本章介绍Node.js中的UDP模块,UDP是传输层非面向连接的不可靠协议,使用UDP时,不需要建立连接就可以往对端直接发送数据,减少了三次握手带来的时延,但是UDP的不可靠可能会导致数据丢失,所以比较适合要求时延低,少量丢包不影响整体功能的场景,另外UDP支持多播、端口复用,可以实现一次给多个主机的多个进程发送数据。下面我们开始分析一下UDP的相关内容。
16.1 在C语言中使用UDP
我们首先看一下在C语言中如何使用UDP功能,这是Node.js的底层基础。
16.1.1 服务器流程(伪代码)
// 申请一个socketint fd = socket(...);// 绑定一个众所周知的地址,像TCP一样bind(fd, ip, port);// 直接阻塞等待消息的到来,UDP不需要listenrecvmsg();
16.1.2 客户端流程
客户端的流程有多种方式,原因在于源IP、端口和目的IP、端口可以有多种设置方式。不像服务器一样,服务器端口是需要对外公布的,否则客户端就无法找到目的地进行通信。这就意味着服务器的端口是需要用户显式指定的,而客户端则不然,客户端的IP和端口,用户可以自己指定,也可以由操作系统决定,下面我们看看各种使用方式。
16.1.2.1 显式指定源IP和端口
// 申请一个socketint fd = socket(...);// 绑定一个客户端的地址bind(fd, ip, port);// 给服务器发送数据sendto(fd, 服务器ip,服务器端口, data);
因为UDP不是面向连接的,所以使用UDP时,不需要调用connect建立连接,只要我们知道服务器的地址,直接给服务器发送数据即可。而面向连接的TCP,首先需要通过connect发起三次握手建立连接,建立连接的本质是在客户端和服务器记录对端的信息,这是后面通信的通行证。
16.1.2.2 由操作系统决定源ip和端口
// 申请一个socketint fd = socket(...);// 给服务器发送数据sendto(fd, 服务器ip,服务器端口, data)
我们看到这里没有绑定客户端的源ip和端口,而是直接就给服务器发送数据。如果用户不指定ip和端口,则操作系统会提供默认的源ip和端口。对于ip,如果是多宿主主机,每次调用sendto的时候,操作系统会动态选择源ip。对于端口,操作系统会在第一次调用sendto的时候随机选择一个端口,并且不能修改。另外还有一种使用方式。
// 申请一个socketint fd = socket(...);connect(fd, 服务器ip,服务器端口);/*给服务器发送数据,或者sendto(fd, null,null, data),调用sendto则不需要再指定服务器ip和端口*/write(fd, data);
我们可以先调用connect绑定服务器ip和端口到fd,然后直接调用write发送数据。 虽然使用方式很多,但是归根到底还是对四元组设置的管理。bind是绑定源ip端口到fd,connect是绑定服务器ip端口到fd。对于源ip和端口,我们可以主动设置,也可以让操作系统随机选择。对于目的ip和端口,我们可以在发送数据前设置,也可以在发送数据时设置。这就形成了多种使用方式。
16.1.3 发送数据
我们刚才看到使用UDP之前都需要调用socket函数申请一个socket,虽然调用socket函数返回的是一个fd,但是在操作系统中,的确是新建了一个socket结构体,fd只是一个索引,操作这个fd的时候,操作系统会根据这个fd找到对应的socket。socket是一个非常复杂的结构体,我们可以理解为一个对象。这个对象中有两个属性,一个是读缓冲区大小,一个是写缓冲区大小。当我们发送数据的时候,虽然理论上可以发送任意大小的数据,但是因为受限于发送缓冲区的大小,如果需要发送的数据比当前缓冲区大小大则会导致一些问题,我们分情况分析一下。
1 发送的数据大小比当前缓冲区大,如果设置了非阻塞模式,则返回EAGAIN,如果是阻塞模式,则会引起进程的阻塞。
2 如果发送的数据大小比缓冲区的最大值还大,则会导致报错EMSGSIZE,这时候我们需要分包发送。我们可能会想到修改缓冲区最大值的大小,但是这个大小也是有限制的。 讲完一些边界情况,我们再来看看正常的流程,我们看看发送一个数据包的流程
1 首先在socket的写缓冲区申请一块内存用于数据发送。
2 调用IP层发送接口,如果数据包大小超过了IP层的限制,则需要分包。
3 继续调用底层的接口把数据发到网络上。
因为UDP不是可靠的,所以不需要缓存这个数据包(TCP协议则需要缓存这个数据包,用于超时重传)。 这就是UDP发送数据的流程。
16.1.4 接收数据
当收到一个UDP数据包的时候,操作系统首先会把这个数据包缓存到socket的缓冲区,如果收到的数据包比当前缓冲区大小大,则丢弃数据包,否则把数据包挂载到接收队列,等用户来读取的时候,就逐个摘下接收队列的节点。UDP和TCP不一样,虽然它们都有一个缓存了消息的队列,但是当用户读取数据时,UDP每次只会返回一个UDP数据包,而TCP是会根据用户设置的大小返回一个或多个包里的数据。因为TCP是面向字节流的,而UDP是面向数据包的。
16.2 UDP模块在Node.js中的实现
了解了UDP的一些基础和使用后,我们开始分析在Node.js中是如何使用UDP的,Node.js又是如何实现UDP模块的。
16.2.1 服务器
我们从一个使用例子开始看看UDP模块的使用。
const dgram = require('dgram');// 创建一个UDP服务器const server = dgram.createSocket('udp4');// 监听UDP数据的到来server.on('message', (msg, rinfo) => {// 处理数据});// 绑定端口server.bind(41234);
我们看到创建一个UDP服务器很简单,首先申请一个socket对象,在Node.js中和操作系统中一样,socket是对网络通信的一个抽象,我们可以把它理解成对传输层的抽象,它可以代表TCP也可以代表UDP。我们看一下createSocket做了什么。
function createSocket(type, listener) {return new Socket(type, listener);}function Socket(type, listener) {EventEmitter.call(this);let lookup;let recvBufferSize;let sendBufferSize;let options;if (type !== null && typeof type === 'object') {options = type;type = options.type;lookup = options.lookup;recvBufferSize = options.recvBufferSize;sendBufferSize = options.sendBufferSize;}const handle = newHandle(type, lookup);this.type = type;if (typeof listener === 'function')this.on('message', listener);// 保存上下文this[kStateSymbol] = {handle,receiving: false,// 还没有执行bindbindState: BIND_STATE_UNBOUND,connectState: CONNECT_STATE_DISCONNECTED,queue: undefined,// 端口复用,只使于多播reuseAddr: options && options.reuseAddr,ipv6Only: options && options.ipv6Only,// 发送缓冲区和接收缓冲区大小recvBufferSize,sendBufferSize};}
我们看到一个socket对象是对handle的一个封装。我们看看handle是什么。
function newHandle(type, lookup) {// 用于dns解析的函数,比如我们调send的时候,传的是一个域名if (lookup === undefined) {if (dns === undefined) {dns = require('dns');}lookup = dns.lookup;}if (type === 'udp4') {const handle = new UDP();handle.lookup = lookup4.bind(handle, lookup);return handle;}// 忽略ipv6的处理}
handle又是对UDP模块的封装,UDP是C模块,在之前章节中我们讲过相关的知识,这里就不详细讲述了,当我们在JS层new UDP的时候,会新建一个C对象。
UDPWrap::UDPWrap(Environment* env, Local<Object> object): HandleWrap(env,object,reinterpret_cast<uv_handle_t*>(&handle_),AsyncWrap::PROVIDER_UDPWRAP) {int r = uv_udp_init(env->event_loop(), &handle_);}
执行了uv_udp_init初始化udp对应的handle(uv_udp_t)。我们看一下Libuv的定义。
int uv_udp_init_ex(uv_loop_t* loop, uv_udp_t* handle, unsigned int flags) {int domain;int err;int fd;/* Use the lower 8 bits for the domain */domain = flags & 0xFF;// 申请一个socket,返回一个fdfd = uv__socket(domain, SOCK_DGRAM, 0);uv__handle_init(loop, (uv_handle_t*)handle, UV_UDP);handle->alloc_cb = NULL;handle->recv_cb = NULL;handle->send_queue_size = 0;handle->send_queue_count = 0;/*初始化IO观察者(还没有注册到事件循环的Poll IO阶段),监听的文件描述符是fd,回调是uv__udp_io*/uv__io_init(&handle->io_watcher, uv__udp_io, fd);// 初始化写队列QUEUE_INIT(&handle->write_queue);QUEUE_INIT(&handle->write_completed_queue);return 0;}
就是我们在JS层执行dgram.createSocket(‘udp4’)的时候,在Node.js中主要的执行过程。回到最开始的例子,我们看一下执行bind的时候的逻辑。
Socket.prototype.bind = function(port_, address_ /* , callback */) {let port = port_;// socket的上下文const state = this[kStateSymbol];// 已经绑定过了则报错if (state.bindState !== BIND_STATE_UNBOUND)throw new ERR_SOCKET_ALREADY_BOUND();// 否则标记已经绑定了state.bindState = BIND_STATE_BINDING;// 没传地址则默认绑定所有地址if (!address) {if (this.type === 'udp4')address = '0.0.0.0';elseaddress = '::';}// dns解析后在绑定,如果需要的话state.handle.lookup(address, (err, ip) => {if (err) {state.bindState = BIND_STATE_UNBOUND;this.emit('error', err);return;}const err = state.handle.bind(ip, port || 0, flags);if (err) {const ex = exceptionWithHostPort(err, 'bind', ip, port);state.bindState = BIND_STATE_UNBOUND;this.emit('error', ex);// Todo: close?return;}startListening(this);return this;}
bind函数主要的逻辑是handle.bind和startListening。我们一个个看。我们看一下C++层的bind。
void UDPWrap::DoBind(const FunctionCallbackInfo<Value>& args, int family) {UDPWrap* wrap;ASSIGN_OR_RETURN_UNWRAP(&wrap,args.Holder(),args.GetReturnValue().Set(UV_EBADF));// bind(ip, port, flags)CHECK_EQ(args.Length(), 3);node::Utf8Value address(args.GetIsolate(), args[0]);Local<Context> ctx = args.GetIsolate()->GetCurrentContext();uint32_t port, flags;struct sockaddr_storage addr_storage;int err = sockaddr_for_family(family,address.out(),port,&addr_storage);if (err == 0) {err = uv_udp_bind(&wrap->handle_,reinterpret_cast<const sockaddr*>(&addr_storage),flags);}args.GetReturnValue().Set(err);}
也没有太多逻辑,处理参数然后执行uv_udp_bind设置一些标记、属性和端口复用(端口复用后续会单独分析),然后执行操作系统bind的函数把本端的ip和端口保存到socket中。我们继续看startListening。
function startListening(socket) {const state = socket[kStateSymbol];// 有数据时的回调,触发message事件state.handle.onmessage = onMessage;// 重点,开始监听数据state.handle.recvStart();state.receiving = true;state.bindState = BIND_STATE_BOUND;// 设置操作系统的接收和发送缓冲区大小if (state.recvBufferSize)bufferSize(socket, state.recvBufferSize, RECV_BUFFER);if (state.sendBufferSize)bufferSize(socket, state.sendBufferSize, SEND_BUFFER);socket.emit('listening');}
重点是recvStart函数,我们看C++的实现。
void UDPWrap::RecvStart(const FunctionCallbackInfo<Value>& args) {UDPWrap* wrap;ASSIGN_OR_RETURN_UNWRAP(&wrap,args.Holder(),args.GetReturnValue().Set(UV_EBADF));int err = uv_udp_recv_start(&wrap->handle_, OnAlloc, OnRecv);// UV_EALREADY means that the socket is already bound but that's okayif (err == UV_EALREADY)err = 0;args.GetReturnValue().Set(err);}
OnAlloc, OnRecv分别是分配内存接收数据的函数和数据到来时执行的回调。继续看Libuv
int uv__udp_recv_start(uv_udp_t* handle,uv_alloc_cb alloc_cb,uv_udp_recv_cb recv_cb) {int err;err = uv__udp_maybe_deferred_bind(handle, AF_INET, 0);if (err)return err;// 保存一些上下文handle->alloc_cb = alloc_cb;handle->recv_cb = recv_cb;// 注册IO观察者到loop,如果事件到来,等到Poll IO阶段处理uv__io_start(handle->loop, &handle->io_watcher, POLLIN);uv__handle_start(handle);return 0;}
uv__udp_recv_start主要是注册IO观察者到loop,等待事件到来的时候,到这,服务器就启动了。
16.2.2 客户端
接着我们看一下客户端的使用方式和流程
const dgram = require('dgram');const message = Buffer.from('Some bytes');const client = dgram.createSocket('udp4');client.connect(41234, 'localhost', (err) => {client.send(message, (err) => {client.close();});});
我们看到Node.js首先调用connect绑定服务器的地址,然后调用send发送信息,最后调用close。我们一个个分析。首先看connect。
Socket.prototype.connect = function(port, address, callback) {port = validatePort(port);// 参数处理if (typeof address === 'function') {callback = address;address = '';} else if (address === undefined) {address = '';}const state = this[kStateSymbol];// 不是初始化状态if (state.connectState !== CONNECT_STATE_DISCONNECTED)throw new ERR_SOCKET_DGRAM_IS_CONNECTED();// 设置socket状态state.connectState = CONNECT_STATE_CONNECTING;// 还没有绑定客户端地址信息,则先绑定随机地址(操作系统决定)if (state.bindState === BIND_STATE_UNBOUND)this.bind({ port: 0, exclusive: true }, null);// 执行bind的时候,state.bindState不是同步设置的if (state.bindState !== BIND_STATE_BOUND) {enqueue(this, _connect.bind(this, port, address, callback));return;}_connect.call(this, port, address, callback);};
这里分为两种情况,一种是在connect之前已经调用了bind,第二种是没有调用bind,如果没有调用bind,则在connect之前先要调用bind(因为bind中不仅仅绑定了ip端口,还有端口复用的处理)。这里只分析没有调用bind的情况,因为这是最长的路径。bind刚才我们分析过了,我们从以下代码继续分析
if (state.bindState !== BIND_STATE_BOUND) {enqueue(this, _connect.bind(this, port, address, callback));return;}
enqueue把任务加入任务队列,并且监听了listening事件(该事件在bind成功后触发)。
function enqueue(self, toEnqueue) {const state = self[kStateSymbol];if (state.queue === undefined) {state.queue = [];self.once('error', onListenError);self.once('listening', onListenSuccess);}state.queue.push(toEnqueue);}
这时候connect函数就执行完了,等待bind成功后(nextTick)会执行 startListening函数。
function startListening(socket) {const state = socket[kStateSymbol];state.handle.onmessage = onMessage;// 注册等待可读事件state.handle.recvStart();state.receiving = true;// 标记已bind成功state.bindState = BIND_STATE_BOUND;// 设置读写缓冲区大小if (state.recvBufferSize)bufferSize(socket, state.recvBufferSize, RECV_BUFFER);if (state.sendBufferSize)bufferSize(socket, state.sendBufferSize, SEND_BUFFER);// 触发listening事件socket.emit('listening');}
我们看到startListening触发了listening事件,从而执行我们刚才入队的回调onListenSuccess。
function onListenSuccess() {this.removeListener('error', onListenError);clearQueue.call(this);}function clearQueue() {const state = this[kStateSymbol];const queue = state.queue;state.queue = undefined;for (const queueEntry of queue)queueEntry();}
回调就是把队列中的回调执行一遍,connect函数设置的回调是_connect。
function _connect(port, address, callback) {const state = this[kStateSymbol];if (callback)this.once('connect', callback);const afterDns = (ex, ip) => {defaultTriggerAsyncIdScope(this[async_id_symbol],doConnect,ex, this, ip, address, port, callback);};state.handle.lookup(address, afterDns);}
这里的address是服务器地址,_connect函数主要逻辑是
1 监听connect事件
2 对服务器地址进行dns解析(只能是本地的配的域名)。解析成功后执行afterDns,最后执行doConnect,并传入解析出来的ip。我们看看doConnect
function doConnect(ex, self, ip, address, port, callback) {const state = self[kStateSymbol];// dns解析成功,执行底层的connectif (!ex) {const err = state.handle.connect(ip, port);if (err) {ex = exceptionWithHostPort(err, 'connect', address, port);}}// connect成功,触发connect事件state.connectState = CONNECT_STATE_CONNECTED;process.nextTick(() => self.emit('connect'));}
connect函数通过C++层,然后调用Libuv,到操作系统的connect。作用是把服务器地址保存到socket中。connect的流程就走完了。接下来我们就可以调用send和recv发送和接收数据。
16.2.3 发送数据
发送数据接口是sendto,它是对send的封装。
Socket.prototype.send = function(buffer,offset,length,port,address,callback) {let list;const state = this[kStateSymbol];const connected = state.connectState === CONNECT_STATE_CONNECTED;// 没有调用connect绑定过服务端地址,则需要传服务端地址信息if (!connected) {if (address || (port && typeof port !== 'function')) {buffer = sliceBuffer(buffer, offset, length);} else {callback = port;port = offset;address = length;}} else {if (typeof length === 'number') {buffer = sliceBuffer(buffer, offset, length);if (typeof port === 'function') {callback = port;port = null;}} else {callback = offset;}// 已经绑定了服务端地址,则不能再传了if (port || address)throw new ERR_SOCKET_DGRAM_IS_CONNECTED();}// 如果没有绑定服务器端口,则这里需要传,并且校验if (!connected)port = validatePort(port);// 忽略一些参数处理逻辑// 没有绑定客户端地址信息,则需要先绑定,值由操作系统决定if (state.bindState === BIND_STATE_UNBOUND)this.bind({ port: 0, exclusive: true }, null);// bind还没有完成,则先入队,等待bind完成再执行if (state.bindState !== BIND_STATE_BOUND) {enqueue(this, this.send.bind(this,list,port,address,callback));return;}// 已经绑定了,设置服务端地址后发送数据const afterDns = (ex, ip) => {defaultTriggerAsyncIdScope(this[async_id_symbol],doSend,ex, this, ip, list, address, port, callback);};// 传了地址则可能需要dns解析if (!connected) {state.handle.lookup(address, afterDns);} else {afterDns(null, null);}}
我们继续看doSend函数。
function doSend(ex, self, ip, list, address, port, callback) {const state = self[kStateSymbol];// dns解析出错if (ex) {if (typeof callback === 'function') {process.nextTick(callback, ex);return;}process.nextTick(() => self.emit('error', ex));return;}// 定义一个请求对象const req = new SendWrap();req.list = list; // Keep reference alive.req.address = address;req.port = port;/*设置Node.js和用户的回调,oncomplete由C++层调用,callback由oncomplete调用*/if (callback) {req.callback = callback;req.oncomplete = afterSend;}let err;// 根据是否需要设置服务端地址,调C++层函数if (port)err = state.handle.send(req, list, list.length, port, ip, !!callback);elseerr = state.handle.send(req, list, list.length, !!callback);/*err大于等于1说明同步发送成功了,直接执行回调,否则等待异步回调*/if (err >= 1) {if (callback)process.nextTick(callback, null, err - 1);return;}// 发送失败if (err && callback) {const ex=exceptionWithHostPort(err, 'send', address, port);process.nextTick(callback, ex);}}
我们穿过C++层,直接看Libuv的代码。
int uv__udp_send(uv_udp_send_t* req,uv_udp_t* handle,const uv_buf_t bufs[],unsigned int nbufs,const struct sockaddr* addr,unsigned int addrlen,uv_udp_send_cb send_cb) {int err;int empty_queue;assert(nbufs > 0);// 还没有绑定服务端地址,则绑定if (addr) {err = uv__udp_maybe_deferred_bind(handle,addr->sa_family,0);if (err)return err;}// 当前写队列是否为空empty_queue = (handle->send_queue_count == 0);// 初始化一个写请求uv__req_init(handle->loop, req, UV_UDP_SEND);if (addr == NULL)req->addr.ss_family = AF_UNSPEC;elsememcpy(&req->addr, addr, addrlen);// 保存上下文req->send_cb = send_cb;req->handle = handle;req->nbufs = nbufs;// 初始化数据,预分配的内存不够,则分配新的堆内存req->bufs = req->bufsml;if (nbufs > ARRAY_SIZE(req->bufsml))req->bufs = uv__malloc(nbufs * sizeof(bufs[0]));// 复制过去堆中memcpy(req->bufs, bufs, nbufs * sizeof(bufs[0]));// 更新写队列数据handle->send_queue_size += uv__count_bufs(req->bufs,req->nbufs);handle->send_queue_count++;// 插入写队列,等待可写事件的发生QUEUE_INSERT_TAIL(&handle->write_queue, &req->queue);uv__handle_start(handle);// 当前写队列为空,则直接开始写,否则设置等待可写队列if (empty_queue &&!(handle->flags & UV_HANDLE_UDP_PROCESSING)) {// 发送数据uv__udp_sendmsg(handle);// 写队列是否非空,则设置等待可写事件,可写的时候接着写if (!QUEUE_EMPTY(&handle->write_queue))uv__io_start(handle->loop, &handle->io_watcher, POLLOUT);} else {uv__io_start(handle->loop, &handle->io_watcher, POLLOUT);}return 0;}
该函数首先记录写请求的上下文,然后把写请求插入写队列中,当待写队列为空,则直接执行uvudp_sendmsg进行写操作,否则等待可写事件的到来,当可写事件触发的时候,执行的函数是uvudp_io。
static void uv__udp_io(uv_loop_t* loop, uv__io_t* w, unsigned int revents) {uv_udp_t* handle;if (revents & POLLOUT) {uv__udp_sendmsg(handle);uv__udp_run_completed(handle);}}
我们先看uv__udp_sendmsg
static void uv__udp_sendmsg(uv_udp_t* handle) {uv_udp_send_t* req;QUEUE* q;struct msghdr h;ssize_t size;// 逐个节点发送while (!QUEUE_EMPTY(&handle->write_queue)) {q = QUEUE_HEAD(&handle->write_queue);req = QUEUE_DATA(q, uv_udp_send_t, queue);memset(&h, 0, sizeof h);// 忽略参数处理h.msg_iov = (struct iovec*) req->bufs;h.msg_iovlen = req->nbufs;do {size = sendmsg(handle->io_watcher.fd, &h, 0);} while (size == -1 && errno == EINTR);if (size == -1) {// 繁忙则先不发了,等到可写事件if (errno == EAGAIN || errno == EWOULDBLOCK || errno == ENOBUFS)break;}// 记录发送结果req->status = (size == -1 ? UV__ERR(errno) : size);// 发送“完”移出写队列QUEUE_REMOVE(&req->queue);// 加入写完成队列QUEUE_INSERT_TAIL(&handle->write_completed_queue, &req->queue);/*有节点数据写完了,把IO观察者插入pending队列,pending阶段执行回调uv__udp_io*/uv__io_feed(handle->loop, &handle->io_watcher);}}
该函数遍历写队列,然后逐个发送节点中的数据,并记录发送结果。
1 如果写繁忙则结束写逻辑,等待下一次写事件触发。
2 如果写成功则把节点插入写完成队列中,并且把IO观察者插入pending队列。
等待pending阶段执行回调时,执行的函数是uvudp_io。 我们再次回到uvudp_io中
if (revents & POLLOUT) {uv__udp_sendmsg(handle);uv__udp_run_completed(handle);}
我们看到这时候会继续执行数据发送的逻辑,然后处理写完成队列。我们看uv__udp_run_completed。
static void uv__udp_run_completed(uv_udp_t* handle) {uv_udp_send_t* req;QUEUE* q;handle->flags |= UV_HANDLE_UDP_PROCESSING;// 逐个节点处理while (!QUEUE_EMPTY(&handle->write_completed_queue)) {q = QUEUE_HEAD(&handle->write_completed_queue);QUEUE_REMOVE(q);req = QUEUE_DATA(q, uv_udp_send_t, queue);uv__req_unregister(handle->loop, req);// 更新待写数据大小handle->send_queue_size -= uv__count_bufs(req->bufs, req->nbufs);handle->send_queue_count--;// 如果重新申请了堆内存,则需要释放if (req->bufs != req->bufsml)uv__free(req->bufs);req->bufs = NULL;if (req->send_cb == NULL)continue;// 执行回调if (req->status >= 0)req->send_cb(req, 0);elsereq->send_cb(req, req->status);}// 写队列为空,则注销等待可写事件if (QUEUE_EMPTY(&handle->write_queue)) {uv__io_stop(handle->loop, &handle->io_watcher, POLLOUT);if (!uv__io_active(&handle->io_watcher, POLLIN))uv__handle_stop(handle);}handle->flags &= ~UV_HANDLE_UDP_PROCESSING;}
这就是发送的逻辑,发送完后Libuv会调用C++回调,最后回调JS层回调。具体到操作系统也是类似的实现,操作系统首先判断数据的大小是否小于写缓冲区,是的话申请一块内存,然后构造UDP协议数据包,再逐层往下调,最后发送出来,但是如果数据超过了底层的报文大小限制,则会被分片。
16.2.4 接收数据
UDP服务器启动的时候,就注册了等待可读事件的发送,如果收到了数据,则在Poll IO阶段就会被处理。前面我们讲过,回调函数是uv__udp_io。我们看一下事件触发的时候,该函数怎么处理的。
static void uv__udp_io(uv_loop_t* loop, uv__io_t* w, unsigned int revents) {uv_udp_t* handle;handle = container_of(w, uv_udp_t, io_watcher);// 可读事件触发if (revents & POLLIN)uv__udp_recvmsg(handle);}
我们看uv__udp_recvmsg的逻辑。
static void uv__udp_recvmsg(uv_udp_t* handle) {struct sockaddr_storage peer;struct msghdr h;ssize_t nread;uv_buf_t buf;int flags;int count;count = 32;do {// 分配内存接收数据,C++层设置的buf = uv_buf_init(NULL, 0);handle->alloc_cb((uv_handle_t*) handle, 64 * 1024, &buf);memset(&h, 0, sizeof(h));memset(&peer, 0, sizeof(peer));h.msg_name = &peer;h.msg_namelen = sizeof(peer);h.msg_iov = (void*) &buf;h.msg_iovlen = 1;// 调操作系统的函数读取数据do {nread = recvmsg(handle->io_watcher.fd, &h, 0);}while (nread == -1 && errno == EINTR);// 调用C++层回调handle->recv_cb(handle,nread,&buf,(const struct sockaddr*) &peer,flags);}}
最终通过操作系统调用recvmsg读取数据,操作系统收到一个udp数据包的时候,会挂载到socket的接收队列,如果接收队列满了则会丢弃,当用户调用recvmsg函数的时候,操作系统就把接收队列中节点逐个返回给用户。读取完后,Libuv会回调C层,然后C层回调到JS层,最后触发message事件,这就是对应开始那段代码的message事件。
16.2.5 多播
我们知道,TCP是基于连接和可靠的,多播则会带来过多的连接和流量,所以TCP是不支持多播的,而UDP则支持多播。多播分为局域网多播和广域网多播,我们知道在局域网内发生一个数据,是会以广播的形式发送到各个主机的,主机根据目的地址判断是否需要处理该数据包。如果UDP是单播的模式,则只会有一个主机会处理该数据包。如果UDP是多播的模式,则有多个主机处理该数据包。多播的时候,存在一个多播组的概念,这就是IGMP做的事情。它定义了组的概念。只有加入这个组的主机才能处理该组的数据包。假设有以下局域网,如图16-1所示。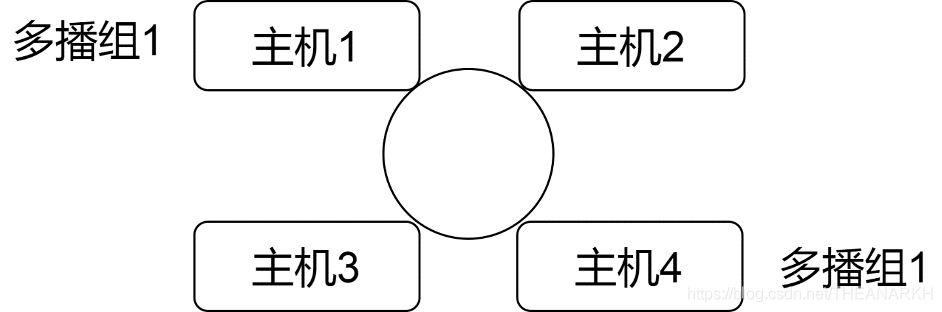
图16-1
当主机1给多播组1发送数据的时候,主机4可以收到,主机2,3则无法收到。
我们再来看看广域网的多播。广域网的多播需要路由器的支持,多个路由器之间会使用多播路由协议交换多播组的信息。假设有以下广域网,如图16-2所示。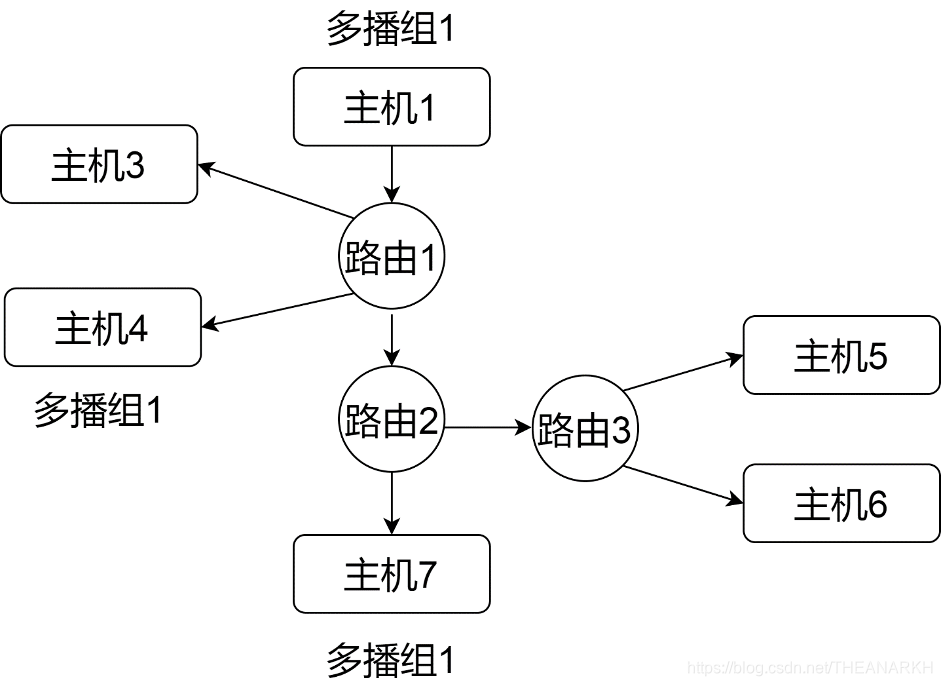
图16-2
当主机1给多播组1发送数据的时候,路由器1会给路由器2发送一份数据(通过多播路由协议交换了信息,路由1知道路由器2的主机7在多播组1中),但是路由器2不会给路由器3发送数据,因为它知道路由器3对应的网络中没有主机在多播组1。
以上是多播的一些概念。Node.js中关于多播的实现,基本是对操作系统API的封装,所以就不打算讲解,我们直接看操作系统中对于多播的实现。
16.2.5.1 加入一个多播组
可以通过以下接口加入一个多播组。
setsockopt(fd,IPPROTO_IP,IP_ADD_MEMBERSHIP,&mreq, // 记录出口ip和加入多播组的ipsizeof(mreq));
mreq的结构体定义如下
struct ip_mreq{// 加入的多播组ipstruct in_addr imr_multiaddr;// 出口ipstruct in_addr imr_interface;};
我们看一下setsockopt的实现(只列出相关部分代码)
case IP_ADD_MEMBERSHIP:{struct ip_mreq mreq;static struct options optmem;unsigned long route_src;struct rtable *rt;struct device *dev=NULL;err=verify_area(VERIFY_READ, optval, sizeof(mreq));memcpy_fromfs(&mreq,optval,sizeof(mreq));// 没有设置device则根据多播组ip选择一个deviceif(mreq.imr_interface.s_addr==INADDR_ANY){if((rt=ip_rt_route(mreq.imr_multiaddr.s_addr,&optmem, &route_src))!=NULL){dev=rt->rt_dev;rt->rt_use--;}}else{// 根据设置的ip找到对应的devicefor(dev = dev_base; dev; dev = dev->next){// 在工作状态、支持多播,ip一样if((dev->flags&IFF_UP)&&(dev->flags&IFF_MULTICAST)&&(dev->pa_addr==mreq.imr_interface.s_addr))break;}}// 加入多播组return ip_mc_join_group(sk,dev,mreq.imr_multiaddr.s_addr);}
首先拿到加入的多播组IP和出口IP对应的device后,调用ip_mc_join_group,在socket结构体中,有一个字段维护了该socket加入的多播组信息,如图16-3所示。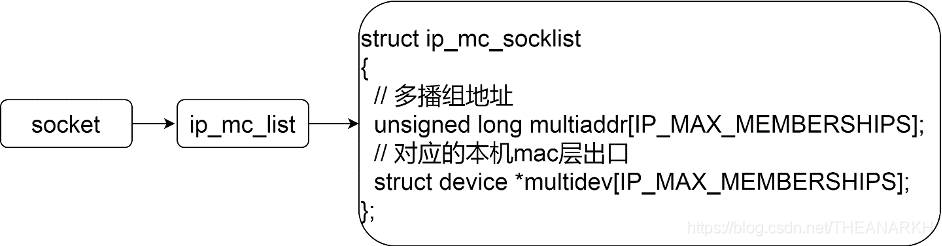
图16-3
我们接着看一下ip_mc_join_group
int ip_mc_join_group(struct sock *sk ,struct device *dev,unsigned long addr){int unused= -1;int i;// 还没有加入过多播组则分配一个ip_mc_socklist结构体if(sk->ip_mc_list==NULL){if((sk->ip_mc_list=(struct ip_mc_socklist *)kmalloc(sizeof(*sk->ip_mc_list), GFP_KERNEL))==NULL)return -ENOMEM;memset(sk->ip_mc_list,'\0',sizeof(*sk->ip_mc_list));}// 遍历加入的多播组队列,判断是否已经加入过for(i=0;i<IP_MAX_MEMBERSHIPS;i++){if(sk->ip_mc_list->multiaddr[i]==addr &&sk->ip_mc_list->multidev[i]==dev)return -EADDRINUSE;if(sk->ip_mc_list->multidev[i]==NULL)// 记录可用位置的索引unused=i;}// 到这说明没有加入过当前设置的多播组,则记录并且加入if(unused==-1)return -ENOBUFS;sk->ip_mc_list->multiaddr[unused]=addr;sk->ip_mc_list->multidev[unused]=dev;// addr为多播组ipip_mc_inc_group(dev,addr);return 0;}
ip_mc_join_group函数的主要逻辑是把socket想加入的多播组信息记录到socket的ip_mc_list字段中(如果还没有加入过该多播组的话)。接着调ip_mc_inc_group往下走。device的ip_mc_list字段维护了主机中使用了该device的多播组信息,如图16-4所示。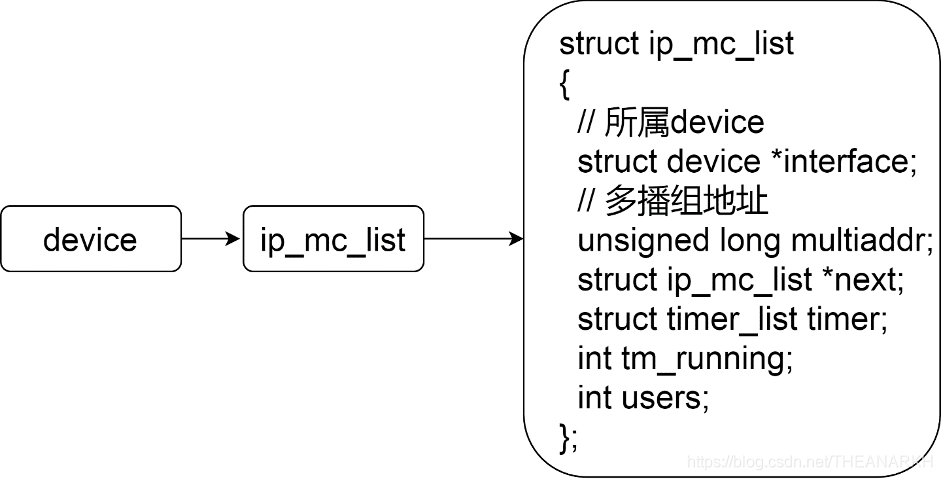
图16-4
static void ip_mc_inc_group(struct device *dev,unsigned long addr){struct ip_mc_list *i;/*遍历该设备维护的多播组队列,判断是否已经有socket加入过该多播组,是则引用数加一*/for(i=dev->ip_mc_list;i!=NULL;i=i->next){if(i->multiaddr==addr){i->users++;return;}}// 到这说明,还没有socket加入过当前多播组,则记录并加入i=(struct ip_mc_list *)kmalloc(sizeof(*i), GFP_KERNEL);if(!i)return;i->users=1;i->interface=dev;i->multiaddr=addr;i->next=dev->ip_mc_list;// 通过igmp通知其它方igmp_group_added(i);dev->ip_mc_list=i;}
ip_mc_inc_group函数的主要逻辑是判断socket想要加入的多播组是不是已经存在于当前device中,如果不是则新增一个节点。继续调用igmp_group_added
static void igmp_group_added(struct ip_mc_list *im){// 初始化定时器igmp_init_timer(im);/*发送一个igmp数据包,同步多播组信息(socket加入了一个新的多播组)*/igmp_send_report(im->interface,im->multiaddr,IGMP_HOST_MEMBERSHIP_REPORT);// 转换多播组ip到多播mac地址,并记录到device中ip_mc_filter_add(im->interface, im->multiaddr);}
我们看看igmp_send_report和ip_mc_filter_add的具体逻辑。
static void igmp_send_report(struct device *dev,unsigned long address,int type){// 申请一个skb表示一个数据包struct sk_buff *skb=alloc_skb(MAX_IGMP_SIZE, GFP_ATOMIC);int tmp;struct igmphdr *igh;/*构建ip头,ip协议头的源ip是INADDR_ANY,即随机选择一个本机的,目的ip为多播组ip(address)*/tmp=ip_build_header(skb,INADDR_ANY,address,&dev,IPPROTO_IGMP,NULL,skb->mem_len, 0, 1);/*data表示所有的数据部分,tmp表示ip头大小,所以igh就是ip协议的数据部分,即igmp报文的内容*/igh=(struct igmphdr *)(skb->data+tmp);skb->len=tmp+sizeof(*igh);igh->csum=0;igh->unused=0;igh->type=type;igh->group=address;igh->csum=ip_compute_csum((void *)igh,sizeof(*igh));// 调用ip层发送出去ip_queue_xmit(NULL,dev,skb,1);}
igmp_send_report其实就是构造一个IGMP协议数据包,然后发送出去,告诉路由器某个主机加入了多播组,IGMP的协议格式如下
struct igmphdr{// 类型unsigned char type;unsigned char unused;// 校验和unsigned short csum;// igmp的数据部分,比如加入多播组的时候,group表示多播组ipunsigned long group;};
接着我们看ip_mc_filter_add
void ip_mc_filter_add(struct device *dev, unsigned long addr){char buf[6];// 把多播组ip转成mac多播地址addr=ntohl(addr);buf[0]=0x01;buf[1]=0x00;buf[2]=0x5e;buf[5]=addr&0xFF;addr>>=8;buf[4]=addr&0xFF;addr>>=8;buf[3]=addr&0x7F;dev_mc_add(dev,buf,ETH_ALEN,0);}
我们知道IP地址是32位,mac地址是48位,但是IANA规定,IP V4组播MAC地址的高24位是0x01005E,第25位是0,低23位是ipv4组播地址的低23位。而多播的IP地址高四位固定是1110。另外低23位被映射到MAC多播地址的23位,所以多播IP地址中,有5位是可以随机组合的。这就意味着,每32个多播IP地址,映射到一个MAC地址。这会带来一些问题,假设主机x加入了多播组a,主机y加入了多播组b,而a和b对应的mac多播地址是一样的。当主机z给多播组a发送一个数据包的时候,这时候主机x和y的网卡都会处理该数据包,并上报到上层,但是多播组a对应的MAC多播地址和多播组b是一样的。我们拿到一个多播组ip的时候,可以计算出它的多播MAC地址,但是反过来就不行,因为一个多播mac地址对应了32个多播ip地址。那主机x和y怎么判断是不是发给自己的数据包?因为device维护了一个本device上的多播IP列表,操作系统根据收到的数据包中的IP目的地址和device的多播IP列表对比。如果在列表中,则说明是发给自己的。最后我们看看dev_mc_add。device中维护了当前的mac多播地址列表,它会把这个列表信息同步到网卡中,使得网卡可以处理该列表中多播mac地址的数据包,如图16-5所示。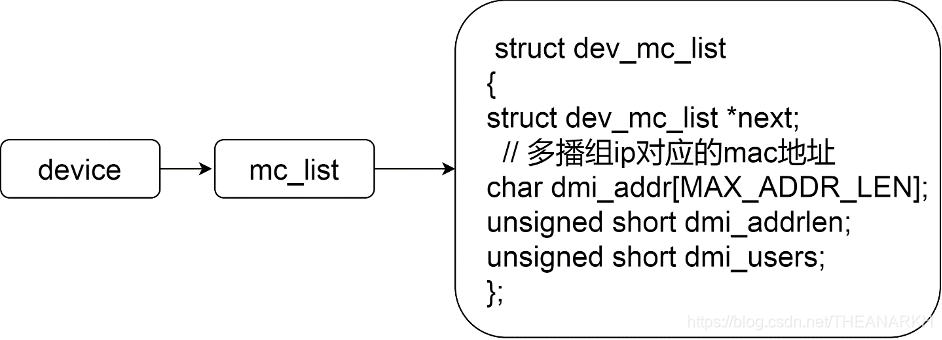
图16-5
void dev_mc_add(struct device *dev, void *addr, int alen, int newonly){struct dev_mc_list *dmi;// device维护的多播mac地址列表for(dmi=dev->mc_list;dmi!=NULL;dmi=dmi->next){// 已存在,则引用计数加一if(memcmp(dmi->dmi_addr,addr,dmi->dmi_addrlen)==0 &&dmi->dmi_addrlen==alen){if(!newonly)dmi->dmi_users++;return;}}// 不存在则新增一个项到device列表中dmi=(struct dev_mc_list *)kmalloc(sizeof(*dmi),GFP_KERNEL);memcpy(dmi->dmi_addr, addr, alen);dmi->dmi_addrlen=alen;dmi->next=dev->mc_list;dmi->dmi_users=1;dev->mc_list=dmi;dev->mc_count++;// 通知网卡需要处理该多播mac地址dev_mc_upload(dev);}
网卡的工作模式有几种,分别是正常模式(只接收发给自己的数据包)、混杂模式(接收所有数据包)、多播模式(接收一般数据包和多播数据包)。网卡默认是只处理发给自己的数据包,所以当我们加入一个多播组的时候,我们需要告诉网卡,当收到该多播组的数据包时,需要处理,而不是忽略。dev_mc_upload函数就是通知网卡。
void dev_mc_upload(struct device *dev){struct dev_mc_list *dmi;char *data, *tmp;// 不工作了if(!(dev->flags&IFF_UP))return;/*当前是混杂模式,则不需要设置多播了,因为网卡会处理所有收到的数据,不管是不是发给自己的*/if(dev->flags&IFF_PROMISC){dev->set_multicast_list(dev, -1, NULL);return;}/*多播地址个数,为0,则设置网卡工作模式为正常模式,因为不需要处理多播了*/if(dev->mc_count==0){dev->set_multicast_list(dev,0,NULL);return;}data=kmalloc(dev->mc_count*dev->addr_len, GFP_KERNEL);// 复制所有的多播mac地址信息for(tmp = data, dmi=dev->mc_list;dmi!=NULL;dmi=dmi->next){memcpy(tmp,dmi->dmi_addr, dmi->dmi_addrlen);tmp+=dev->addr_len;}// 告诉网卡dev->set_multicast_list(dev,dev->mc_count,data);kfree(data);}
最后我们看一下set_multicast_list
static void set_multicast_list(struct device *dev, int num_addrs, void *addrs){int ioaddr = dev->base_addr;// 多播模式if (num_addrs > 0) {outb(RX_MULT, RX_CMD);inb(RX_STATUS); /* Clear status. */} else if (num_addrs < 0) { // 混杂模式outb(RX_PROM, RX_CMD);inb(RX_STATUS);} else { // 正常模式outb(RX_NORM, RX_CMD);inb(RX_STATUS);}}
set_multicast_list就是设置网卡工作模式的函数。至此,我们就成功加入了一个多播组。离开一个多播组也是类似的过程。
16.2.5.2 维护多播组信息
加入多播组后,我们可以主动退出多播组,但是如果主机挂了,就无法主动退出了,所以多播路由也会定期向所有多播组的所有主机发送探测报文,所以主机需要监听来自多播路由的探测报文。
void ip_mc_allhost(struct device *dev){struct ip_mc_list *i;for(i=dev->ip_mc_list;i!=NULL;i=i->next)if(i->multiaddr==IGMP_ALL_HOSTS)return;i=(struct ip_mc_list *)kmalloc(sizeof(*i), GFP_KERNEL);if(!i)return;I ->users=1;i->interface=dev;i->multiaddr=IGMP_ALL_HOSTS;i->next=dev->ip_mc_list;dev->ip_mc_list=i;ip_mc_filter_add(i->interface, i->multiaddr);}
设备启动的时候,操作系统会设置网卡监听目的IP是224.0.0.1的报文,使得可以处理目的IP是224.0.0.1的多播消息。该类型的报文是多播路由用于查询局域网当前多播组情况的,比如查询哪些多播组已经没有成员了,如果没有成员则删除路由信息。我们看看如何处理某设备的IGMP报文。
int igmp_rcv(struct sk_buff *skb, struct device *dev, struct options *opt,unsigned long daddr, unsigned short len, unsigned long saddr, int redo,struct inet_protocol *protocol){// IGMP报头struct igmphdr *igh=(struct igmphdr *)skb->h.raw;// 该数据包是发给所有多播主机的,用于查询本多播组中是否还有成员if(igh->type==IGMP_HOST_MEMBERSHIP_QUERY && daddr==IGMP_ALL_HOSTS)igmp_heard_query(dev);// 该数据包是其它成员对多播路由查询报文的回复,同多播组的主机也会收到if(igh->type==IGMP_HOST_MEMBERSHIP_REPORT && daddr==igh->group)igmp_heard_report(dev,igh->group);kfree_skb(skb, FREE_READ);return 0;}
IGMP V1只处理两种报文,分别是组成员查询报文(查询组是否有成员),其它成员回复多播路由的报告报文。组成员查询报文由多播路由发出,所有的多播组中的所有主机都可以收到。组成员查询报文的IP协议头的目的地址是224.0.0.1(IGMP_ALL_HOSTS),代表所有的组播主机都可以处理该报文。我们看一下这两种报文的具体实现。
static void igmp_heard_query(struct device *dev){struct ip_mc_list *im;for(im=dev->ip_mc_list;im!=NULL;im=im->next)// IGMP_ALL_HOSTS表示所有组播主机if(!im->tm_running && im->multiaddr!=IGMP_ALL_HOSTS)igmp_start_timer(im);}
该函数用于处理组播路由的查询报文,dev->ip_mc_list是该设备对应的所有多播组信息,这里针对该设备中的每一个多播组,开启对应的定时器,超时后会发送回复报文给多播路由。我们看一下开启定时器的逻辑。
// 开启一个定时器static void igmp_start_timer(struct ip_mc_list *im){int tv;if(im->tm_running)return;tv=random()%(10*HZ); /* Pick a number any number 8) */im->timer.expires=tv;im->tm_running=1;add_timer(&im->timer);}
随机选择一个超时时间,然后插入系统维护的定时器队列。为什么使用定时器,而不是立即回复呢?因为多播路由只需要知道某个多播组是否至少还有一个成员,如果有的话就保存该多播组信息,否则就删除路由项。如果某多播组在局域网中有多个成员,那么多个成员都会处理该报文,如果都立即响应,则会引起过多没有必要的流量,因为组播路由只需要收到一个响应就行。我们看看超时时的逻辑。
static void igmp_init_timer(struct ip_mc_list *im){im->tm_running=0;init_timer(&im->timer);im->timer.data=(unsigned long)im;im->timer.function=&igmp_timer_expire;}static void igmp_timer_expire(unsigned long data){struct ip_mc_list *im=(struct ip_mc_list *)data;igmp_stop_timer(im);igmp_send_report(im->interface, im->multiaddr, IGMP_HOST_MEMBERSHIP_REPORT);}
我们看到,超时后会执行igmp_send_report发送一个类型是IGMP_HOST_MEMBERSHIP_REPORT的IGMP、目的IP是多播组IP的报文,说明该多播组还有成员。该报文不仅会发送给多播路由,还会发给同多播组的所有主机。其它主机也是类似的逻辑,即开启一个定时器。所以最快到期的主机会先发送回复报文给多播路由和同多播组的成员,我们看一下其它同多播组的主机收到该类报文时的处理逻辑。
// 成员报告报文并且多播组是当前设置关联的多播组if(igh->type==IGMP_HOST_MEMBERSHIP_REPORT && daddr==igh->group)igmp_heard_report(dev,igh->group);
当一个多播组的其它成员针对多播路由的查询报文作了响应,因为该响应报文的目的IP是多播组IP,所以该多播组的其它成员也能收到该报文。当某个主机收到该类型的报文的时候,就知道同多播组的其它成员已经回复了多播路由了,我们就不需要回复了。
/*收到其它组成员,对于多播路由查询报文的回复,则自己就不用回复了,因为多播路由知道该组还有成员,不会删除路由信息,减少网络流量*/static void igmp_heard_report(struct device *dev, unsigned long address){struct ip_mc_list *im;for(im=dev->ip_mc_list;im!=NULL;im=im->next)if(im->multiaddr==address)igmp_stop_timer(im);}
我们看到,这里会删除定时器。即不会作为响应了。
2.3 其它 socket关闭, 退出它之前加入过的多播
void ip_mc_drop_socket(struct sock *sk){int i;if(sk->ip_mc_list==NULL)return;for(i=0;i<IP_MAX_MEMBERSHIPS;i++){if(sk->ip_mc_list->multidev[i]){ip_mc_dec_group(sk->ip_mc_list->multidev[i], sk->ip_mc_list->multiaddr[i]);sk->ip_mc_list->multidev[i]=NULL;}}kfree_s(sk->ip_mc_list,sizeof(*sk->ip_mc_list));sk->ip_mc_list=NULL;}
设备停止工作了,删除对应的多播信息
void ip_mc_drop_device(struct device *dev){struct ip_mc_list *i;struct ip_mc_list *j;for(i=dev->ip_mc_list;i!=NULL;i=j){j=i->next;kfree_s(i,sizeof(*i));}dev->ip_mc_list=NULL;}
以上是IGMP V1版本的实现,在后续V2 V3版本了又增加了很多功能,比如离开组报文,针对离开报文中的多播组,增加特定组查询报文,用于查询某个组中是否还有成员,另外还有路由选举,当局域网中有多个多播路由,多播路由之间通过协议选举出IP最小的路由为查询路由,定时给多播组发送探测报文。然后成为查询器的多播路由,会定期给其它多播路由同步心跳。否则其它多播路由会在定时器超时时认为当前查询路由已经挂了,重新选举。
16.2.5.3 开启多播
UDP的多播能力是需要用户主动开启的,原因是防止用户发送UDP数据包的时候,误传了一个多播地址,但其实用户是想发送一个单播的数据包。我们可以通过setBroadcast开启多播能力。我们看Libuv的代码。
int uv_udp_set_broadcast(uv_udp_t* handle, int on) {if (setsockopt(handle->io_watcher.fd,SOL_SOCKET,SO_BROADCAST,&on,sizeof(on))) {return UV__ERR(errno);}return 0;}
再看看操作系统的实现。
int sock_setsockopt(struct sock *sk, int level, int optname,char *optval, int optlen){...case SO_BROADCAST:sk->broadcast=val?1:0;}
我们看到实现很简单,就是设置一个标记位。当我们发送消息的时候,如果目的地址是多播地址,但是又没有设置这个标记,则会报错。
if(!sk->broadcast && ip_chk_addr(sin.sin_addr.s_addr)==IS_BROADCAST)return -EACCES;
上面代码来自调用udp的发送函数(例如sendto)时,进行的校验,如果发送的目的ip是多播地址,但是没有设置多播标记,则报错。
16.2.5.4 多播的问题
服务器
const dgram = require('dgram');const udp = dgram.createSocket('udp4');udp.bind(1234, () => {// 局域网多播地址(224.0.0.0~224.0.0.255,该范围的多播数据包,路由器不会转发)udp.addMembership('224.0.0.114');});udp.on('message', (msg, rinfo) => {console.log(`receive msg: ${msg} from ${rinfo.address}:${rinfo.port}`);});
服务器绑定1234端口后,加入多播组224.0.0.114,然后等待多播数据的到来。
客户端
const dgram = require('dgram');const udp = dgram.createSocket('udp4');udp.bind(1234, () => {udp.addMembership('224.0.0.114');});udp.send('test', 1234, '224.0.0.114', (err) => {});
客户端绑定1234端口后,也加入了多播组224.0.0.114,然后发送数据,但是发现服务端没有收到数据,客户端打印了receive msg test from 169.254.167.41:1234。这怎么多了一个IP出来?原来我主机有两个局域网地址。当我们加入多播组的时候,不仅可以设置加入哪个多播组,还能设置出口的设备和IP。当我们调用udp.addMembership(‘224.0.0.114’)的时候,我们只是设置了我们加入的多播组,没有设置出口。这时候操作系统会为我们选择一个。根据输出,我们发现操作系统选择的是169.254.167.41(子网掩码是255.255.0.0)。因为这个IP和192开头的那个不是同一子网,但是我们加入的是局域网的多播IP,所有服务端无法收到客户端发出的数据包。下面是Node.js文档的解释。
Tells the kernel to join a multicast group at the given multicastAddress and multicastInterface using the IP_ADD_MEMBERSHIP socket option. If the multicastInterface argument is not specified, the operating system will choose one interface and will add membership to it. To add membership to every available interface, call addMembership multiple times, once per interface.
我们看一下操作系统的相关逻辑。
if(MULTICAST(daddr) && *dev==NULL && skb->sk && *skb->sk->ip_mc_name)*dev=dev_get(skb->sk->ip_mc_name);
上面的代码来自操作系统发送IP数据包时的逻辑,如果目的IP似乎多播地址并且ip_mc_name非空(即我们通过addMembership第二个参数设置的值),则出口设备就是我们设置的值。否则操作系统自己选。所以我们需要显示指定这个出口,把代码改成udp.addMembership(‘224.0.0.114’, ‘192.168.8.164’);重新执行发现客户端和服务器都显示了receive msg test from 192.168.8.164:1234。为什么客户端自己也会收到呢?原来操作系统发送多播数据的时候,也会给自己发送一份。我们看看相关逻辑
// 目的地是多播地址,并且不是回环设备if (MULTICAST(iph->daddr) && !(dev->flags&IFF_LOOPBACK)){// 是否需要给自己一份,默认为trueif(sk==NULL || sk->ip_mc_loop){// 给所有多播组的所有主机的数据包,则直接给自己一份if(iph->daddr==IGMP_ALL_HOSTS)ip_loopback(dev,skb);else{// 判断目的ip是否在当前设备的多播ip列表中,是的回传一份struct ip_mc_list *imc=dev->ip_mc_list;while(imc!=NULL){if(imc->multiaddr==iph->daddr){ip_loopback(dev,skb);break;}imc=imc->next;}}}}
以上代码来自IP层发送数据包时的逻辑。如果我们设置了sk->ip_mc_loop字段为1,并且数据包的目的IP在出口设备的多播列表中,则需要给自己回传一份。那么我们如何关闭这个特性呢?调用udp.setMulticastLoopback(false)就可以了。
16.2.5.5 其它功能
UDP模块还提供了其它一些功能
1 获取本端地址address
如果用户没有显示调用bind绑定自己设置的IP和端口,那么操作系统就会随机选择。通过address函数就可以获取操作系统选择的源IP和端口。
2 获取对端的地址
通过remoteAddress函数可以获取对端地址。该地址由用户调用connect或sendto函数时设置。
3 获取/设置缓冲区大小get/setRecvBufferSize,get/setSendBufferSize
4 setMulticastLoopback
发送多播数据包的时候,如果多播IP在出口设备的多播列表中,则给回环设备也发一份。
5 setMulticastInterface
设置多播数据的出口设备
6 加入或退出多播组addMembership/dropMembership
7 addSourceSpecificMembership/dropSourceSpecificMembership
这两个函数是设置本端只接收特性源(主机)的多播数据包。
8 setTTL
单播ttl(单播的时候,IP协议头中的ttl字段)。
9 setMulticastTTL
多播ttl(多播的时候,IP协议的ttl字段)。
10 ref/unref
这两个函数设置如果Node.js主进程中只有UDP对应的handle时,是否允许Node.js退出。Node.js事件循环的退出的条件之一是是否还有ref状态的handle。 这些都是对操作系统API的封装,就不一一分析。
16.2.6 端口复用
我们在网络编程中经常会遇到端口重复绑定的错误,根据到底是我们不能绑定到同一个端口和IP两次。但是在UDP中,这是允许的,这就是端口复用的功能,在TCP中,我们通过端口复用来解决服务器重启时重新绑定到同一个端口的问题,因为我们知道端口有一个2msl的等待时间,重启服务器重新绑定到这个端口时,默认会报错,但是如果我们设置了端口复用(Node.js自动帮我们设置了),则可以绕过这个限制。UDP中也支持端口复用的功能,但是功能、用途和TCP的不太一样。因为多个进程可以绑定同一个IP和端口。但是一般只用于多播的情况下。下面我们来分析一下udp端口复用的逻辑。在Node.js中,使用UDP的时候,可以通过reuseAddr选项使得进程可以复用端口,并且每一个想复用端口的socket都需要设置reuseAddr。我们看一下Node.js中关于reuseAddr的逻辑。
Socket.prototype.bind = function(port_, address_ /* , callback */) {let flags = 0;if (state.reuseAddr)flags |= UV_UDP_REUSEADDR;state.handle.bind(ip, port || 0, flags);};// 我们看到Node.js在bind的时候会处理reuseAddr字段。我们直接看Libuv的逻辑。int uv__udp_bind(uv_udp_t* handle,const struct sockaddr* addr,unsigned int addrlen,unsigned int flags) {if (flags & UV_UDP_REUSEADDR) {err = uv__set_reuse(fd);}bind(fd, addr, addrlen))return 0;}static int uv__set_reuse(int fd) {int yes;yes = 1;if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes)))return UV__ERR(errno);return 0;}
我们看到Libuv通过最终通过setsockopt设置了端口复用,并且是在bind之前。我们不妨再深入一点,看一下Linux内核的实现。
asmlinkage long sys_setsockopt(int fd, int level, int optname, char __user *optval, int optlen){int err;struct socket *sock;if (optlen < 0)return -EINVAL;if ((sock = sockfd_lookup(fd, &err))!=NULL){if (level == SOL_SOCKET)err=sock_setsockopt(sock,level,optname,optval,optlen);elseerr=sock->ops->setsockopt(sock, level, optname, optval, optlen);sockfd_put(sock);}return err;}
sys_setsockopt是setsockopt对应的系统调用,我们看到sys_setsockopt也只是个入口函数,具体函数是sock_setsockopt。
int sock_setsockopt(struct socket *sock, int level, int optname,char __user *optval, int optlen){struct sock *sk=sock->sk;int val;int valbool;int ret = 0;if (get_user(val, (int __user *)optval))return -EFAULT;valbool = val?1:0;lock_sock(sk);switch(optname){case SO_REUSEADDR:sk->sk_reuse = valbool;break;// ...release_sock(sk);return ret;}
操作系统的处理很简单,只是做了一个标记。接下来我们看一下bind的时候是怎么处理的,因为端口是否重复和能否复用是在bind的时候判断的。这也是为什么在TCP中,即使两个进程不能绑定到同一个IP和端口,但是如果我们在主进程里执行了bind之后,再fork函数时,是可以实现绑定同一个IP端口的。言归正传我们看一下UDP中执行bind时的逻辑。
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len){if (sk->sk_prot->get_port(sk, snum)) {inet->saddr = inet->rcv_saddr = 0;err = -EADDRINUSE;goto out_release_sock;}}
每个协议都可以实现自己的get_port钩子函数。用来判断当前的端口是否允许被绑定。如果不允许则返回EADDRINUSE,我们看看UDP协议的实现。
static int udp_v4_get_port(struct sock *sk, unsigned short snum){struct hlist_node *node;struct sock *sk2;struct inet_sock *inet = inet_sk(sk);// 通过端口找到对应的链表,然后遍历链表sk_for_each(sk2, node, &udp_hash[snum & (UDP_HTABLE_SIZE - 1)]) {struct inet_sock *inet2 = inet_sk(sk2);// 端口已使用,则判断是否可以复用if (inet2->num == snum &&sk2 != sk &&(!inet2->rcv_saddr ||!inet->rcv_saddr ||inet2->rcv_saddr == inet->rcv_saddr) &&// 每个socket都需要设置端口复用标记(!sk2->sk_reuse || !sk->sk_reuse))// 不可以复用,报错goto fail;}// 可以复用inet->num = snum;if (sk_unhashed(sk)) {// 找到端口对应的位置struct hlist_head *h = &udp_hash[snum & (UDP_HTABLE_SIZE - 1)];// 插入链表sk_add_node(sk, h);sock_prot_inc_use(sk->sk_prot);}return 0;fail:write_unlock_bh(&udp_hash_lock);return 1;}
分析之前我们先看一下操作系统的一些数据结构,UDP协议的实现中,会使用如下的数据结构记录每一个UDP socket,如图16-6所示。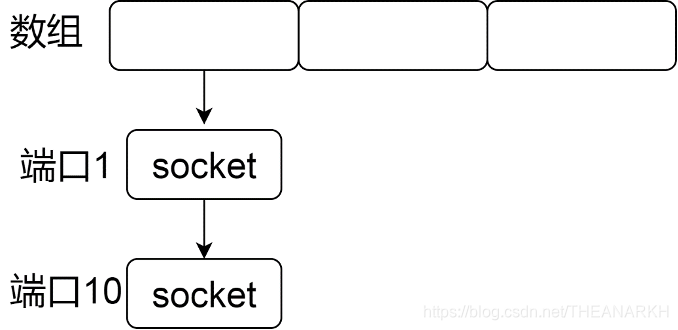
图16-6
我们看到操作系统使用一个数组作为哈希表,每次操作一个socket的时候,首先会根据socket的源端口和哈希算法计算得到一个数组索引,然后把socket插入索引锁对应的链表中,即哈希冲突的解决方法是链地址法。回到代码的逻辑,当用户想绑定一个端口的时候,操作系统会根据端口拿到对应的socket链表,然后逐个判断是否有相等的端口,如果有则判断是否可以复用。例如两个socket都设置了复用标记则可以复用。最后把socket插入到链表中。
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h){// 头结点struct hlist_node *first = h->first;n->next = first;if (first)first->pprev = &n->next;h->first = n;n->pprev = &h->first;}
我们看到操作系统是以头插法的方式插入新节点的。接着我们看一下操作系统是如何使用这些数据结构的。
16.2.6.1 多播
我们先看一个例子,我们在同主机上新建两个JS文件(客户端),代码如下
const dgram = require('dgram');const udp = dgram.createSocket({type: 'udp4', reuseAddr: true});udp.bind(1234, ‘192.168.8.164‘, () => {udp.addMembership('224.0.0.114', '192.168.8.164');});udp.on('message', (msg) => {console.log(msg)});
上面代码使得两个进程都监听了同样的IP和端口。接下来我们写一个UDP服务器。
const dgram = require('dgram');const udp = dgram.createSocket({type: 'udp4'});const socket = udp.bind(5678);socket.send('hi', 1234, '224.0.0.114', (err) => {console.log(err)});
上面的代码给一个多播组发送了一个数据,执行上面的代码,我们可以看到两个客户端进程都收到了数据。我们看一下收到数据时,操作系统是如何把数据分发给每个监听了同样IP和端口的进程的。下面是操作系统收到一个UDP数据包时的逻辑。
int udp_rcv(struct sk_buff *skb){struct sock *sk;struct udphdr *uh;unsigned short ulen;struct rtable *rt = (struct rtable*)skb->dst;// ip头中记录的源ip和目的ipu32 saddr = skb->nh.iph->saddr;u32 daddr = skb->nh.iph->daddr;int len = skb->len;// udp协议头结构体uh = skb->h.uh;ulen = ntohs(uh->len);// 广播或多播包if(rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))return udp_v4_mcast_deliver(skb, uh, saddr, daddr);// 单播sk = udp_v4_lookup(saddr, uh->source, daddr, uh->dest, skb->dev->ifindex);// 找到对应的socketif (sk != NULL) {// 把数据插到socket的消息队列int ret = udp_queue_rcv_skb(sk, skb);sock_put(sk);if (ret > 0)return -ret;return 0;}return(0);}
我们看到单播和非单播时处理逻辑是不一样的,我们先看一下非单播的情况
static int udp_v4_mcast_deliver(struct sk_buff *skb, struct udphdr *uh,u32 saddr, u32 daddr){struct sock *sk;int dif;read_lock(&udp_hash_lock);// 通过端口找到对应的链表sk = sk_head(&udp_hash[ntohs(uh->dest) & (UDP_HTABLE_SIZE - 1)]);dif = skb->dev->ifindex;sk = udp_v4_mcast_next(sk, uh->dest, daddr, uh->source, saddr, dif);if (sk) {struct sock *sknext = NULL;// 遍历每一个需要处理该数据包的socketdo {struct sk_buff *skb1 = skb;sknext = udp_v4_mcast_next(sk_next(sk),uh->dest, daddr,uh->source,saddr,dif);if(sknext)// 复制一份skb1 = skb_clone(skb, GFP_ATOMIC);// 插入每一个socket的数据包队列if(skb1) {int ret = udp_queue_rcv_skb(sk, skb1);if (ret > 0)kfree_skb(skb1);}sk = sknext;} while(sknext);} elsekfree_skb(skb);read_unlock(&udp_hash_lock);return 0;}
在非单播的情况下,操作系统会遍历链表找到每一个可以接收该数据包的socket,然后把数据包复制一份,挂载到socket的接收队列。这就解释了本节开头的例子,即两个客户端进程都会收到UDP数据包。
16.2.6.2 单播
接着我们再来看一下单播的情况。首先我们看一个例子。我们同样新建两个JS文件用作客户端。
const dgram = require('dgram');const udp = dgram.createSocket({type: 'udp4', reuseAddr: true});const socket = udp.bind(5678);socket.on('message', (msg) => {console.log(msg)})
然后再新建一个JS文件用作服务器。
const dgram = require('dgram');const udp = dgram.createSocket({type: 'udp4'});const socket = udp.bind(1234);udp.send('hi', 5678)
执行以上代码,首先执行客户端,再执行服务器,我们会发现只有一个进程会收到数据。下面我们分析具体的原因,单播时收到会调用udp_v4_lookup函数找到接收该UDP数据包的socket,然后把数据包挂载到socket的接收队列中。我们看看udp_v4_lookup。
static __inline__ struct sock *udp_v4_lookup(u32 saddr, u16 sport,u32 daddr, u16 dport, int dif){struct sock *sk;sk = udp_v4_lookup_longway(saddr, sport, daddr, dport, dif);return sk;}static struct sock *udp_v4_lookup_longway(u32 saddr, u16 sport,u32 daddr, u16 dport, int dif){struct sock *sk, *result = NULL;struct hlist_node *node;unsigned short hnum = ntohs(dport);int badness = -1;// 遍历端口对应的链表sk_for_each(sk, node, &udp_hash[hnum & (UDP_HTABLE_SIZE - 1)]) {struct inet_sock *inet = inet_sk(sk);if (inet->num == hnum && !ipv6_only_sock(sk)) {int score = (sk->sk_family == PF_INET ? 1 : 0);if (inet->rcv_saddr) {if (inet->rcv_saddr != daddr)continue;score+=2;}if (inet->daddr) {if (inet->daddr != saddr)continue;score+=2;}if (inet->dport) {if (inet->dport != sport)continue;score+=2;}if (sk->sk_bound_dev_if) {if (sk->sk_bound_dev_if != dif)continue;score+=2;}// 全匹配,直接返回,否则记录当前最好的匹配结果if(score == 9) {result = sk;break;} else if(score > badness) {result = sk;badness = score;}}}return result;}
我们看到代码很多,但是逻辑并不复杂,操作系统收到根据端口从哈希表中拿到对应的链表,然后遍历该链表找出最匹配的socket。然后把数据挂载到socket上。但是有一个细节需要注意,如果有两个进程都监听了同一个IP和端口,那么哪一个进程会收到数据呢?这个取决于操作系统的实现,从Linux源码我们看到,插入socket的时候是使用头插法,查找的时候是从头开始找最匹配的socket。即后面插入的socket会先被搜索到。但是Windows下结构却相反,先监听了该IP端口的进程会收到数据。
第

若有收获,就点个赞吧
0 人点赞
