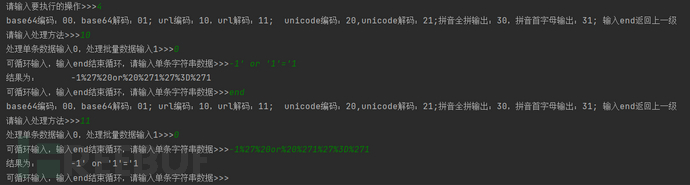
使用方法3-Unicode编码解码处理: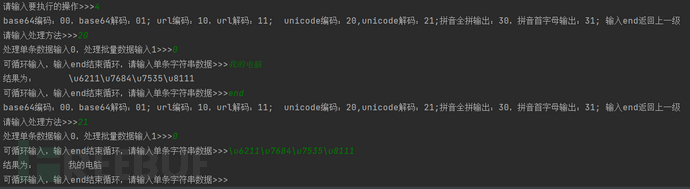 使用方法4-拼音全拼简拼处理:
使用方法4-拼音全拼简拼处理: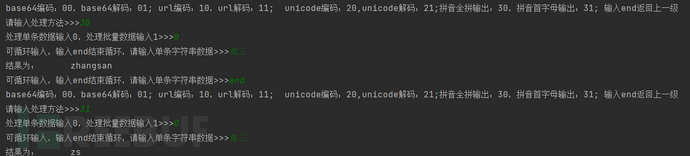
使用方法5-循环输入单条数据: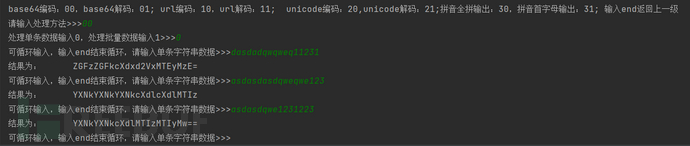
使用方法6-从文本中读取批量数据处理:
整体使用
使用方法:命令台下执行‘python tool_tool.py’ or ‘python3 tool_tool.py’
源代码
由于本人为非专业的开发人员,代码实现上可能会较为繁琐,仅为实现相关功能。
代码上已实现输入参数的校验及循环输入,输出文件保存错误提示,代码小白也可以正常使用,具备较好的友好性。
#!/usr/bin/env python# -*- coding: utf-8 -*-# author:goat time:2021/11/15'''基础函数1 text2list() #从text中读取数据并返回一个list2 list2text() #把list转化为text,可指定间隔符3 listll2excel() #把list[][]按行写入excel4 excel2listll() #把excel转换为list[][]5 base64_url() #base64/url编码解码6 pinyin_list2str() #把字符串进行base64/url等编码解码处理7 encode_decode_io() #循环监听输入的处理方式,直到输入正确'''import reimport openpyxlfrom openpyxl import Workbookimport base64from urllib import parseimport pypinyin'''从text中读取数据并返回一个list'''def text2list(text_path):l = []with open(text_path, encoding='utf-8') as f:text = f.read()for l1 in re.split(r'[\s\n,;]+', text): # 以文本中空格,回车,逗号,顿号为切割符处理l.append(l1)return l'''把list转化为text,可指定间隔符'''def list2text(l, text_path, tag):with open(text_path, 'w', encoding='utf-8') as f:for i in l:f.write(str(i) + tag)'''把二层list[][]按行写入excel'''def listll2excel(ll, excel_path):wb = Workbook()ws = wb.activefor x in ll:ws.append(x)wb.save(excel_path)'''把excel转换为list[][]'''def excel2listll(excel_path, sheet_index=0):wb = openpyxl.load_workbook(excel_path)ws = wb[wb.sheetnames[sheet_index]]total_list = []for row in ws.rows: # ws.rows是一个生成器row_list = []for cell in row: # 直接从行中取每个cellrow_list.append(cell.value)total_list.append(row_list)return total_list'''把pinyin处理的多层list提取出来处理为一个字符串'''def pinyin_list2str(ll, level):s = ''if level == 0:for x in ll:s = s + x[0]elif level == 1:for x in ll:s = s + x[0][0]else:s = '处理错误'return s'''把字符串进行base64/url等编码解码处理'''def base64_url(s, k):if k == '00': # base64编码x = base64.b64encode(s.encode('utf-8')).decode('utf-8')elif k == '01': # base64解码x = base64.b64decode(s.encode('utf-8')).decode('utf-8')elif k == '10': # url编码x = parse.quote(s)elif k == '11': # url解码x = parse.unquote(s)elif k == '20': # unicode编码x = s.encode('unicode_escape').decode('utf-8')elif k == '21': # unicode解码x = s.encode('utf-8').decode('unicode_escape')elif k == '30': # 拼音全拼输出x = pinyin_list2str(pypinyin.pinyin(s, style=pypinyin.NORMAL), 0)elif k == '31': # 拼音首字母输出x = pinyin_list2str(pypinyin.pinyin(s, style=pypinyin.NORMAL), 1)else:x = '测试处理参数输入信息错误!'return x'''循环监听输入的处理方式,直到输入正确'''def encode_decode_io():global kprint('base64编码:00,base64解码:01; url编码:10,url解码:11; unicode编码:20,unicode解码:21;拼音全拼输出:30,拼音首字母输出:31; 输入end返回上一级')in_k = input("请输入处理方法>>>")if in_k in ['00', '01', '10', '11', '20', '21', '30', '31']:k = in_kelif in_k == 'end':main()else:print("参数选取错误!")encode_decode_io() # 自循环等待输入成功message = '''对数据进行批量加工处理,输入序号选择1 json2excel() #从一串josn{}{}中获取到想要的结果,可匹配任意数量的变量,并写入指定的excel文件中2 re2excel() #从文本中使用正则表达式筛选出信息到excel文件中,正则表达式需自定义3 excel2_pipei() #匹配两个excel,以key为匹配参数从excel2中检索信息填写在excel1的某一列中4 encode_decode() #对单条数据或多条数据进行编码解码处理,包含base64,url,unicode,拼音处理''''''从一串josn{}{}中获取到想要的结果,可匹配任意数量的变量,并写入指定excel文件中'''def json2excel():path_du = input("请输入要读取的json文件地址,同路径下直接输入文件名,或输入绝对或相对路径>>>")with open(path_du, 'r', encoding='utf-8') as f: # 读取s = f.read()list_xuqiu = [] # 保存需提取的值json_key = re.findall('{.*?\[({.*?})', s, re.S) # 获取第一个{}list_xuqiu = re.findall('"([a-zA-Z0-9]+)":', json_key[0], re.S) # 获取key值print("自动识别json数据为:", list_xuqiu)auto = input("提取部分参数输入0,全部提取输入任意值>>>")if auto == '0':list_xuqiu = [] # 手动提取时先置空while True == True:xuqiu = input("请输入需要匹配的参数,输入0结束>>>")if xuqiu != '0':list_xuqiu.append(xuqiu)else:breakelif auto == '1':passprint("提取数据为:", list_xuqiu)list_xuqiu_compile = []for i in range(len(list_xuqiu)):list_xuqiu_compile.append(re.compile(str(list_xuqiu[i] + '\":(.*?)[,}]'), re.S))# print(list_xuqiu_compile)#查看匹配集合是否出问题c = re.compile('{.*?}', re.S) # 定位每个框results = re.findall(c, s)# print(results)#查看{}返回结果path_xie = input("请输入需要输出的excel文件名称,如1.xlsx>>>")ll_result = [] # 获取到的结果记录在ll_result中ll_result.append(list_xuqiu) # 把需求参数添加,后续写在excel的第一行for result in results: # 遍历每个框l_result = []for cc in list_xuqiu_compile: # 遍历寻找几个值ccc = re.findall(cc, result)if ccc:l_result.append(re.sub(r'[\"]', '', ccc[0])) # 去除“”包裹else:l_result.append('无')ll_result.append(l_result)# print(ll_result)listll2excel(ll_result, path_xie)print("写入完成,请查看同目录下文件")'''从文本中使用正则表达式筛选出信息到excel文件中,正则表达式需自定义'''def re2excel():path_du = input("请输入要读取的文件地址,同路径下直接输入文件名,或输入绝对或相对路径>>>")with open(path_du, 'r', encoding='utf-8') as f: # 读取s = f.read()str_re = input("请输入自定义正则表达式,请注意中英文字符,建议先在notepad++单条查询尝试>>>")c = re.compile(str_re, re.S)results = re.findall(c, s)# print(results)#查看{}返回结果path_xie = input("请输入需要输出的excel文件名称,如1.xlsx>>>")try:listll2excel(results, path_xie)print("写入完成,请查看同目录下文件")except:print("保存失败,请确认同名文件未被打开")'''匹配两个excel,以key为匹配参数从excel2中检索信息填写在excel1的某一列中'''def excel2_pipei():print("---\n比如1.xlsx保存了'id','name',2.xlsx保存了'id','passwd',则可以将2.xlsx的passwd信息写入1.xlsx的某一列\n---")excel_path1 = input("请输入需写入信息的excel文件地址,同路径下直接输入文件名,或输入绝对或相对路径>>>")l1_key = input("请输入excel-key所在的列,如第一列输入1>>>")l1_value = input("请输入excel被写入的列值,如第二列输入2>>>")l1 = [int(l1_key), int(l1_value)]wb = openpyxl.load_workbook(excel_path1)ws = wb[wb.sheetnames[0]]excel_path2 = input("请输入需提取信息的excel文件地址,同路径下直接输入文件名,或输入绝对或相对路径>>>")l2_key = input("请输入excel-key所在的列,如第一列输入1>>>")l2_value = input("请输入需提取的值所在的列,如第二列输入2>>>")l2 = [int(l2_key), int(l2_value)]ll = excel2listll(excel_path2)dict_index = {}for x in ll:key_s = str(x[l2[0] - 1]).strip() # .strip()去除前后空格value_s = str(x[l2[1] - 1])dict_index[key_s] = value_s# print(dict_index.keys())for r in range(1, ws.max_row + 1):key_ss = str(ws.cell(r, l1[0]).value).strip()if key_ss in dict_index.keys():ws.cell(r, l1[1]).value = str(dict_index[key_ss])# print(key_ss,dict_index[key_ss])else:pass# print(key_ss,"无法匹配")try:wb.save(excel_path1)print("保存成功,请查看被写入excel文件")except:print("保存失败,请关闭被写入信息的excel文件再操作")c = input("请确认关闭文件后,输入任意信息继续保存>>>")if c:print("再次保存,请查看是否保存成功")wb.save(excel_path1)'''对单条数据或多条数据进行编码解码处理,包含base64,url'''def encode_decode():code_way = input("处理单条数据输入0,处理批量数据输入1>>>")if code_way == '0':while True == True:s = input("可循环输入,输入end结束循环,请输入单条字符串数据>>>")if s != 'end':s2 = base64_url(s, k)print("结果为: ", s2)else:encode_decode_io()encode_decode()breakelif code_way == '1':path_du = input("请输入文件名称>>>")l = text2list(path_du)l2 = []for s in l:x = base64_url(s, k)l2.append(x)path_xie = input("处理完成,请输入写入的文件名称>>>")list2text(l2, path_xie, '\n')print("写入完成,请查看文件" + path_xie)else:print("参数选取错误!")encode_decode()'''定义用户输入选择'''k = ''#全局变量k,定义用户的编码处理方式def IO():way = input("请输入要执行的操作>>>")if way == '1':json2excel()elif way == '2':re2excel()elif way == '3':excel2_pipei()elif way == '4':k = ''encode_decode_io() # 循环等待输入成功,将正确的in_k赋值给全局变量Kencode_decode()else:print("参数选取错误!")IO()def main():while True == True:print(message)IO()io = input("处理完成,是否还要再处理数据,输入任意字符继续,输入end结束>>>")if io == 'end':breakif __name__ == '__main__':main()
结语
这是本人的第一次工具分享,实现的功能和方法都比较基础,大佬高抬贵手。文章中部分名词或描述可能存在错误,代码实现可能存在部分缺陷,欢迎讨论和指出。
编写该工具的目的,最开始是因为企业自查弱口令,方便从返回包提取用户名进行暴力破解,再对弱口令账户关联身份信息;暴力破解过程中,部分系统会进行简单编码,并可以通过身份信息构造相应的弱密码字典,在弱口令自查中有奇效;后面是在风控分析中,可手动关联多个excel表,手动分析出异常行为用户(手动的原因当然是目前还没有风控系统)。
一起学Python - 30个极简Python代码

若有收获,就点个赞吧
0 人点赞
