起因
日常中经常会遇到乱码:
网络分析
在线不知道有什么比较好的现成工具解开,那就自己写一个吧。
前置乱码知识
参考
为什么经常会出现这类乱码
虽然国际语言是英语,但大家在自己的国家依然说自已的语言,不过出了国, 你就得会英语 编码也一样,虽然有了UniCode and UTF-8,但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的Windows,默认编码依然是GBK,而不是UTF-8。 基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有GBK编码。 若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 让美国人的电脑上都装上GBK编码
- 把你的软件编码以UTF-8编码
烫烫烫!!!🥵🥵🥵
在C语言中,未初始化的栈空间用0xCC填充,而未初始化的堆空间用0xCD填充。 而0xCCCC和0xCDCD在中文GB2312编码中分别对应“烫”字和“屯”字。
“烫烫烫屯屯屯” 那些事
- 锟斤拷:GBK与UTF-8
- 烫烫烫+屯屯屯:VC++
- 锘锘锘:HTML
乱码恢复指北
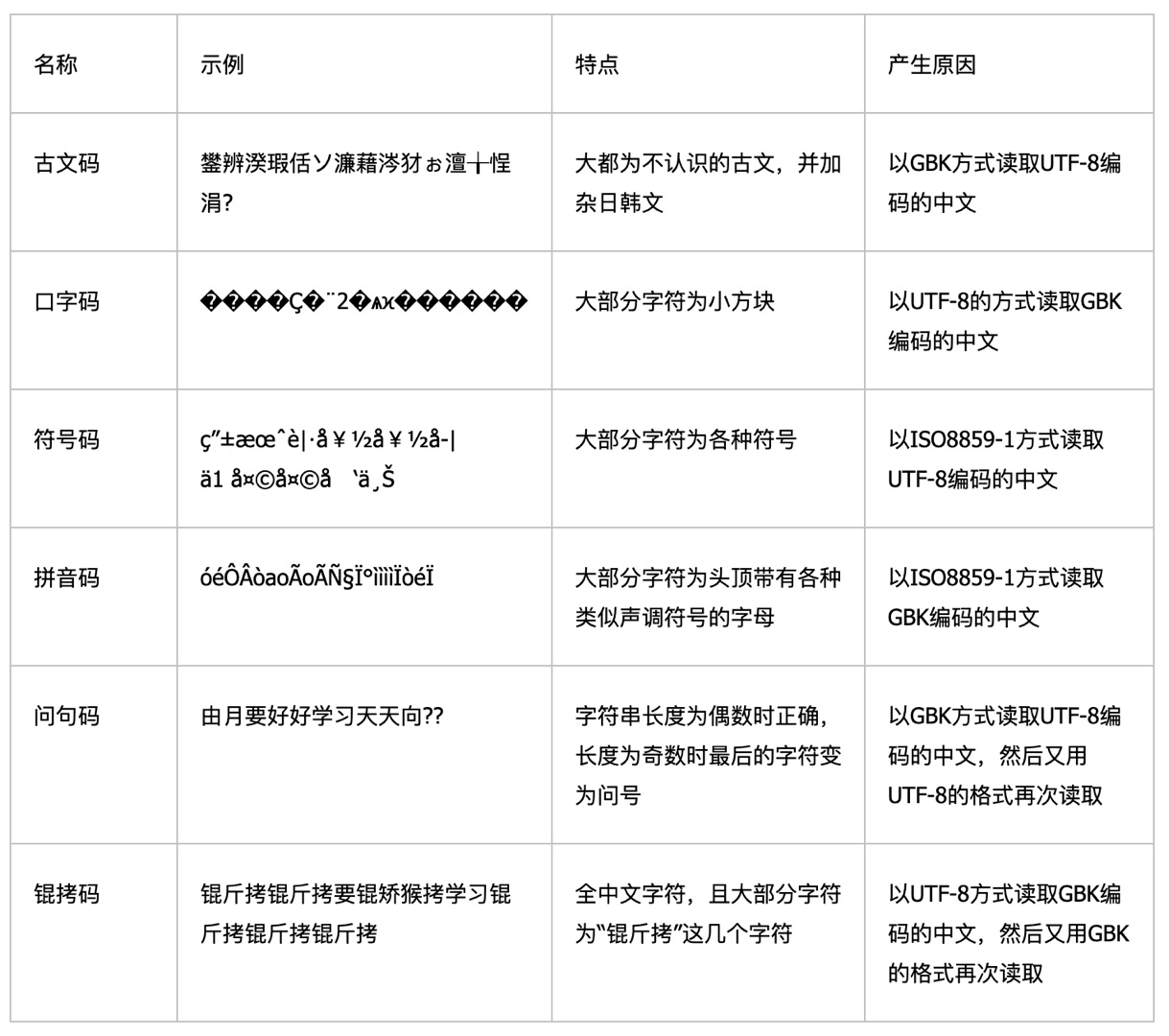
常见编解码错误表(以及能不能恢复)
| 名称 | 举例 | 特点 | 产生原因 | | —- | —- | —- | —- | | 古文码 | 鎴戣兘鍚炰笅鐜荤拑鑰屼笉浼よ韩浣撱 | 大部分为不认识的古文,夹杂日韩文 | 以 GBK 方式读取 UTF-8 编码的中文 | | 这个在上文中提到过。被误以 GBK 和 Big-5 解码经常会得到看起来像中日韩文字的结果。运气好的时候能全部或大部分恢复。 | | | | | 口字码 | ��������������� | 大部分字符为方块 | 以 UTF-8 的方式读取 GBK 编码的中文 | | 这个方块是对不能显示的字符的替换符号,码位是 0xFFFD。通常来说内容是不能恢复的了。 | | | | | 符号码 | 巡音ルカ | 大部分字符为符号 | 以 ISO8859-1 方式读取 UTF-8 编码的中文 | | 拼音码 | ѲÒô¥ë¥« | 大部分字符为头顶带有各种声调符号的字母 | 以 ISO8859-1 方式读取 GBK 编码的中文 | | 上两条指的就是上文中提到的 Windows-1252 的例子。因为多是可见符号,显示上也没什么问题,所以很多时候可以完全恢复。 | | | | | 问句码 | 我能吞下玻璃而不伤身?? | 字符串长度为偶数时正确,字符串长度为奇数时最后的字符变为问号 | 以 GBK 方式读取 UTF-8 编码的中文(然后保存),然后又用 UTF-8 格式再次读取 | | 由于编码特性问题,用 GBK 保存 UTF-8 文档可能会有内容损失。至于那俩问号…只是问号而已,最后的一个字是找不回来的。 | | | | | 锟拷码 | 锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷 | 全中文字符,且大部分字符为锟斤拷这几个字符 | 以 UTF-8 方式读取 GBK 编码的中文,然后又用 GBK 格式再次读取 | | 这个在上文也提到过。显然在这种案例下,内容是不可恢复的了。 | | | |
总结表格(来自网络)
| 名称 | 示例 | 特点 | 原因 |
|---|---|---|---|
| 口字码 | СС�� | 大部分字符是问号小方块 | UTF-8解码GBK编码的中文 |
| 锟拷体 | 锟斤拷小小锟斤拷学习锟斤拷 | 全中文字符,大部分都是”锟斤拷”这几个字符 | GBK解码UTF-8编码的口字码 |
| 古文码 | 灏忓皬鏄庢湀 | 大部分都是生僻字,像古文 | GBK解码UTF-8编码的中文汉字 |
| 问句码 | 小小? | 字符串长度为奇数时,结尾为问号 | GBK遇到不能编码的字符时填充 |
| 符号码 | 好好å\xad¦å¤©å¤©å\xad¦ | 大部分字符为各种符号 | ISO8859-1编码解码UTF-8编码的中文汉字 |
| 拼音码 | ºÃºÃѧϰÌìÌìÏòÉÏ | 大部分字符都是带有声调的字母 | ISO8859-1编码解码GBK编码的中文汉字 |
Python
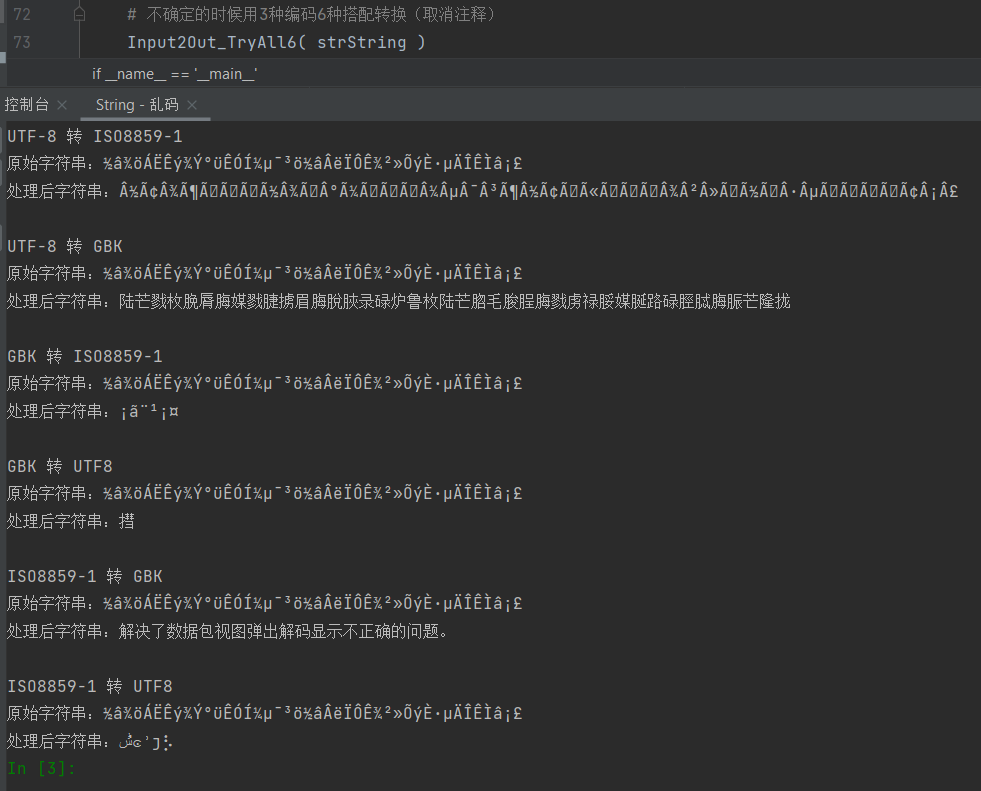
以3种“UTF-8”+“GBK”+“ISO8859-1”常见的编码进行相互转换,一共2*3=6种搭配。
可以指定其中一种,也可以全部都试。
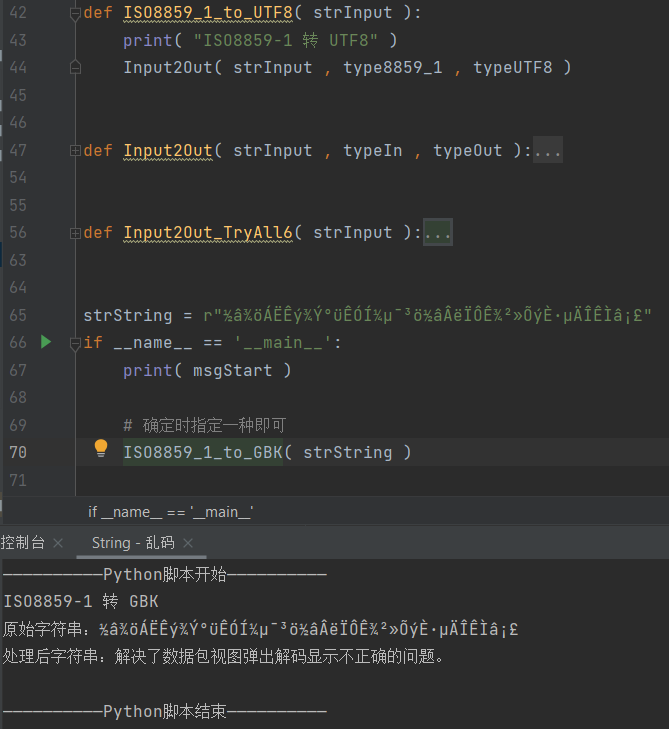
# encoding = UTF-8strLineBreak = "\n"strIgnore = "ignore"msgBefore = "原始字符串:"msgAfter = "处理后字符串:"typeUTF8 = "UTF-8"typeGBK = "GBK"type8859_1 = "ISO8859-1"msgStart = r"——————————Python脚本开始——————————"msgEnd = r"——————————Python脚本结束——————————"def UTF8_2_ISO8859_1( strInput ):print( "UTF-8 转 ISO8859-1" )Input2Out( strInput , typeUTF8 , type8859_1 )def UTF8_2_GBK( strInput ):print( "UTF-8 转 GBK" )Input2Out( strInput , typeUTF8 , typeGBK )def GBK_2_ISO8859_1( strInput ):print( "GBK 转 ISO8859-1" )Input2Out( strInput , typeGBK , type8859_1 )def GBK_2_UTF8( strInput ):print( "GBK 转 UTF8" )Input2Out( strInput , typeGBK , typeUTF8 )def ISO8859_1_to_GBK( strInput ):print( "ISO8859-1 转 GBK" )Input2Out( strInput , type8859_1 , typeGBK )def ISO8859_1_to_UTF8( strInput ):print( "ISO8859-1 转 UTF8" )Input2Out( strInput , type8859_1 , typeUTF8 )def Input2Out( strInput , typeIn , typeOut ):print( msgBefore + strInput )try:strUTF8 = strInput.encode( typeIn , strIgnore ).decode( typeOut , strIgnore )print( msgAfter + strUTF8 + strLineBreak )except (OSError , TypeError , NameError) as infoEx:print( infoEx )def Input2Out_TryAll6( strInput ):UTF8_2_ISO8859_1( strInput )UTF8_2_GBK( strInput )GBK_2_ISO8859_1( strInput )GBK_2_UTF8( strInput )ISO8859_1_to_GBK( strInput )ISO8859_1_to_UTF8( strInput )strString = r"½â¾öÁËÊý¾Ý°üÊÓͼµ¯³ö½âÂëÏÔʾ²»ÕýÈ·µÄÎÊÌâ¡£"if __name__ == '__main__':print( msgStart )# 确定时指定一种即可ISO8859_1_to_GBK( strString )# 不确定的时候用3种编码6种搭配转换(取消注释)# Input2Out_TryAll6( strString )print( msgEnd )
运行效果
指定1种
6种尝试

若有收获,就点个赞吧
0 人点赞
