文件操作是我们使用Node.js时经常会用到的功能。Node.js中,文件模块的API几乎都提供了同步和异步的版本。同步的API直接在主线程中调用操作系统提供的接口,它会导致主线程阻塞。异步API则是在Libuv提供的线程池中执行阻塞式API实现的。这样就不会导致主线程阻塞。文件IO不同于网络IO,文件IO由于兼容性问题,无法像网络IO一样利用操作系统提供的能力直接实现异步。在Libuv中,文件操作是以线程池实现的,操作文件的时候,会阻塞在某个线程。所以这种异步只是对用户而言。文件模块虽然提供的接口非常多,源码也几千行,但是很多逻辑都是类似的,所以我们只讲解不同的地方。介绍文件模块之前先介绍一下Linux操作系统中的文件。
Linux系统中万物皆文件,从应用层来看,我们拿到都是一个文件描述符,我们操作的也是这个文件描述符。使用起来非常简单,那是因为操作系统帮我们做了很多事情。简单来说,文件描述符只是一个索引。它的底层可以对应各种各样的资源,包括普通文件,网络,内存等。当我们操作一个资源之前,我们首先会调用操作系统的接口拿到一个文件描述符,操作系统也记录了这个文件描述符底层对应的资源、属性、操作函数等。当我们后续操作这个文件描述符的时候,操作系统就会执行对应的操作。比如我们在write的时候,传的文件描述符是普通文件和网络socket,底层所做的操作是不一样的。但是我们一般不需要关注这些。我们只需要从抽象的角度去使用它。本章介绍Node.js中关于文件模块的原理和实现。
12.1 同步API
在Node.js中,同步API的本质是直接在主线程里调用操作系统提供的系统调用。下面以readFileSync为例,看一下整体的流程,如图12-1所示。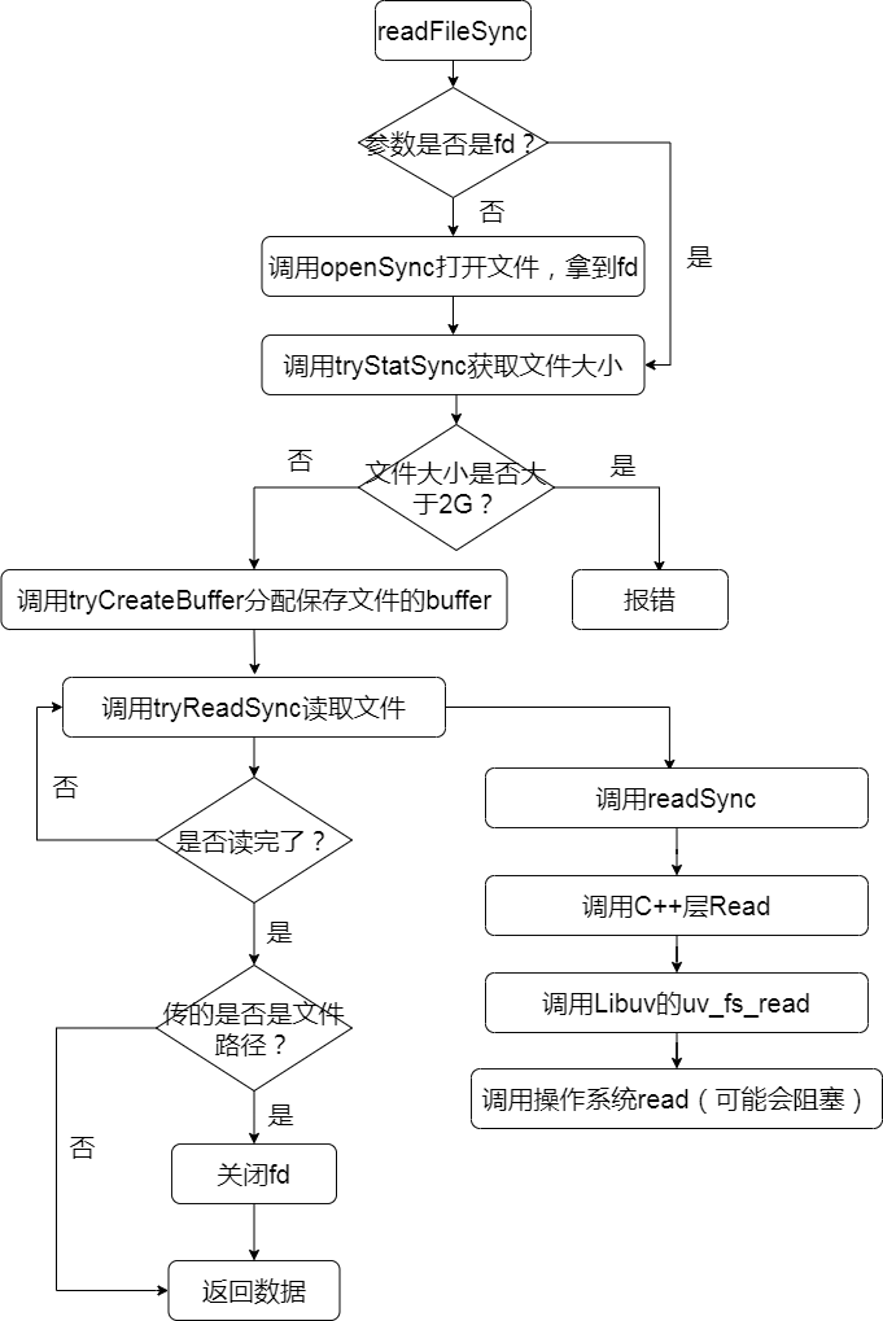
图12-1
下面我们看一下具体的代码
function readFileSync(path, options) {options = getOptions(options, { flag: 'r' });// 传的是fd还是文件路径const isUserFd = isFd(path);// 传的是路径,则先同步打开文件const fd = isUserFd ? path : fs.openSync(path, options.flag, 0o666);// 查看文件的stat信息,拿到文件的大小const stats = tryStatSync(fd, isUserFd);// 是否是一般文件const size = isFileType(stats, S_IFREG) ? stats[8] : 0;let pos = 0;let buffer;let buffers;// 文件大小是0或者不是一般文件,size则为0if (size === 0) {buffers = [];} else {// 一般文件且有大小,则分配一个大小为size的buffer,size需要小于2Gbuffer = tryCreateBuffer(size, fd, isUserFd);}let bytesRead;// 不断地同步读文件内容if (size !== 0) {do {bytesRead = tryReadSync(fd, isUserFd, buffer, pos, size - pos);pos += bytesRead;} while (bytesRead !== 0 && pos < size);} else {do {/*文件大小为0,或者不是一般文件,也尝试去读,但是因为不知道大小,所以只能分配一个一定大小的buffer,每次读取一定大小的内容*/buffer = Buffer.allocUnsafe(8192);bytesRead = tryReadSync(fd, isUserFd, buffer, 0, 8192);// 把读取到的内容放到buffers里if (bytesRead !== 0) {buffers.push(buffer.slice(0, bytesRead));}// 记录读取到的数据长度pos += bytesRead;} while (bytesRead !== 0);}// 用户传的是文件路径,Node.js自己打开了文件,所以需要自己关闭if (!isUserFd)fs.closeSync(fd);// 文件大小是0或者非一般文件的话,如果读到了内容if (size === 0) {// 把读取到的所有内容放到buffer中buffer = Buffer.concat(buffers, pos);} else if (pos < size) {buffer = buffer.slice(0, pos);}// 编码if (options.encoding) buffer = buffer.toString(options.encoding);return buffer;}
tryReadSync调用的是fs.readSync,然后到binding.read(node_file.cc中定义的Read函数)。Read函数主要逻辑如下
FSReqWrapSync req_wrap_sync;const int bytesRead = SyncCall(env,args[6],&req_wrap_sync,"read",uv_fs_read,fd,&uvbuf,1,pos);
我们看一下SyncCall的实现
int SyncCall(Environment* env,v8::Local<v8::Value> ctx,FSReqWrapSync* req_wrap,const char* syscall,Func fn,Args... args) {/*req_wrap->req是一个uv_fs_t结构体,属于request类,管理一次文件操作的请求*/int err = fn(env->event_loop(),&(req_wrap->req),args...,nullptr);// 忽略出错处理return err;}
我们看到最终调用的是Libuv的uv_fs_read,并使用uv_fs_t管理本次请求。因为是阻塞式调用,所以Libuv会直接调用操作系统的系统调用read函数。这是Node.js中同步API的过程。
12.2 异步API
文件系统的API中,异步的实现是依赖于Libuv的线程池的。Node.js把任务放到线程池,然后返回主线程继续处理其它事情,等到条件满足时,就会执行回调。我们以readFile为例讲解这个过程。异步读取文件的流程图,如图12-2所示。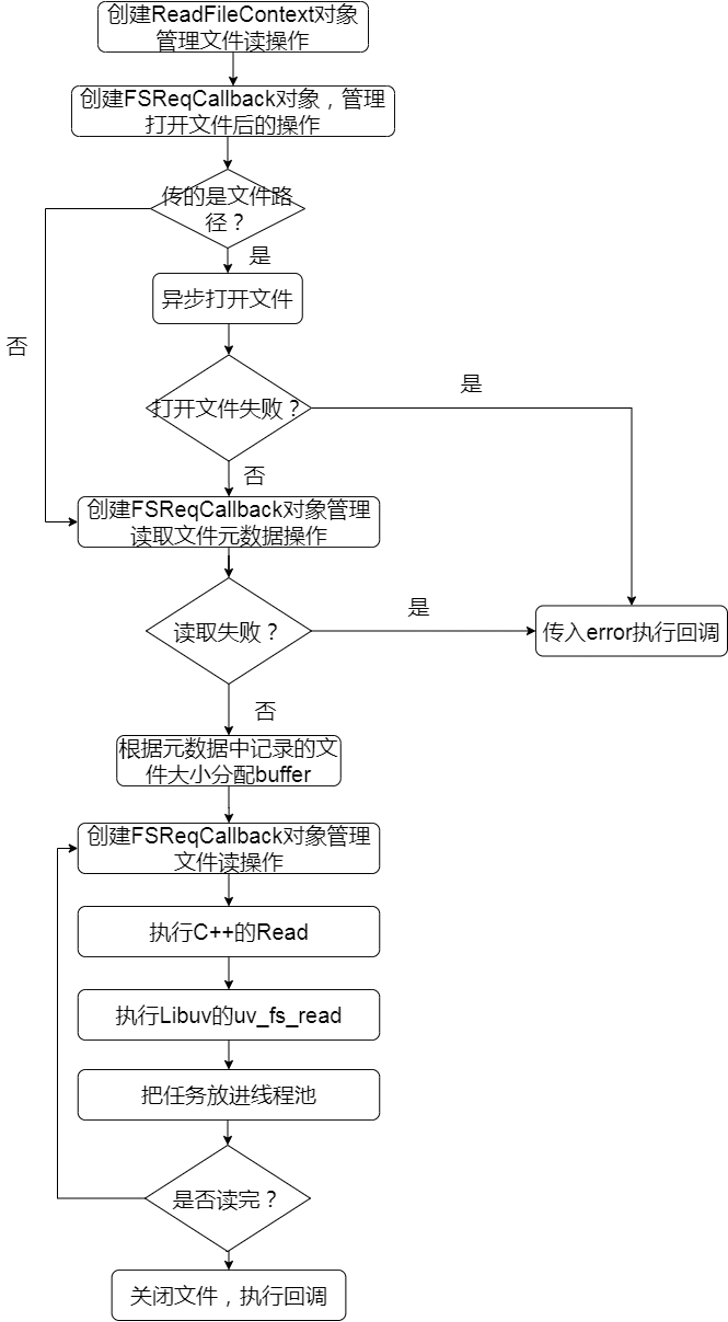
图12-2
下面我们看具体的实现
function readFile(path, options, callback) {callback = maybeCallback(callback || options);options = getOptions(options, { flag: 'r' });// 管理文件读的对象if (!ReadFileContext)ReadFileContext = require('internal/fs/read_file_context');const context = new ReadFileContext(callback, options.encoding)// 传的是文件路径还是fdcontext.isUserFd = isFd(path); // File descriptor ownership// C++层的对象,封装了uv_fs_t结构体,管理一次文件读请求const req = new FSReqCallback();req.context = context;// 设置回调,打开文件后,执行req.oncomplete = readFileAfterOpen;// 传的是fd,则不需要打开文件,下一个tick直接执行回调读取文件if (context.isUserFd) {process.nextTick(function tick() {req.oncomplete(null, path);});return;}path = getValidatedPath(path);const flagsNumber = stringToFlags(options.flags);// 调用C++层open打开文件binding.open(pathModule.toNamespacedPath(path),flagsNumber,0o666,req);}
ReadFileContext对象用于管理文件读操作整个过程,FSReqCallback是对uv_fs_t的封装,每次读操作对于Libuv来说就是一次请求,该请求的上下文就是使用uv_fs_t表示。请求完成后,会执行FSReqCallback对象的oncomplete函数。所以我们继续看readFileAfterOpen。
function readFileAfterOpen(err, fd) {const context = this.context;// 打开出错则直接执行用户回调,传入errif (err) {context.callback(err);return;}// 保存打开文件的fdcontext.fd = fd;// 新建一个FSReqCallback对象管理下一个异步请求和回调const req = new FSReqCallback();req.oncomplete = readFileAfterStat;req.context = context;// 获取文件的元数据,拿到文件大小binding.fstat(fd, false, req);}
拿到文件的元数据后,执行readFileAfterStat,这段逻辑和同步的类似,根据元数据中记录的文件大小,分配一个buffer用于后续读取文件内容。然后执行读操作。
read() {let buffer;let offset;let length;// 省略部分buffer处理的逻辑const req = new FSReqCallback();req.oncomplete = readFileAfterRead;req.context = this;read(this.fd, buffer, offset, length, -1, req);}
再次新建一个FSReqCallback对象管理异步读取操作和回调。我们看一下C++层read函数的实现。
// 拿到C++层的FSReqCallback对象FSReqBase* req_wrap_async = GetReqWrap(env, args[5]);// 异步调用uv_fs_readAsyncCall(env, req_wrap_async, args, "read", UTF8, AfterInteger,uv_fs_read, fd, &uvbuf, 1, pos);
AsyncCall最后调用Libuv的uv_fs_read函数。我们看一下这个函数的关键逻辑。
do { \if (cb != NULL) { \uv__req_register(loop, req); \uv__work_submit(loop, \&req->work_req, \UV__WORK_FAST_IO, \uv__fs_work, \uv__fs_done); \return 0; \} \else { \uv__fs_work(&req->work_req); \return req->result; \} \} \while (0)
uvwork_submit是给线程池提交一个任务,当子线程执行这个任务时,就会执行uvfs_work,uvfs_work会调用操作系统的系统调用read,可能会导致阻塞。等到读取成功后执行uvfs_done。uv__fs_done会执行C++层的回调,从而执行JS层的回调。JS层的回调是readFileAfterRead,这里就不具体展开,readFileAfterRead的逻辑是判断是否读取完毕,是的话执行用户回调,否则继续发起读取操作。
12.3 文件监听
文件监听是非常常用的功能,比如我们修改了文件后webpack重新打包代码或者Node.js服务重启,都用到了文件监听的功能,Node.js提供了两套文件监听的机制。
12.3.1 基于轮询的文件监听机制
基于轮询机制的文件监听API是watchFile。流程如图12-3所示。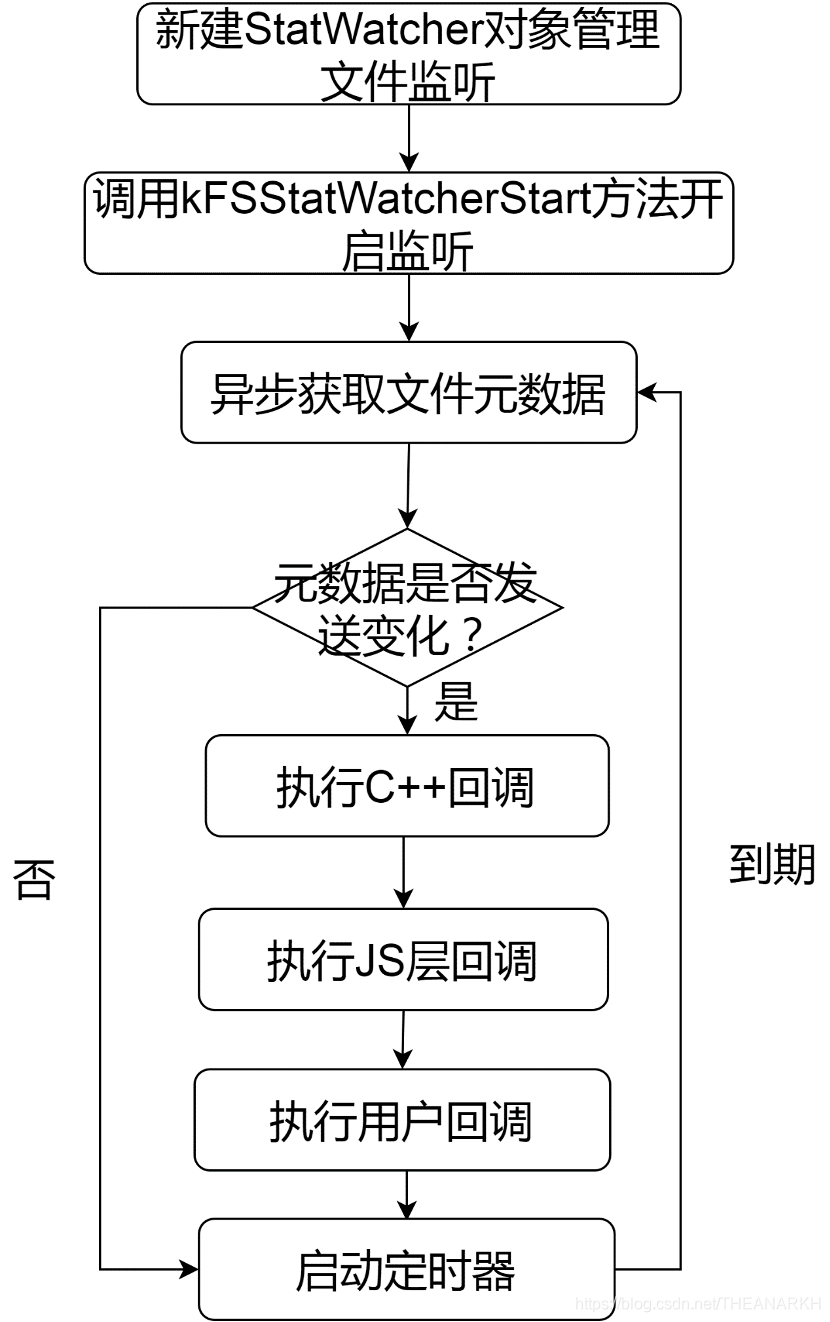
图12-3
我们看一下具体实现。
function watchFile(filename, options, listener) {filename = getValidatedPath(filename);filename = pathModule.resolve(filename);let stat;// 省略部分参数处理逻辑options = {interval: 5007,// 一直轮询persistent: true,...options};// 缓存处理,filename是否已经开启过监听stat = statWatchers.get(filename);if (stat === undefined) {if (!watchers)watchers = require('internal/fs/watchers');stat = new watchers.StatWatcher(options.bigint);// 开启监听stat[watchers.kFSStatWatcherStart](filename,options.persistent,options.interval);// 更新缓存statWatchers.set(filename, stat);}stat.addListener('change', listener);return stat;}
StatWatcher是管理文件监听的类,我们看一下watchers.kFSStatWatcherStart方法的实现。
StatWatcher.prototype[kFSStatWatcherStart] = function(filename,persistent, interval) {this._handle = new _StatWatcher(this[kUseBigint]);this._handle.onchange = onchange;filename = getValidatedPath(filename, 'filename');const err = this._handle.start(toNamespacedPath(filename),interval);}
新建一个_StatWatcher对象,_StatWatcher是C++模块提供的功能(node_stat_watcher.cc),然后执行它的start方法。Start方法执行Libuv的uv_fs_poll_start开始监听文件。
int uv_fs_poll_start(uv_fs_poll_t* handle,uv_fs_poll_cb cb,const char* path, unsigned int interval) {// 管理文件监听的数据结构struct poll_ctx* ctx;uv_loop_t* loop;size_t len;int err;loop = handle->loop;len = strlen(path);// calloc会把内存初始化为0ctx = uv__calloc(1, sizeof(*ctx) + len);ctx->loop = loop;// C++层回调ctx->poll_cb = cb;// 多久轮询一次ctx->interval = interval ? interval : 1;ctx->start_time = uv_now(loop);// 关联的handlectx->parent_handle = handle;// 监听的文件路径memcpy(ctx->path, path, len + 1);// 初始化定时器结构体err = uv_timer_init(loop, &ctx->timer_handle);// 异步查询文件元数据err = uv_fs_stat(loop, &ctx->fs_req, ctx->path, poll_cb);if (handle->poll_ctx != NULL)ctx->previous = handle->poll_ctx;// 关联负责管理轮询的对象handle->poll_ctx = ctx;uv__handle_start(handle);return 0;}
Start函数初始化一个poll_ctx结构体,用于管理文件监听,然后发起异步请求文件元数据的请求,获取元数据后,执行poll_cb回调。
static void poll_cb(uv_fs_t* req) {uv_stat_t* statbuf;struct poll_ctx* ctx;uint64_t interval;// 通过结构体字段获取结构体首地址ctx = container_of(req, struct poll_ctx, fs_req);statbuf = &req->statbuf;/*第一次不执行回调,因为没有可对比的元数据,第二次及后续的操作才可能执行回调,busy_polling初始化的时候为0,第一次执行的时候置busy_polling=1*/if (ctx->busy_polling != 0)// 出错或者stat发生了变化则执行回调if (ctx->busy_polling < 0 ||!statbuf_eq(&ctx->statbuf, statbuf))ctx->poll_cb(ctx->parent_handle,0,&ctx->statbuf,statbuf);// 保存当前获取到的stat信息,置1ctx->statbuf = *statbuf;ctx->busy_polling = 1;out:uv_fs_req_cleanup(req);if (ctx->parent_handle == NULL) {uv_close((uv_handle_t*)&ctx->timer_handle, timer_close_cb);return;}/*假设在开始时间点为1,interval为10的情况下执行了stat,stat完成执行并执行poll_cb回调的时间点是3,那么定时器的超时时间则为10-3=7,即7个单位后就要触发超时,而不是10,是因为stat阻塞消耗了3个单位的时间,所以下次执行超时回调函数时说明从start时间点开始算,已经经历了x单位各interval,然后超时回调里又执行了stat函数,再到执行stat回调,这个时间点即now=start+x单位个interval+stat消耗的时间。得出now-start为interval的x倍+stat消耗,即对interval取余可得到stat消耗,所以当前轮,定时器的超时时间为interval - ((now-start) % interval)*/interval = ctx->interval;interval = (uv_now(ctx->loop) - ctx->start_time) % interval;if (uv_timer_start(&ctx->timer_handle, timer_cb, interval, 0))abort();}
基于轮询的监听文件机制本质上是不断轮询文件的元数据,然后和上一次的元数据进行对比,如果有不一致的就认为文件变化了,因为第一次获取元数据时,还没有可以对比的数据,所以不认为是文件变化,这时候开启一个定时器。隔一段时间再去获取文件的元数据,如此反复,直到用户调stop函数停止这个行为。下面是Libuv关于文件变化的定义。
static int statbuf_eq(const uv_stat_t* a, const uv_stat_t* b) {return a->st_ctim.tv_nsec == b->st_ctim.tv_nsec&& a->st_mtim.tv_nsec == b->st_mtim.tv_nsec&& a->st_birthtim.tv_nsec == b->st_birthtim.tv_nsec&& a->st_ctim.tv_sec == b->st_ctim.tv_sec&& a->st_mtim.tv_sec == b->st_mtim.tv_sec&& a->st_birthtim.tv_sec == b->st_birthtim.tv_sec&& a->st_size == b->st_size&& a->st_mode == b->st_mode&& a->st_uid == b->st_uid&& a->st_gid == b->st_gid&& a->st_ino == b->st_ino&& a->st_dev == b->st_dev&& a->st_flags == b->st_flags&& a->st_gen == b->st_gen;}
12.3.2基于inotify的文件监听机制
我们看到基于轮询的监听其实效率是很低的,因为需要我们不断去轮询文件的元数据,如果文件大部分时间里都没有变化,那就会白白浪费CPU。如果文件改变了会主动通知我们那就好了,这就是基于inotify机制的文件监听。Node.js提供的接口是watch。watch的实现和watchFile的比较类似。
function watch(filename, options, listener) {// Don't make changes directly on options objectoptions = copyObject(options);// 是否持续监听if (options.persistent === undefined)options.persistent = true;// 如果是目录,是否监听所有子目录和文件的变化if (options.recursive === undefined)options.recursive = false;// 有些平台不支持if (options.recursive && !(isOSX || isWindows))throw new ERR_FEATURE_UNAVAILABLE_ON_PLATFORM('watch recursively');if (!watchers)watchers = require('internal/fs/watchers');// 新建一个FSWatcher对象管理文件监听,然后开启监听const watcher = new watchers.FSWatcher();watcher[watchers.kFSWatchStart](filename,options.persistent,options.recursive,options.encoding);if (listener) {watcher.addListener('change', listener);}return watcher;}
FSWatcher函数是对C层FSEvent模块的封装。我们来看一下start函数的逻辑,start函数透过C层调用了Libuv的uv_fs_event_start函数。在讲解uv_fs_event_start函数前,我们先了解一下inotify的原理和它在Libuv中的实现。inotify是Linux系统提供用于监听文件系统的机制。inotify机制的逻辑大致是
1 init_inotify创建一个inotify的实例,返回一个文件描述符。类似epoll。
2 inotify_add_watch往inotify实例注册一个需监听的文件(inotify_rm_watch是移除)。
3 read(inotify实例对应的文件描述符, &buf, sizeof(buf)),如果没有事件触发,则阻塞(除非设置了非阻塞)。否则返回待读取的数据长度。buf就是保存了触发事件的信息。
Libuv在inotify机制的基础上做了一层封装。我们看一下inotify在Libuv的架构图如图12-4所示。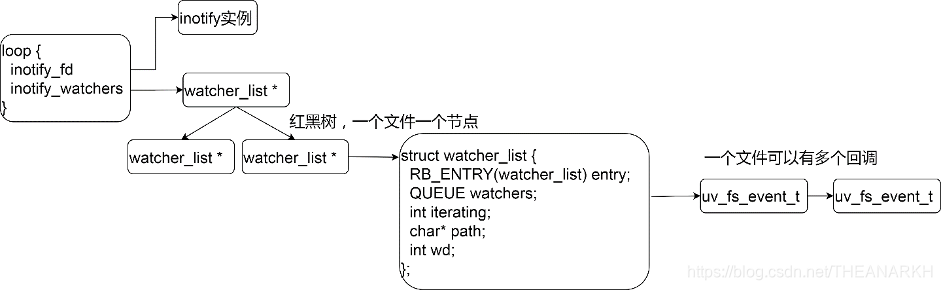
图12-4
我们再来看一下Libuv中的实现。我们从一个使用例子开始。
int main(int argc, char **argv) {// 实现循环核心结构体looploop = uv_default_loop();uv_fs_event_t *fs_event_req = malloc(sizeof(uv_fs_event_t));// 初始化fs_event_req结构体的类型为UV_FS_EVENTuv_fs_event_init(loop, fs_event_req);/*argv[argc]是文件路径,uv_fs_event_start 向底层注册监听文件argv[argc],cb是事件触发时的回调*/uv_fs_event_start(fs_event_req,cb,argv[argc],UV_FS_EVENT_RECURSIVE);// 开启事件循环return uv_run(loop, UV_RUN_DEFAULT);}
Libuv在第一次监听文件的时候(调用uv_fs_event_start的时候),会创建一个inotify实例。
static int init_inotify(uv_loop_t* loop) {int err;// 初始化过了则直接返回if (loop->inotify_fd != -1)return 0;/*调用操作系统的inotify_init函数申请一个inotify实例,并设置UV__IN_NONBLOCK,UV__IN_CLOEXEC标记*/err = new_inotify_fd();if (err < 0)return err;// 记录inotify实例对应的文件描述符,一个事件循环一个inotify实例loop->inotify_fd = err;/*inotify_read_watcher是一个IO观察者,uv__io_init设置IO观察者的文件描述符(待观察的文件)和回调*/uv__io_init(&loop->inotify_read_watcher,uv__inotify_read,loop->inotify_fd);// 往Libuv中注册该IO观察者,感兴趣的事件为可读uv__io_start(loop, &loop->inotify_read_watcher, POLLIN);return 0;}
Libuv把inotify实例对应的fd通过uvio_start注册到epoll中,当有文件变化的时候,就会执行回调uvinotify_read。分析完Libuv申请inotify实例的逻辑,我们回到main函数看看uv_fs_event_start函数。用户使用uv_fs_event_start函数来往Libuv注册一个待监听的文件。我们看看实现。
int uv_fs_event_start(uv_fs_event_t* handle,uv_fs_event_cb cb,const char* path,unsigned int flags) {struct watcher_list* w;int events;int err;int wd;if (uv__is_active(handle))return UV_EINVAL;// 申请一个inotify实例err = init_inotify(handle->loop);if (err)return err;// 监听的事件events = UV__IN_ATTRIB| UV__IN_CREATE| UV__IN_MODIFY| UV__IN_DELETE| UV__IN_DELETE_SELF| UV__IN_MOVE_SELF| UV__IN_MOVED_FROM| UV__IN_MOVED_TO;// 调用操作系统的函数注册一个待监听的文件,返回一个对应于该文件的idwd = uv__inotify_add_watch(handle->loop->inotify_fd, path, events);if (wd == -1)return UV__ERR(errno);// 判断该文件是不是已经注册过了w = find_watcher(handle->loop, wd);// 已经注册过则跳过插入的逻辑if (w)goto no_insert;// 还没有注册过则插入Libuv维护的红黑树w = uv__malloc(sizeof(*w) + strlen(path) + 1);if (w == NULL)return UV_ENOMEM;w->wd = wd;w->path = strcpy((char*)(w + 1), path);QUEUE_INIT(&w->watchers);w->iterating = 0;// 插入Libuv维护的红黑树,inotify_watchers是根节点RB_INSERT(watcher_root, CAST(&handle->loop->inotify_watchers), w);no_insert:// 激活该handleuv__handle_start(handle);// 同一个文件可能注册了很多个回调,w对应一个文件,注册在用一个文件的回调排成队QUEUE_INSERT_TAIL(&w->watchers, &handle->watchers);// 保存信息和回调handle->path = w->path;handle->cb = cb;handle->wd = wd;return 0;}
下面我们逐步分析上面的函数逻辑。
1 如果是首次调用该函数则新建一个inotify实例。并且往Libuv插入一个观察者io,Libuv会在Poll IO阶段注册到epoll中。
2 往操作系统注册一个待监听的文件。返回一个id。
3 Libuv判断该id是不是在自己维护的红黑树中。不在红黑树中,则插入红黑树。返回一个红黑树中对应的节点。把本次请求的信息封装到handle中(回调时需要)。然后把handle插入刚才返回的节点的队列中。
这时候注册过程就完成了。Libuv在Poll IO阶段如果检测到有文件发生变化,则会执行回调uv__inotify_read。
static void uv__inotify_read(uv_loop_t* loop,uv__io_t* dummy,unsigned int events) {const struct uv__inotify_event* e;struct watcher_list* w;uv_fs_event_t* h;QUEUE queue;QUEUE* q;const char* path;ssize_t size;const char *p;/* needs to be large enough for sizeof(inotify_event) + strlen(path) */char buf[4096];// 一次可能没有读完while (1) {do// 读取触发的事件信息,size是数据大小,buffer保存数据size = read(loop->inotify_fd, buf, sizeof(buf));while (size == -1 && errno == EINTR);// 没有数据可取了if (size == -1) {assert(errno == EAGAIN || errno == EWOULDBLOCK);break;}// 处理buffer的信息for (p = buf; p < buf + size; p += sizeof(*e) + e->len) {// buffer里是多个uv__inotify_event结构体,里面保存了事件信息和文件对应的id(wd字段)e = (const struct uv__inotify_event*)p;events = 0;if (e->mask & (UV__IN_ATTRIB|UV__IN_MODIFY))events |= UV_CHANGE;if (e->mask & ~(UV__IN_ATTRIB|UV__IN_MODIFY))events |= UV_RENAME;// 通过文件对应的id(wd字段)从红黑树中找到对应的节点w = find_watcher(loop, e->wd);path = e->len ? (const char*) (e + 1) : uv__basename_r(w->path);w->iterating = 1;// 把红黑树中,wd对应节点的handle队列移到queue变量,准备处理QUEUE_MOVE(&w->watchers, &queue);while (!QUEUE_EMPTY(&queue)) {// 头结点q = QUEUE_HEAD(&queue);// 通过结构体偏移拿到首地址h = QUEUE_DATA(q, uv_fs_event_t, watchers);// 从处理队列中移除QUEUE_REMOVE(q);// 放回原队列QUEUE_INSERT_TAIL(&w->watchers, q);// 执行回调h->cb(h, path, events, 0);}}}}
uv__inotify_read函数的逻辑就是从操作系统中把数据读取出来,这些数据中保存了哪些文件触发了用户感兴趣的事件。然后遍历每个触发了事件的文件。从红黑树中找到该文件对应的红黑树节点。再取出红黑树节点中维护的一个handle队列,最后执行handle队列中每个节点的回调。
12.4 Promise化API
Node.js的API都是遵循callback模式的,比如我们要读取一个文件的内容。我们通常会这样写
const fs = require('fs');fs.readFile('filename', 'utf-8' ,(err,data) => {console.log(data)})//为了支持Promise模式,我们通常这样写const fs = require('fs');function readFile(filename) {return new Promise((resolve, reject) => {fs.readFile(filename, 'utf-8' ,(err,data) => {err ? reject(err) : resolve(data);});});}
但是在Node.js V14中,文件模块支持了Promise化的api。我们可以直接使用await进行文件操作。我们看一下使用例子。
const { open, readFile } = require('fs').promises;async function runDemo() {try {console.log(await readFile('11111.md', { encoding: 'utf-8' }));} catch (e){}}runDemo();
从例子中我们看到,和之前的API调用方式类似,不同的地方在于我们不用再写回调了,而是通过await的方式接收结果。这只是新版API的特性之一。在新版API之前,文件模块大部分API都是类似工具函数,比如readFile,writeFile,新版API中支持面向对象的调用方式。
const { open, readFile } = require('fs').promises;async function runDemo() {let filehandle;try {filehandle = await open('filename', 'r');// console.log(await readFile(filehandle, { encoding: 'utf-8' }));console.log(await filehandle.readFile({ encoding: 'utf-8' }));} finally {if (filehandle) {await filehandle.close();}}}runDemo();
面向对象的模式中,我们首先需要通过open函数拿到一个FileHandle对象(对文件描述符的封装),然后就可以在该对象上调各种文件操作的函数。在使用面向对象模式的API时有一个需要注意的地方是Node.js不会为我们关闭文件描述符,即使文件操作出错,所以我们需要自己手动关闭文件描述符,否则会造成文件描述符泄漏,而在非面向对象模式中,在文件操作完毕后,不管成功还是失败,Node.js都会为我们关闭文件描述符。下面我们看一下具体的实现。首先介绍一个FileHandle类。该类是对文件描述符的封装,提供了面向对象的API。
class FileHandle {constructor(filehandle) {// filehandle为C++对象this[kHandle] = filehandle;this[kFd] = filehandle.fd;}get fd() {return this[kFd];}readFile(options) {return readFile(this, options);}close = () => {this[kFd] = -1;return this[kHandle].close();}// 省略部分操作文件的api}
FileHandle的逻辑比较简单,首先封装了一系列文件操作的API,然后实现了close函数用于关闭底层的文件描述符。
1 操作文件系统API
这里我们以readFile为例进行分析
async function readFile(path, options) {options = getOptions(options, { flag: 'r' });const flag = options.flag || 'r';// 以面向对象的方式使用,这时候需要自己关闭文件描述符if (path instanceof FileHandle)return readFileHandle(path, options);// 直接调用,首先需要先打开文件描述符,读取完毕后Node.js会主动关闭文件描述符const fd = await open(path, flag, 0o666);return readFileHandle(fd, options).finally(fd.close);}
从readFile代码中我们看到不同调用方式下,Node.js的处理是不一样的,当FileHandle是我们维护时,关闭操作也是我们负责执行,当FileHandle是Node.js维护时,Node.js在文件操作完毕后,不管成功还是失败都会主动关闭文件描述符。接着我们看到readFileHandle的实现。
async function readFileHandle(filehandle, options) {// 获取文件元信息const statFields = await binding.fstat(filehandle.fd, false, kUsePromises);let size;// 是不是普通文件,根据文件类型获取对应大小if ((statFields[1/* mode */] & S_IFMT) === S_IFREG) {size = statFields[8/* size */];} else {size = 0;}// 太大了if (size > kIoMaxLength)throw new ERR_FS_FILE_TOO_LARGE(size);const chunks = [];// 计算每次读取的大小const chunkSize = size === 0 ?kReadFileMaxChunkSize :MathMin(size, kReadFileMaxChunkSize);let endOfFile = false;do {// 分配内存承载数据const buf = Buffer.alloc(chunkSize);// 读取的数据和大小const { bytesRead, buffer } =await read(filehandle, buf, 0, chunkSize, -1);// 是否读完了endOfFile = bytesRead === 0;// 读取了有效数据则把有效数据部分存起来if (bytesRead > 0)chunks.push(buffer.slice(0, bytesRead));} while (!endOfFile);const result = Buffer.concat(chunks);if (options.encoding) {return result.toString(options.encoding);} else {return result;}}
接着我们看read函数的实现
async function read(handle, buffer, offset, length, position) {// ...const bytesRead = (await binding.read(handle.fd, buffer, offset, length, position, kUsePromises)) || 0;return { bytesRead, buffer };}
Read最终执行了node_file.cc 的Read。我们看一下Read函数的关键代码。
static void Read(const FunctionCallbackInfo<Value>& args) {Environment* env = Environment::GetCurrent(args);// ...FSReqBase* req_wrap_async = GetReqWrap(env, args[5]);// 异步执行,有两种情况if (req_wrap_async != nullptr) {AsyncCall(env, req_wrap_async, args, "read", UTF8, AfterInteger,uv_fs_read, fd, &uvbuf, 1, pos);} else {// 同步执行,比如fs.readFileSyncCHECK_EQ(argc, 7);FSReqWrapSync req_wrap_sync;FS_SYNC_TRACE_BEGIN(read);const int bytesRead = SyncCall(env, args[6], &req_wrap_sync, "read",uv_fs_read, fd, &uvbuf, 1, pos);FS_SYNC_TRACE_END(read, "bytesRead", bytesRead);args.GetReturnValue().Set(bytesRead);}}
Read函数分为三种情况,同步和异步,其中异步又分为两种,callback模式和Promise模式。我们看一下异步模式的实现。我们首先看一下这句代码。
FSReqBase* req_wrap_async = GetReqWrap(env, args[5]);
GetReqWrap根据第六个参数获取对应的值。
FSReqBase* GetReqWrap(Environment* env, v8::Local<v8::Value> value,bool use_bigint) {// 是对象说明是继承FSReqBase的对象,比如FSReqCallback(异步模式)if (value->IsObject()) {return Unwrap<FSReqBase>(value.As<v8::Object>());} else if (value->StrictEquals(env->fs_use_promises_symbol())) {// Promise模式(异步模式)if (use_bigint) {return FSReqPromise<AliasedBigUint64Array>::New(env, use_bigint);} else {return FSReqPromise<AliasedFloat64Array>::New(env, use_bigint);}}// 同步模式return nullptr;}
这里我们只关注Promise模式。所以GetReqWrap返回的是一个FSReqPromise对象,我们回到Read函数。看到以下代码
FSReqBase* req_wrap_async = GetReqWrap(env, args[5]);AsyncCall(env, req_wrap_async, args, "read", UTF8, AfterInteger,uv_fs_read, fd, &uvbuf, 1, pos);继续看AsyncCall函数(node_file-inl.h)template <typename Func, typename... Args>FSReqBase* AsyncCall(Environment* env,FSReqBase* req_wrap,const v8::FunctionCallbackInfo<v8::Value>& args,const char* syscall, enum encoding enc,uv_fs_cb after, Func fn, Args... fn_args) {return AsyncDestCall(env, req_wrap, args,syscall, nullptr, 0, enc,after, fn, fn_args...);}
AsyncCall是对AsyncDestCall的封装
template <typename Func, typename... Args>FSReqBase* AsyncDestCall(Environment* env, FSReqBase* req_wrap,const v8::FunctionCallbackInfo<v8::Value>& args,const char* syscall, const char* dest,size_t len, enum encoding enc, uv_fs_cb after,Func fn, Args... fn_args) {CHECK_NOT_NULL(req_wrap);req_wrap->Init(syscall, dest, len, enc);// 调用libuv函数int err = req_wrap->Dispatch(fn, fn_args..., after);// 失败则直接执行回调,否则返回一个Promise,见SetReturnValue函数if (err < 0) {uv_fs_t* uv_req = req_wrap->req();uv_req->result = err;uv_req->path = nullptr;after(uv_req); // after may delete req_wrap if there is an errorreq_wrap = nullptr;} else {req_wrap->SetReturnValue(args);}return req_wrap;}
AsyncDestCall函数主要做了两个操作,首先通过Dispatch调用底层Libuv的函数,比如这里是uv_fs_read。如果出错执行回调返回错误,否则执行req_wrap->SetReturnValue(args)。我们知道req_wrap是在GetReqWrap函数中由FSReqPromise::New(env, use_bigint)创建。
template <typename AliasedBufferT>FSReqPromise<AliasedBufferT>*FSReqPromise<AliasedBufferT>::New(Environment* env, bool use_bigint) {v8::Local<v8::Object> obj;// 创建一个C++对象存到obj中if (!env->fsreqpromise_constructor_template()->NewInstance(env->context()).ToLocal(&obj)) {return nullptr;}// 设置一个promise属性,值是一个Promise::Resolverv8::Local<v8::Promise::Resolver> resolver;if (!v8::Promise::Resolver::New(env->context()).ToLocal(&resolver) ||obj->Set(env->context(), env->promise_string(), resolver).IsNothing()) {return nullptr;}// 返回另一个C++对象,里面保存了obj,obj也保存了指向FSReqPromise对象的指针return new FSReqPromise(env, obj, use_bigint);}
所以req_wrap是一个FSReqPromise对象。我们看一下FSReqPromise对象的SetReturnValue方法。
template <typename AliasedBufferT>void FSReqPromise<AliasedBufferT>::SetReturnValue(const v8::FunctionCallbackInfo<v8::Value>& args) {// 拿到Promise::Resolver对象v8::Local<v8::Value> val =object()->Get(env()->context(),env()->promise_string()).ToLocalChecked();v8::Local<v8::Promise::Resolver> resolver = val.As<v8::Promise::Resolver>();// 拿到一个Promise作为返回值,即JS层拿到的值args.GetReturnValue().Set(resolver->GetPromise());}
至此我们看到了新版API实现的核心逻辑,正是这个Promise返回值。通过层层返回后,在JS层就拿到这个Promise,然后处于pending状态等待决议。我们继续看一下Promise决议的逻辑。在分析Read函数中我们看到执行Libuv的uv_fs_read函数时,设置的回调是AfterInteger。那么当读取文件成功后就会执行该函数。所以我们看看该函数的逻辑。
void AfterInteger(uv_fs_t* req) {// 通过属性拿到对象的地址FSReqBase* req_wrap = FSReqBase::from_req(req);FSReqAfterScope after(req_wrap, req);if (after.Proceed())req_wrap->Resolve(Integer::New(req_wrap->env()->isolate(), req->result));}
接着我们看一下Resolve
template <typename AliasedBufferT>void FSReqPromise<AliasedBufferT>::Resolve(v8::Local<v8::Value> value) {finished_ = true;v8::HandleScope scope(env()->isolate());InternalCallbackScope callback_scope(this);// 拿到保存的Promise对象,修改状态为resolve,并设置结果v8::Local<v8::Value> val =object()->Get(env()->context(),env()->promise_string()).ToLocalChecked();v8::Local<v8::Promise::Resolver> resolver = val.As<v8::Promise::Resolver>();USE(resolver->Resolve(env()->context(), value).FromJust());}
Resolve函数修改Promise的状态和设置返回值,从而JS层拿到这个决议的值。回到fs层
const bytesRead = (await binding.read(handle.fd,buffer,offset,length,position, kUsePromises))|0;
我们就拿到了返回值。
12.5 流式API
前面分析了Node.js中文件模块的多种文件操作的方式,不管是同步、异步还是Promise化的API,它们都有一个问题就是对于用户来说,文件操作都是一次性完成的,比如我们调用readFile读取一个文件时,Node.js会通过一次或多次调用操作系统的接口把所有的文件内容读到内存中,同样我们调用writeFile写一个文件时,Node.js会通过一次或多次调用操作系统接口把用户的数据写入硬盘,这对内存来说是非常有压力的。假设我们有这样的一个场景,我们需要读取一个文件的内容,然后返回给前端,如果我们直接读取整个文件内容,然后再执行写操作这无疑是非常消耗内存,也是非常低效的。
const http = require('http');const fs = require('fs');const server = http.createServer((req, res) => {fs.readFile('11111.md', (err, data) => {res.end(data);})}).listen(11111);
这时候我们需要使用流式的API。
const http = require('http');const fs = require('fs');const server = http.createServer((req, res) => {fs.createReadStream('11111.md').pipe(res);}).listen(11111);
流式API的好处在于文件的内容并不是一次性读取到内存的,而是部分读取,消费完后再继续读取。Node.js内部帮我们做了流量的控制,如图12-5所示。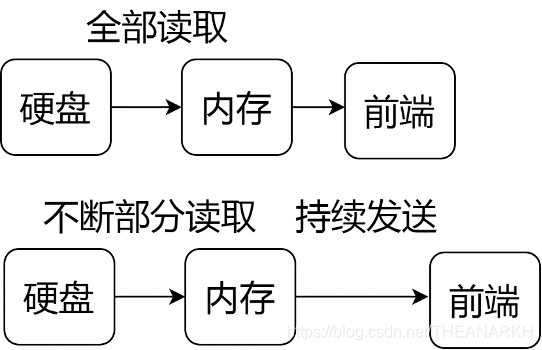
图12-5
下面我们看一下Node.js流式API的具体实现。
12.5.1 可读文件流
可读文件流是对文件进行流式读取的抽象。我们可以通过fs.createReadStream创建一个文件可读流。文件可读流继承于可读流,所以我们可以以可读流的方式使用它。
const fs = require('fs');const { Writable } = require('stream');class DemoWritable extends Writable {_write(data, encoding, cb) {console.log(data);cb(null);}}fs.createReadStream('11111.md').pipe(new DemoWritable);
或者
const fs = require('fs');const readStream = fs.createReadStream('11111.md');readStream.on('data', (data) => {console.log(data)});
我们看一下createReadStream的实现。
fs.createReadStream = function(path, options) {return new ReadStream(path, options);};
CreateReadStream是对ReadStream的封装。
function ReadStream(path, options) {if (!(this instanceof ReadStream))return new ReadStream(path, options);options = copyObject(getOptions(options, {}));// 可读流的阈值if (options.highWaterMark === undefined)options.highWaterMark = 64 * 1024;Readable.call(this, options);handleError((this.path = getPathFromURL(path)));// 支持传文件路径或文件描述符this.fd = options.fd === undefined ? null : options.fd;this.flags = options.flags === undefined ? 'r' : options.flags;this.mode = options.mode === undefined ? 0o666 : options.mode;// 读取的开始和结束位置this.start = typeof this.fd !== 'number' && options.start === undefined ?0 : options.start;this.end = options.end;// 流出错或结束时是否自动销毁流this.autoClose = options.autoClose === undefined ? true : options.autoClose;this.pos = undefined;// 已读的字节数this.bytesRead = 0;// 流是否已经关闭this.closed = false;// 参数校验if (this.start !== undefined) {if (typeof this.start !== 'number') {throw new errors.TypeError('ERR_INVALID_ARG_TYPE','start','number',this.start);}// 默认读取全部内容if (this.end === undefined) {this.end = Infinity;} else if (typeof this.end !== 'number') {throw new errors.TypeError('ERR_INVALID_ARG_TYPE','end','number',this.end);}// 从文件的哪个位置开始读,start是开始位置,pos是当前位置,初始化等于开始位置this.pos = this.start;}// 如果是根据一个文件名创建一个流,则首先打开这个文件if (typeof this.fd !== 'number')this.open();this.on('end', function() {// 流结束时自动销毁流if (this.autoClose) {this.destroy();}});}
ReadStream初始化完后做了两个操作,首先调用open打开文件(如果需要的话),接着监听流结束事件,用户可以设置autoClose选项控制当流结束或者出错时是否销毁流,对于文件流来说,销毁流意味着关闭地方文件描述符。我们接着看一下open的实现
// 打开文件ReadStream.prototype.open = function() {var self = this;fs.open(this.path, this.flags, this.mode, function(er, fd) {if (er) {// 发生错误,是否需要自动销毁流if (self.autoClose) {self.destroy();}// 通知用户self.emit('error', er);return;}self.fd = fd;// 触发open,一般用于Node.js内部逻辑self.emit('open', fd);// start the flow of data.// 打开成功后开始流式读取文件内容self.read();});};
open函数首先打开文件,打开成功后开启流式读取。从而文件内容就会源源不断地流向目的流。我们继续看一下读取操作的实现。
// 实现可读流的钩子函数ReadStream.prototype._read = function(n) {// 如果没有调用open而是直接调用该方法则先执行openif (typeof this.fd !== 'number') {return this.once('open', function() {this._read(n);});}// 流已经销毁则不处理if (this.destroyed)return;// 判断池子空间是否足够,不够则申请新的if (!pool || pool.length - pool.used < kMinPoolSpace) {// discard the old pool.allocNewPool(this.readableHighWaterMark);}// 计算可读的最大数量var thisPool = pool;/*可读取的最大值,取可用内存大小和Node.js打算读取的大小中的小值,n不是用户想读取的大小,而是可读流内部的逻辑见_stream_readable.js的this._read(state.highWaterMark)*/var toRead = Math.min(pool.length - pool.used, n);var start = pool.used;// 已经读取了部分了,则计算剩下读取的大小,和计算读取的toRead比较取小值if (this.pos !== undefined)toRead = Math.min(this.end - this.pos + 1, toRead);// 读结束if (toRead <= 0)return this.push(null);// pool.used是即将读取的数据存储在pool中的开始位置,this.pos是从文件的哪个位置开始读取fs.read(this.fd, pool, pool.used, toRead, this.pos, (er, bytesRead) => {if (er) {if (this.autoClose) {this.destroy();}this.emit('error', er);} else {var b = null;if (bytesRead > 0) {// 已读的字节数累加this.bytesRead += bytesRead;// 获取有效数据b = thisPool.slice(start, start + bytesRead);}// push到底层流的bufferList中,底层的push会触发data事件this.push(b);}});// 重新设置已读指针的位置if (this.pos !== undefined)this.pos += toRead;pool.used += toRead;};
代码看起来很多,主要的逻辑是调用异步read函数读取文件的内容,然后放到可读流中,可读流会触发data事件通知用户有数据到来,然后继续执行read函数,从而不断驱动着数据的读取(可读流会根据当前情况判断是否继续执行read函数,以达到流量控制的目的)。最后我们看一下关闭和销毁一个文件流的实现。
ReadStream.prototype.close = function(cb) {this.destroy(null, cb);};
当我们设置autoClose为false的时候,我们就需要自己手动调用close函数关闭可读文件流。关闭文件流很简单,就是正常地销毁流。我们看看销毁流的时候,Node.js做了什么。
// 关闭底层文件ReadStream.prototype._destroy = function(err, cb) {const isOpen = typeof this.fd !== 'number';if (isOpen) {this.once('open', closeFsStream.bind(null, this, cb, err));return;}closeFsStream(this, cb);this.fd = null;};function closeFsStream(stream, cb, err) {fs.close(stream.fd, (er) => {er = er || err;cb(er);stream.closed = true;if (!er)stream.emit('close');});}
销毁文件流就是关闭底层的文件描述符。另外如果是因为发生错误导致销毁或者关闭文件描述符错误则不会触发close事件。
12.5.2 可写文件流
可写文件流是对文件进行流式写入的抽象。我们可以通过fs.createWriteStream创建一个文件可写流。文件可些流继承于可写流,所以我们可以以可写流的方式使用它。
const fs = require('fs');const writeStream = fs.createWriteStream('123.md');writeStream.end('world');// 或者const fs = require('fs');const { Readable } = require('stream');class DemoReadStream extends Readable {constructor() {super();this.i = 0;}_read(n) {this.i++;if (this.i > 10) {this.push(null);} else {this.push('1'.repeat(n));}}}new DemoReadStream().pipe(fs.createWriteStream('123.md'));
我们看一下createWriteStream的实现。
fs.createWriteStream = function(path, options) {return new WriteStream(path, options);};
createWriteStream是对WriteStream的封装,我们看一下WriteStream的实现
function WriteStream(path, options) {if (!(this instanceof WriteStream))return new WriteStream(path, options);options = copyObject(getOptions(options, {}));Writable.call(this, options);handleError((this.path = getPathFromURL(path)));this.fd = options.fd === undefined ? null : options.fd;this.flags = options.flags === undefined ? 'w' : options.flags;this.mode = options.mode === undefined ? 0o666 : options.mode;// 写入的开始位置this.start = options.start;// 流结束和触发错误的时候是否销毁流this.autoClose = options.autoClose === undefined ? true : !!options.autoClose;// 当前写入位置this.pos = undefined;// 写成功的字节数this.bytesWritten = 0;this.closed = false;if (this.start !== undefined) {if (typeof this.start !== 'number') {throw new errors.TypeError('ERR_INVALID_ARG_TYPE','start','number',this.start);}if (this.start < 0) {const errVal = `{start: ${this.start}}`;throw new errors.RangeError('ERR_OUT_OF_RANGE','start','>= 0',errVal);}// 记录写入的开始位置this.pos = this.start;}if (options.encoding)this.setDefaultEncoding(options.encoding);// 没有传文件描述符则打开一个新的文件if (typeof this.fd !== 'number')this.open();// 监听可写流的finish事件,判断是否需要执行销毁操作this.once('finish', function() {if (this.autoClose) {this.destroy();}});}
WriteStream初始化了一系列字段后,如果传的是文件路径则打开文件,如果传的文件描述符则不需要再次打开文件。后续对文件可写流的操作就是对文件描述符的操作。我们首先看一下写入文件的逻辑。我们知道可写流只是实现了一些抽象的逻辑,具体的写逻辑是具体的流通过_write或者_writev实现的,我们看一下_write的实现。
WriteStream.prototype._write = function(data, encoding, cb) {if (!(data instanceof Buffer)) {const err = new errors.TypeError('ERR_INVALID_ARG_TYPE','data','Buffer',data);return this.emit('error', err);}// 还没打开文件,则等待打开成功后再执行写操作if (typeof this.fd !== 'number') {return this.once('open', function() {this._write(data, encoding, cb);});}// 执行写操作,0代表从data的哪个位置开始写,这里是全部写入,所以是0,pos代表文件的位置fs.write(this.fd, data, 0, data.length, this.pos, (er, bytes) => {if (er) {if (this.autoClose) {this.destroy();}return cb(er);}// 写入成功的字节长度this.bytesWritten += bytes;cb();});// 下一个写入的位置if (this.pos !== undefined)this.pos += data.length;};
_write就是根据用户传入数据的大小,不断调用fs.write往底层写入数据,直到写完成或者出错。接着我们看一下批量写的逻辑。
// 实现可写流批量写钩子WriteStream.prototype._writev = function(data, cb) {if (typeof this.fd !== 'number') {return this.once('open', function() {this._writev(data, cb);});}const self = this;const len = data.length;const chunks = new Array(len);var size = 0;// 计算待写入的出总大小,并且把数据保存到chunk数组中,准备写入for (var i = 0; i < len; i++) {var chunk = data[i].chunk;chunks[i] = chunk;size += chunk.length;}// 执行批量写writev(this.fd, chunks, this.pos, function(er, bytes) {if (er) {self.destroy();return cb(er);}// 写成功的字节数,可能小于希望写入的字节数self.bytesWritten += bytes;cb();});/*更新下一个写入位置,如果写部分成功,计算下一个写入位置时也会包括没写成功的字节数,所以是假设size而不是bytes*/if (this.pos !== undefined)this.pos += size;};
批量写入的逻辑和_write类似,只不过它调用的是不同的接口往底层写。接下来我们看关闭文件可写流的实现。
WriteStream.prototype.close = function(cb) {// 关闭文件成功后执行的回调if (cb) {if (this.closed) {process.nextTick(cb);return;} else {this.on('close', cb);}}/*如果autoClose是false,说明流结束触发finish事件时,不会销毁流,见WriteStream初始化代码 以这里需要监听finish事件,保证可写流结束时可以关闭文件描述符*/if (!this.autoClose) {this.on('finish', this.destroy.bind(this));}// 结束流,会触发finish事件this.end();};
可写文件流和可读文件流不一样。默认情况下,可读流在读完文件内容后Node.js会自动销毁流(关闭文件描述符),而写入文件,在某些情况下Node.js是无法知道什么时候流结束的,这需要我们显式地通知Node.js。在下面的例子中,我们是不需要显式通知Node.js的
fs.createReadStream(‘11111.md’).pipe(fs.createWriteStream(‘123.md’));
因为可读文件流在文件读完后会调用可写文件的end方法,从而关闭可读流和可写流对应的文件描述符。而在以下代码中情况就变得复杂。
const stream = fs.createWriteStream('123.md');stream.write('hello');// stream.close 或 stream.end();
在默认情况,我们可以调用end或者close去通知Node.js流结束。但是如果我们设置了autoClose为false,那么我们只能调用close而不能调用end。否则会造成文件描述符泄漏。因为end只是关闭了流。但是没有触发销毁流的逻辑。而close会触发销毁流的逻辑。我们看一下具体的代码。
const fs = require('fs');const stream = fs.createWriteStream('123.md');stream.write('hello');// 防止进程退出setInterval(() => {});
以上代码会导致文件描述符泄漏,我们在Linux下执行以下代码,通过ps aux找到进程id,然后执行lsof -p pid就可以看到进程打开的所有文件描述符。输出如12-6所示。
图12-6
文件描述符17指向了123.md文件。所以文件描述符没有被关闭,引起文件描述符泄漏。我们修改一下代码。
const fs = require('fs');const stream = fs.createWriteStream('123.md');stream.end('hello');setInterval(() => {});
下面是以上代码的输出,我们看到没有123.md对应的文件描述符,如图12-7所示。
图12-7
我们继续修改代码
const fs = require('fs');const stream = fs.createWriteStream('123.md', {autoClose: false});stream.end('hello');setInterval(() => {});
以上代码的输出如图12-8所示。
图12-8
我们看到使用end也无法关闭文件描述符。继续修改。
const fs = require('fs');const stream = fs.createWriteStream('123.md', {autoClose: false})stream.close();setInterval(() => {});
以上代码的输出如图12-9所示。
图12-9
我们看到成功关闭了文件描述符。

若有收获,就点个赞吧
0 人点赞
