进程是操作系统里非常重要的概念,也是不容易理解的概念,但是看起来很复杂的进程,其实在操作系统的代码里,也只是一些数据结构和算法,只不过它比一般的数据结构和算法更复杂。进程在操作系统里,是用一个task_struct结构体表示的。因为操作系统是大部分是用C语言实现的,没有对象这个概念。如果我们用JS来理解的话,每个进程就是一个对象,每次新建一个进程,就是新建一个对象。task_struct结构体里保存了一个进程所需要的一些信息,包括执行状态、执行上下文、打开的文件、根目录、工作目录、收到的信号、信号处理函数、代码段、数据段的信息、进程id、执行时间、退出码等等。本章将会介绍Node.js进程模块的原理和实现。
13.1 Node.js主进程
当我们执行node index.js的时候,操作系统就会创建一个Node.js进程,我们的代码就是在这个Node.js进程中执行。从代码角度来说,我们在Node.js中感知进程的方式是通过process对象。本节我们分析一下这个对象。
13.1.1 创建process对象
Node.js启动的时候会执行以下代码创建process对象(env.cc)。
Local<Object> process_object = node::CreateProcessObject(this).FromMaybe(Local<Object>());set_process_object(process_object);// process对象通过CreateProcessObject创建,然后保存到env对象中。我们看一下CreateProcessObject。MaybeLocal<Object> CreateProcessObject(Environment* env) {Isolate* isolate = env->isolate();EscapableHandleScope scope(isolate);Local<Context> context = env->context();Local<FunctionTemplate> process_template = FunctionTemplate::New(isolate);process_template->SetClassName(env->process_string());Local<Function> process_ctor;Local<Object> process;// 新建process对象if (!process_template->GetFunction(context).ToLocal(&process_ctor) || !process_ctor->NewInstance(context).ToLocal(&process)) {return MaybeLocal<Object>();}// 设置一系列属性,这就是我们平时通过process对象访问的属性// Node.js的版本READONLY_PROPERTY(process,"version",FIXED_ONE_BYTE_STRING(env->isolate(),NODE_VERSION));// 忽略其他属性return scope.Escape(process);}
这是使用V8创建一个对象的典型例子,并且设置了一些属性。Node.js启动过程中,很多地方都会给process挂载属性。下面我们看我们常用的process.env是怎么挂载的。
13.1.2 挂载env属性
Local<String> env_string = FIXED_ONE_BYTE_STRING(isolate_, "env");Local<Object> env_var_proxy;// 设置process的env属性if (!CreateEnvVarProxy(context(),isolate_,as_callback_data()).ToLocal(&env_var_proxy) ||process_object()->Set(context(),env_string,env_var_proxy).IsNothing()) {return MaybeLocal<Value>();}
上面的代码通过CreateEnvVarProxy创建了一个对象,然后保存到env_var_proxy中,最后给process挂载了env属性。它的值是CreateEnvVarProxy创建的对象。
MaybeLocal<Object> CreateEnvVarProxy(Local<Context> context,Isolate* isolate,Local<Object> data) {EscapableHandleScope scope(isolate);Local<ObjectTemplate> env_proxy_template = ObjectTemplate::New(isolate);env_proxy_template->SetHandler(NamedPropertyHandlerConfiguration(EnvGetter,EnvSetter,EnvQuery,EnvDeleter,EnvEnumerator,data,PropertyHandlerFlags::kHasNoSideEffect));return scope.EscapeMaybe(env_proxy_template->NewInstance(context));}
CreateEnvVarProxy首先申请一个对象模板,然后设置通过该对象模板创建的对象的访问描述符。我们看一下getter描述符(EnvGetter)的实现,getter描述符和我们在JS里使用的类似。
static void EnvGetter(Local<Name> property,const PropertyCallbackInfo<Value>& info) {Environment* env = Environment::GetCurrent(info);MaybeLocal<String> value_string = env->env_vars()->Get(env->isolate(), property.As<String>());if (!value_string.IsEmpty()) {info.GetReturnValue().Set(value_string.ToLocalChecked());}}
我们看到getter是从env->env_vars()中获取数据,那么env->env_vars()又是什么呢?env_vars是一个kv存储系统,其实就是一个map。它只在Node.js初始化的时候设置(创建env对象时)。
set_env_vars(per_process::system_environment);
那么per_process::system_environment又是什么呢?我们继续往下看,
std::shared_ptr<KVStore> system_environment = std::make_shared<RealEnvStore>();
我们看到system_environment是一个RealEnvStore对象。我们看一下RealEnvStore类的实现。
class RealEnvStore final : public KVStore {public:MaybeLocal<String> Get(Isolate* isolate, Local<String> key) const override;void Set(Isolate* isolate, Local<String> key, Local<String> value) override;int32_t Query(Isolate* isolate, Local<String> key) const override;void Delete(Isolate* isolate, Local<String> key) override;Local<Array> Enumerate(Isolate* isolate) const override;};
比较简单,就是增删改查,我们看一下查询Get的实现。
MaybeLocal<String> RealEnvStore::Get(Isolate* isolate,Local<String> property) const {Mutex::ScopedLock lock(per_process::env_var_mutex);node::Utf8Value key(isolate, property);size_t init_sz = 256;MaybeStackBuffer<char, 256> val;int ret = uv_os_getenv(*key, *val, &init_sz);if (ret >= 0) { // Env key value fetch success.MaybeLocal<String> value_string =String::NewFromUtf8(isolate,*val,NewStringType::kNormal,init_sz);return value_string;}return MaybeLocal<String>();}
我们看到是通过uv_os_getenv获取的数据。uv_os_getenv是对getenv函数的封装,进程的内存布局中,有一部分是用于存储环境变量的,getenv就是从那一块内存中把数据读取出来。我们执行execve的时候可以设置环境变量。具体的我们在子进程章节会看到。至此,我们知道process的env属性对应的值就是进程环境变量的内容。
13.1.3 挂载其它属性
在Node.js的启动过程中会不断地挂载属性到process。主要在bootstrap/node.js中。不一一列举。
const rawMethods = internalBinding('process_methods');process.dlopen = rawMethods.dlopen;process.uptime = rawMethods.uptime;process.nextTick = nextTick;
下面是process_methods模块导出的属性,主列出常用的。
env->SetMethod(target, "memoryUsage", MemoryUsage);env->SetMethod(target, "cpuUsage", CPUUsage);env->SetMethod(target, "hrtime", Hrtime);env->SetMethod(target, "dlopen", binding::DLOpen);env->SetMethodNoSideEffect(target, "uptime", Uptime);
我们看到在JS层访问process属性的时候,访问的是对应的C++层的这些方法,大部分也只是对Libuv的封装。另外在Node.js初始化的过程中会执行PatchProcessObject。PatchProcessObject函数会挂载一些额外的属性给process。
// process.argvprocess->Set(context,FIXED_ONE_BYTE_STRING(isolate, "argv"),ToV8Value(context, env->argv()).ToLocalChecked()).Check();READONLY_PROPERTY(process,"pid",Integer::New(isolate, uv_os_getpid()));CHECK(process->SetAccessor(context,FIXED_ONE_BYTE_STRING(isolate, "ppid"),GetParentProcessId).FromJust())
在Node.js初始化的过程中,在多个地方都会给process对象挂载属性,这里只列出了一部分,有兴趣的同学可以从bootstrap/node.js的代码开始看都挂载了什么属性。因为Node.js支持多线程,所以针对线程的情况,有一些特殊的处理。
const perThreadSetup = require('internal/process/per_thread');// rawMethods来自process_methods模块导出的属性const wrapped = perThreadSetup.wrapProcessMethods(rawMethods);process.hrtime = wrapped.hrtime;process.cpuUsage = wrapped.cpuUsage;process.memoryUsage = wrapped.memoryUsage;process.kill = wrapped.kill;process.exit = wrapped.exit;
大部分函数都是对process_methods模块(node_process_methods.cc)的封装。但是有一个属性我们需要关注一下,就是exit,因为在线程中调用process.exit的时候,只会退出单个线程,而不是整个进程。
function exit(code) {if (code || code === 0)process.exitCode = code;if (!process._exiting) {process._exiting = true;process.emit('exit', process.exitCode || 0);}process.reallyExit(process.exitCode || 0);}
我们继续看reallyExit
static void ReallyExit(const FunctionCallbackInfo<Value>& args) {Environment* env = Environment::GetCurrent(args);RunAtExit(env);int code = args[0]->Int32Value(env->context()).FromMaybe(0);env->Exit(code);}
调用了env的Exit。
void Environment::Exit(int exit_code) {if (is_main_thread()) {stop_sub_worker_contexts();DisposePlatform();exit(exit_code);} else {worker_context_->Exit(exit_code);}}
这里我们看到了重点,根据当前是主线程还是子线程会做不同的处理。一个线程会对应一个env,env对象中的workercontext保存就是线程对象(Worker)。我们先看子线程的逻辑。
void Worker::Exit(int code) {Mutex::ScopedLock lock(mutex_);if (env_ != nullptr) {exit_code_ = code;Stop(env_);} else {stopped_ = true;}}int Stop(Environment* env) {env->ExitEnv();return 0;}void Environment::ExitEnv() {set_can_call_into_js(false);set_stopping(true);isolate_->TerminateExecution();// 退出Libuv事件循环SetImmediateThreadsafe([](Environment* env) { uv_stop(env->event_loop()); });}
我们看到子线程最后调用uv_stop提出了Libuv事件循环,然后退出。我们再来看主线程的退出逻辑。
if (is_main_thread()) {stop_sub_worker_contexts();DisposePlatform();exit(exit_code);}
我们看到最后主进程中调用exit退出进程。但是退出前还有一些处理工作,我们看stop_sub_worker_contexts
void Environment::stop_sub_worker_contexts() {while (!sub_worker_contexts_.empty()) {Worker* w = *sub_worker_contexts_.begin();remove_sub_worker_context(w);w->Exit(1);w->JoinThread();}}
sub_worker_contexts保存的是Worker对象列表,每次创建一个线程的时候,就会往里追加一个元素。这里遍历这个列表,然后调用Exit函数,这个刚才我们已经分析过,就是退出Libuv事件循环。主线程接着调JoinThread,JoinThread主要是为了阻塞等待子线程退出,因为子线程在退出的时候,可能会被操作系统挂起(执行时间片到了),这时候主线程被调度执行,但是这时候主线程还不能退出,所以这里使用join阻塞等待子线程退出。Node.js的JoinThread除了对线程join函数的封装。还做了一些额外的事情,比如触发exit事件。
13.2 创建子进程
因为Node.js是单进程的,但有很多事情可能不适合在主进程里处理的,所以Node.js提供了子进程模块,我们可以创建子进程做一些额外任务的处理,另外,子进程的好处是,一旦子进程出问题挂掉不会影响主进程。我们首先看一下在用C语言如何创建一个进程。
#include<unistd.h>#include<stdlib.h>int main(int argc,char *argv[]){pid_t pid = fork();if (pid < 0) {// 错误} else if(pid == 0) {// 子进程,可以使用exec*系列函数执行新的程序} else {// 父进程}}
fork函数的特点,我们听得最多的可能是执行一次返回两次,我们可能会疑惑,执行一个函数怎么可能返回了两次呢?之前我们讲过,进程是task_struct表示的一个实例,调用 fork的时候,操作系统会新建一个新的task_struct实例出来(变成两个进程),fork返回两次的意思其实是在在两个进程分别返回一次,执行的都是fork后面的一行代码。而操作系统根据当前进程是主进程还是子进程,设置了fork函数的返回值。所以不同的进程,fork返回值不一样,也就是我们代码中if else条件。但是fork只是复制主进程的内容,如果我们想执行另外一个程序,怎么办呢?这时候就需要用到exec*系列函数,该系列函数会覆盖旧进程(task_struct)的部分内容,重新加载新的程序内容。这也是Node.js中创建子进程的底层原理。Node.js虽然提供了很多种创建进程的方式,但是本质上是同步和异步两种方式。
13.2.1 异步创建进程
我们首先看一下异步方式创建进程时的关系图如图13-1所示。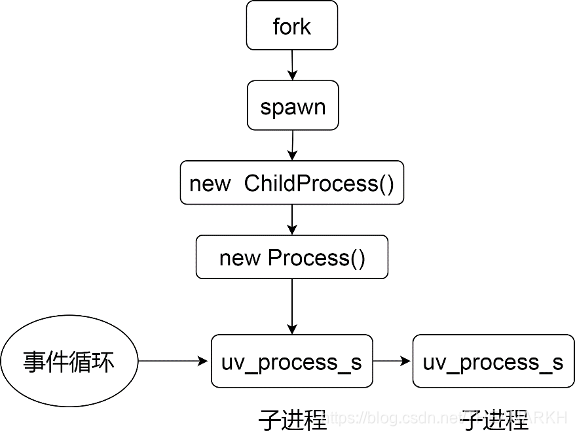
图13-1
我们从fork这个函数开始,看一下整个流程。
function fork(modulePath /* , args, options */) {// 一系列参数处理return spawn(options.execPath, args, options);}
我们接着看spawn
var spawn = exports.spawn = function(/*file, args, options*/) { var opts = normalizeSpawnArguments.apply(null, arguments);var options = opts.options;var child = new ChildProcess();child.spawn({file: opts.file,args: opts.args,cwd: options.cwd,windowsHide: !!options.windowsHide,windowsVerbatimArguments: !!options.windowsVerbatimArguments,detached: !!options.detached,envPairs: opts.envPairs,stdio: options.stdio,uid: options.uid,gid: options.gid});return child;};
我们看到spawn函数只是对ChildProcess的封装。然后调用它的spawn函数。我们看看ChildProcess。
function ChildProcess() {// C++层定义this._handle = new Process();}ChildProcess.prototype.spawn = function(options) {// 创建进程const err = this._handle.spawn(options);}
ChildProcess是对C层的封装,不过Process在C层也没有太多逻辑,进行参数的处理然后调用Libuv的uv_spawn。我们通过uv_spawn来到了C语言层。我们看看uv_spawn的整体流程。
int uv_spawn(uv_loop_t* loop,uv_process_t* process,const uv_process_options_t* options) {uv__handle_init(loop, (uv_handle_t*)process, UV_PROCESS);QUEUE_INIT(&process->queue);// 处理进程间通信for (i = 0; i < options->stdio_count; i++) {err = uv__process_init_stdio(options->stdio + i, pipes[i]);if (err)goto error;}/*创建一个管道用于创建进程期间的父进程子通信,设置UV__O_CLOEXEC标记,子进程执行execvp的时候管道的一端会被关闭*/err = uv__make_pipe(signal_pipe, 0);// 注册子进程退出信号的处理函数uv_signal_start(&loop->child_watcher, uv__chld, SIGCHLD);uv_rwlock_wrlock(&loop->cloexec_lock);// 创建子进程pid = fork();// 子进程if (pid == 0) {uv__process_child_init(options,stdio_count,pipes,signal_pipe[1]);abort();}// 父进程uv_rwlock_wrunlock(&loop->cloexec_lock);// 关闭管道写端,等待子进程写uv__close(signal_pipe[1]);process->status = 0;exec_errorno = 0;// 判断子进程是否执行成功dor = read(signal_pipe[0],&exec_errorno,sizeof(exec_errorno));while (r == -1 && errno == EINTR);// 忽略处理r的逻辑// 保存通信的文件描述符到对应的数据结构for (i = 0; i < options->stdio_count; i++) {uv__process_open_stream(options->stdio + i, pipes[i]);}// 插入Libuv事件循环的结构体if (exec_errorno == 0) {QUEUE_INSERT_TAIL(&loop->process_handles, &process->queue);uv__handle_start(process);}process->pid = pid;process->exit_cb = options->exit_cb;return exec_errorno;}
uv_spawn的逻辑大致分为下面几个
1 处理进程间通信
2 注册子进程退出处理函数
3 创建子进程
4 插入Libuv事件循环的process_handles对象,保存状态码和回调等。
我们分析2,3,进程间通信我们单独分析。
1 处理子进程退出
主进程在创建子进程之前,会注册SIGCHLD信号。对应的处理函数是uvchld。当进程退出的时候。Node.js主进程会收到SIGCHLD信号。然后执行uvchld。该函数遍历Libuv进程队列中的节点,通过waitpid判断该节点对应的进程是否已经退出后,从而处理已退出的节点,然后移出Libuv队列,最后执行已退出进程的回调。
static void uv__chld(uv_signal_t* handle, int signum) {uv_process_t* process;uv_loop_t* loop;int exit_status;int term_signal;int status;pid_t pid;QUEUE pending;QUEUE* q;QUEUE* h;// 保存进程(已退出的状态)的队列QUEUE_INIT(&pending);loop = handle->loop;h = &loop->process_handles;q = QUEUE_HEAD(h);// 收集已退出的进程while (q != h) {process = QUEUE_DATA(q, uv_process_t, queue);q = QUEUE_NEXT(q);do/*WNOHANG非阻塞等待子进程退出,其实就是看子进程是否退出了,没有的话就直接返回,而不是阻塞*/pid = waitpid(process->pid, &status, WNOHANG);while (pid == -1 && errno == EINTR);if (pid == 0)continue;/*进程退出了,保存退出状态,移出队列,插入peding队列,等待处理*/process->status = status;QUEUE_REMOVE(&process->queue);QUEUE_INSERT_TAIL(&pending, &process->queue);}h = &pending;q = QUEUE_HEAD(h);// 是否有退出的进程while (q != h) {process = QUEUE_DATA(q, uv_process_t, queue);q = QUEUE_NEXT(q);QUEUE_REMOVE(&process->queue);QUEUE_INIT(&process->queue);uv__handle_stop(process);if (process->exit_cb == NULL)continue;exit_status = 0;// 获取退出信息,执行上传回调if (WIFEXITED(process->status))exit_status = WEXITSTATUS(process->status);// 是否因为信号而退出term_signal = 0;if (WIFSIGNALED(process->status))term_signal = WTERMSIG(process->status);process->exit_cb(process, exit_status, term_signal);}}
当主进程下的子进程退出时,父进程主要负责收集子进程退出状态和原因等信息,然后执行上层回调。
2 创建子进程(uvprocess_child_init)
主进程首先使用uvmake_pipe申请一个匿名管道用于主进程和子进程通信,匿名管道是进程间通信中比较简单的一种,它只用于有继承关系的进程,因为匿名,非继承关系的进程无法找到这个管道,也就无法完成通信,而有继承关系的进程,是通过fork出来的,父子进程可以获得得到管道。进一步来说,子进程可以使用继承于父进程的资源,管道通信的原理如图13-2所示。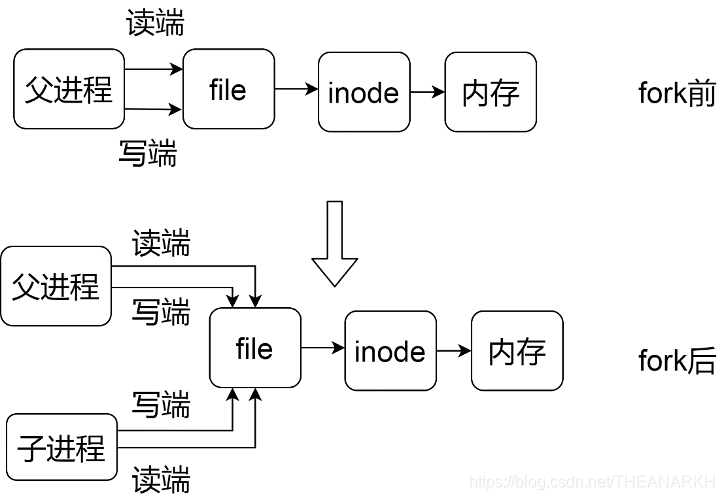
图13-2
主进程和子进程通过共享file和inode结构体,实现对同一块内存的读写。主进程fork创建子进程后,会通过read阻塞等待子进程的消息。我们看一下子进程的逻辑。
static void uv__process_child_init(const uv_process_options_t* options,int stdio_count,int (*pipes)[2],int error_fd) {sigset_t set;int close_fd;int use_fd;int err;int fd;int n;// 省略处理文件描述符等参数逻辑// 处理环境变量if (options->env != NULL) {environ = options->env;}// 处理信号for (n = 1; n < 32; n += 1) {// 这两个信号触发时,默认行为是进程退出且不能阻止的if (n == SIGKILL || n == SIGSTOP)continue; /* Can't be changed. */// 设置为默认处理方式if (SIG_ERR != signal(n, SIG_DFL))continue;// 出错则通知主进程uv__write_int(error_fd, UV__ERR(errno));_exit(127);}// 加载新的执行文件execvp(options->file, options->args);// 加载成功则不会走到这,走到这说明加载执行文件失败uv__write_int(error_fd, UV__ERR(errno));_exit(127);}
子进程的逻辑主要是处理文件描述符、信号、设置环境变量等。然后加载新的执行文件。因为主进程和子进程通信的管道对应的文件描述符设置了cloexec标记。所以当子进程加载新的执行文件时,就会关闭用于和主进程通信的管道文件描述符,从而导致主进程读取管道读端的时候返回0,这样主进程就知道子进程成功执行了。
13.2.2 同步创建进程
同步方式创建的进程,主进程会等待子进程退出后才能继续执行。接下来看看如何以同步的方式创建进程。JS层入口函数是spawnSync。spawnSync调用C模块spawn_sync的spawn函数创建进程,我们看一下对应的C模块spawn_sync导出的属性。
void SyncProcessRunner::Initialize(Local<Object> target,Local<Value> unused,Local<Context> context,void* priv) {Environment* env = Environment::GetCurrent(context);env->SetMethod(target, "spawn", Spawn);}
该模块值导出了一个属性spawn,当我们调用spawn的时候,执行的是C++的Spawn。
void SyncProcessRunner::Spawn(const FunctionCallbackInfo<Value>& args) {Environment* env = Environment::GetCurrent(args);env->PrintSyncTrace();SyncProcessRunner p(env);Local<Value> result;if (!p.Run(args[0]).ToLocal(&result)) return;args.GetReturnValue().Set(result);}
Spawn中主要是新建了一个SyncProcessRunner对象并且执行Run方法。我们看一下SyncProcessRunner的Run做了什么。
MaybeLocal<Object> SyncProcessRunner::Run(Local<Value> options) {EscapableHandleScope scope(env()->isolate());Maybe<bool> r = TryInitializeAndRunLoop(options);Local<Object> result = BuildResultObject();return scope.Escape(result);}
执行了TryInitializeAndRunLoop。
Maybe<bool> SyncProcessRunner::TryInitializeAndRunLoop(Local<Value> options) {int r;lifecycle_ = kInitialized;// 新建一个事件循环uv_loop_ = new uv_loop_t;if (!ParseOptions(options).To(&r)) return Nothing<bool>();if (r < 0) {SetError(r);return Just(false);}// 设置子进程执行的时间if (timeout_ > 0) {r = uv_timer_init(uv_loop_, &uv_timer_);uv_unref(reinterpret_cast<uv_handle_t*>(&uv_timer_));uv_timer_.data = this;kill_timer_initialized_ = true;// 开启一个定时器,超时执行KillTimerCallbackr = uv_timer_start(&uv_timer_,KillTimerCallback,timeout_,0);}// 子进程退出时处理函数uv_process_options_.exit_cb = ExitCallback;// 传进去新的loop而不是主进程本身的loopr = uv_spawn(uv_loop_, &uv_process_, &uv_process_options_);uv_process_.data = this;for (const auto& pipe : stdio_pipes_) {if (pipe != nullptr) {r = pipe->Start();if (r < 0) {SetPipeError(r);return Just(false);}}}// 开启一个新的事件循环r = uv_run(uv_loop_, UV_RUN_DEFAULT);return Just(true);}
从上面的代码中,我们可以了解到Node.js是如何实现同步创建进程的。同步创建进程时,Node.js重新开启了一个事件循环,然后新建一个子进程,并且把表示子进程结构体的handle插入到新创建的事件循环中,接着Libuv一直处于事件循环中,因为一直有一个uv_process_t(handle),所以新创建的uv_run会一直在执行,所以这时候,Node.js主进程会”阻塞”在该uv_run。直到子进程退出,主进程收到信号后,删除新创建的事件循环中的uv_process_t。然后执行回调ExitCallback。接着事件循环退出,再次回到Node.js原来的事件循环。如图所示13-3。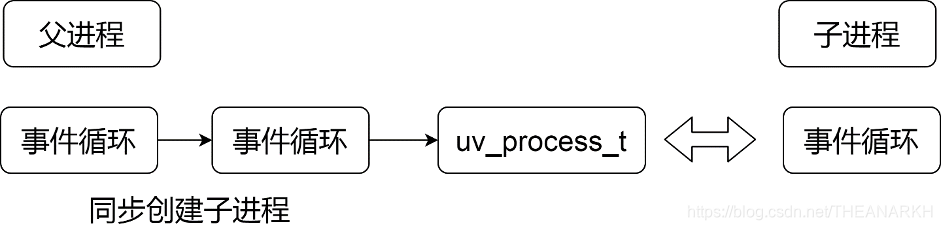
图13-3
这就是同步的本质和原因。我们分几步分析一下以上代码
13.2.2.1 执行时间
因为同步方式创建子进程会导致Node.js主进程阻塞,为了避免子进程有问题,从而影响主进程的执行,Node.js支持可配置子进程的最大执行时间。我们看到,Node.js开启了一个定时器,并设置了回调KillTimerCallback。
void SyncProcessRunner::KillTimerCallback(uv_timer_t* handle) {SyncProcessRunner* self = reinterpret_cast<SyncProcessRunner*>(handle->data);self->OnKillTimerTimeout();}void SyncProcessRunner::OnKillTimerTimeout() {SetError(UV_ETIMEDOUT);Kill();}void SyncProcessRunner::Kill() {if (killed_)return;killed_ = true;if (exit_status_ < 0) {// kill_signal_为用户自定义发送的杀死进程的信号int r = uv_process_kill(&uv_process_, kill_signal_);// 不支持用户传的信号if (r < 0 && r != UV_ESRCH) {SetError(r);// 回退使用SIGKILL信号杀死进程r = uv_process_kill(&uv_process_, SIGKILL);CHECK(r >= 0 || r == UV_ESRCH);}}// Close all stdio pipes.CloseStdioPipes();// 清除定时器CloseKillTimer();}
当执行时间到达设置的阈值,Node.js主进程会给子进程发送一个信号,默认是杀死子进程。
13.2.2.2 子进程退出处理
退出处理主要是记录子进程退出时的错误码和被哪个信号杀死的(如果有的话)。
void SyncProcessRunner::ExitCallback(uv_process_t* handle,int64_t exit_status,int term_signal) {SyncProcessRunner* self = reinterpret_cast<SyncProcessRunner*>(handle->data);uv_close(reinterpret_cast<uv_handle_t*>(handle), nullptr);self->OnExit(exit_status, term_signal);}void SyncProcessRunner::OnExit(int64_t exit_status, int term_signal) {if (exit_status < 0)return SetError(static_cast<int>(exit_status));exit_status_ = exit_status;term_signal_ = term_signal;}
13.3 进程间通信
进程间通信是多进程系统中非常重要的功能,否则进程就像孤岛一样,不能交流信息。因为进程间的内存是隔离的,如果进程间想通信,就需要一个公共的地方,让多个进程都可以访问,完成信息的传递。在Linux中,同主机的进程间通信方式有很多,但是基本都是使用独立于进程的额外内存作为信息承载的地方,然后在通过某种方式让多个进程都可以访问到这块公共内存,比如管道、共享内存、Unix域、消息队列等等。不过还有另外一种进程间通信的方式,是不属于以上情况的,那就是信号。信号作为一种简单的进程间通信方式,操作系统提供了接口让进程可以直接修改另一个进程的数据(PCB),以此达到通信目的。本节介绍Node.js中进程间通信的原理和实现。
13.3.1 创建通信通道
我们从fork函数开始分析Node.js中进程间通信的逻辑。
function fork(modulePath) {// 忽略options参数处理if (typeof options.stdio === 'string') {options.stdio = stdioStringToArray(options.stdio, 'ipc');} else if (!ArrayIsArray(options.stdio)) {// silent为true则是管道形式和主进程通信,否则是继承options.stdio = stdioStringToArray(options.silent ? 'pipe' : 'inherit','ipc');} else if (!options.stdio.includes('ipc')) {// 必须要IPC,支持进程间通信throw new ERR_CHILD_PROCESS_IPC_REQUIRED('options.stdio');}return spawn(options.execPath, args, options);}
我们看一下stdioStringToArray的处理。
function stdioStringToArray(stdio, channel) {const options = [];switch (stdio) {case 'ignore':case 'pipe': options.push(stdio, stdio, stdio); break;case 'inherit': options.push(0, 1, 2); break;default:throw new ERR_INVALID_OPT_VALUE('stdio', stdio);}if (channel) options.push(channel);return options;}
stdioStringToArray会返回一个数组,比如[‘pipe’, ‘pipe’, ‘pipe’, ‘ipc’]或[0, 1, 2, ‘ipc’],ipc代表需要创建一个进程间通信的通道,并且支持文件描述传递。我们接着看spawn。
ChildProcess.prototype.spawn = function(options) {let i = 0;// 预处理进程间通信的数据结构stdio = getValidStdio(stdio, false);const ipc = stdio.ipc;// IPC文件描述符const ipcFd = stdio.ipcFd;stdio = options.stdio = stdio.stdio;// 通过环境变量告诉子进程IPC文件描述符和数据处理模式if (ipc !== undefined) {options.envPairs.push(`NODE_CHANNEL_FD=${ipcFd}`);options.envPairs.push(`NODE_CHANNEL_SERIALIZATION_MODE=${serialization}`);}// 创建子进程const err = this._handle.spawn(options);this.pid = this._handle.pid;// 处理IPC通信if (ipc !== undefined) setupChannel(this, ipc, serialization);return err;}
Spawn中会执行getValidStdio预处理进程间通信的数据结构。我们只关注ipc的。
function getValidStdio(stdio, sync) {let ipc;let ipcFd;stdio = stdio.reduce((acc, stdio, i) => {if (stdio === 'ipc') {ipc = new Pipe(PipeConstants.IPC);ipcFd = i;acc.push({type: 'pipe',handle: ipc,ipc: true});} else {// 其它类型的处理}return acc;}, []);return { stdio, ipc, ipcFd };}
我们看到这里会new Pipe(PipeConstants.IPC);创建一个Unix域用于进程间通信,但是这里只是定义了一个C对象,还没有可用的文件描述符。我们接着往下看C层的spawn中关于进程间通信的处理。C++层首先处理参数,
static void ParseStdioOptions(Environment* env,Local<Object> js_options,uv_process_options_t* options) {Local<Context> context = env->context();Local<String> stdio_key = env->stdio_string();// 拿到JS层stdio的值Local<Array> stdios =js_options->Get(context, stdio_key).ToLocalChecked().As<Array>();uint32_t len = stdios->Length();options->stdio = new uv_stdio_container_t[len];options->stdio_count = len;// 遍历stdio,stdio是一个对象数组for (uint32_t i = 0; i < len; i++) {Local<Object> stdio =stdios->Get(context, i).ToLocalChecked().As<Object>();// 拿到stdio的类型Local<Value> type =stdio->Get(context, env->type_string()).ToLocalChecked();// 创建IPC通道if (type->StrictEquals(env->pipe_string())) {options->stdio[i].flags = static_cast<uv_stdio_flags>(UV_CREATE_PIPE | UV_READABLE_PIPE | UV_WRITABLE_PIPE);// 拿到对应的streamoptions->stdio[i].data.stream = StreamForWrap(env, stdio);}}}
这里会把StreamForWrap的结果保存到stream中,我们看看StreamForWrap的逻辑
static uv_stream_t* StreamForWrap(Environment* env, Local<Object> stdio) {Local<String> handle_key = env->handle_string();/*获取对象中的key为handle的值,即刚才JS层的new Pipe(SOCKET.IPC);*/Local<Object> handle =stdio->Get(env->context(), handle_key).ToLocalChecked().As<Object>();// 获取JS层使用对象所对应的C++对象中的streamuv_stream_t* stream = LibuvStreamWrap::From(env, handle)->stream();CHECK_NOT_NULL(stream);return stream;}// 从JS层使用的object中获取关联的C++对象ibuvStreamWrap* LibuvStreamWrap::From(Environment* env, Local<Object> object) {return Unwrap<LibuvStreamWrap>(object);}
以上代码获取了IPC对应的stream结构体。在Libuv中会把文件描述符保存到stream中。我们接着看C++层调用Libuv的uv_spawn。
int uv_spawn(uv_loop_t* loop,uv_process_t* process,const uv_process_options_t* options) {int pipes_storage[8][2];int (*pipes)[2];int stdio_count;// 初始化进程间通信的数据结构stdio_count = options->stdio_count;if (stdio_count < 3)stdio_count = 3;for (i = 0; i < stdio_count; i++) {pipes[i][0] = -1;pipes[i][1] = -1;}// 创建进程间通信的文件描述符for (i = 0; i < options->stdio_count; i++) {err = uv__process_init_stdio(options->stdio + i, pipes[i]);if (err)goto error;}// 设置进程间通信文件描述符到对应的数据结构for (i = 0; i < options->stdio_count; i++) {uv__process_open_stream(options->stdio + i, pipes[i]);}}
Libuv中会创建用于进程间通信的文件描述符,然后设置到对应的数据结构中。
static int uv__process_open_stream(uv_stdio_container_t* container,int pipefds[2]) {int flags;int err;if (!(container->flags & UV_CREATE_PIPE) || pipefds[0] < 0)return 0;err = uv__close(pipefds[1]);if (err != 0)abort();pipefds[1] = -1;uv__nonblock(pipefds[0], 1);flags = 0;if (container->flags & UV_WRITABLE_PIPE)flags |= UV_HANDLE_READABLE;if (container->flags & UV_READABLE_PIPE)flags |= UV_HANDLE_WRITABLE;return uv__stream_open(container->data.stream, pipefds[0], flags);}
执行完uv__process_open_stream,用于IPC的文件描述符就保存到new Pipe(SOCKET.IPC)中了。有了IPC通道的文件描述符,进程还需要进一步处理。我们看到JS层执行完spawn后,主进程通过setupChannel对进程间通信进行了进一步处理。我们看一下主进程setupChannel中关于进程间通信的处理。
13.3.2 主进程处理通信通道
1 读端
function setupChannel(target, channel, serializationMode) {// channel是new Pipe(PipeConstants.IPC);const control = new Control(channel);target.channel = control;// …channel.pendingHandle = null;// 注册处理数据的函数channel.onread = function(arrayBuffer) {// 收到的文件描述符const recvHandle = channel.pendingHandle;channel.pendingHandle = null;if (arrayBuffer) {const nread = streamBaseState[kReadBytesOrError];const offset = streamBaseState[kArrayBufferOffset];const pool = new Uint8Array(arrayBuffer, offset, nread);if (recvHandle)pendingHandle = recvHandle;// 解析收到的消息for (const message of parseChannelMessages(channel, pool)) {// 是否是内部通信事件if (isInternal(message)) {// 收到handleif (message.cmd === 'NODE_HANDLE') {handleMessage(message, pendingHandle, true);pendingHandle = null;} else {handleMessage(message, undefined, true);}} else {handleMessage(message, undefined, false);}}}};function handleMessage(message, handle, internal) {const eventName = (internal ? 'internalMessage' : 'message');process.nextTick(emit, eventName, message, handle);}// 开启读channel.readStart();return control;}
onread处理完后会触发internalMessage或message事件,message是用户使用的。
2写端
target._send = function(message, handle, options, callback) {let obj;const req = new WriteWrap();// 发送给对端const err = writeChannelMessage(channel, req, message,handle);return channel.writeQueueSize < (65536 * 2);}
我们看看writeChannelMessage
writeChannelMessage(channel, req, message, handle) {const ser = new ChildProcessSerializer();ser.writeHeader();ser.writeValue(message);const serializedMessage = ser.releaseBuffer();const sizeBuffer = Buffer.allocUnsafe(4);sizeBuffer.writeUInt32BE(serializedMessage.length);// channel是封装了Unix域的对象return channel.writeBuffer(req, Buffer.concat([sizeBuffer,serializedMessage]), handle);},
channel.writeBuffer通过刚才创建的IPC通道完成数据的发送,并且支持发送文件描述符。
13.3.3 子进程处理通信通道
接着我们看看子进程的逻辑,Node.js在创建子进程的时候,主进程会通过环境变量NODE_CHANNEL_FD告诉子进程Unix域通信对应的文件描述符。在执行子进程的时候,会处理这个文件描述符。具体实现在setupChildProcessIpcChannel函数中。
function setupChildProcessIpcChannel() {// 主进程通过环境变量设置该值if (process.env.NODE_CHANNEL_FD) {const fd = parseInt(process.env.NODE_CHANNEL_FD, 10);delete process.env.NODE_CHANNEL_FD;require('child_process')._forkChild(fd, serializationMode);}}
接着执行_forkChild函数。
function _forkChild(fd, serializationMode) {const p = new Pipe(PipeConstants.IPC);p.open(fd);const control = setupChannel(process, p, serializationMode);}
该函数创建一个Pipe对象,然后把主进程传过来的fd保存到该Pipe对象。对该Pipe对象的读写,就是地对fd进行读写。最后执行setupChannel。setupChannel主要是完成了Unix域通信的封装,包括处理接收的消息、发送消息、处理文件描述符传递等,刚才已经分析过,不再具体分析。最后通过在process对象中挂载函数和监听事件,使得子进程具有和主进程通信的能力。所有的通信都是基于主进程通过环境变量NODE_CHANNEL_FD传递过来的fd进行的。
13.4 文件描述符传递
前面我们已经介绍过传递文件描述符的原理,下面我们看看Node.js是如何处理文件描述符传递的。
13.4.1 发送文件描述符
我们看进程间通信的发送函数send的实现
process.send = function(message, handle, options, callback) {return this._send(message, handle, options, callback);};target._send = function(message, handle, options, callback) {// Support legacy function signatureif (typeof options === 'boolean') {options = { swallowErrors: options };}let obj;// 发送文件描述符,handle是文件描述符的封装if (handle) {message = {cmd: 'NODE_HANDLE',type: null,msg: message};// handle的类型if (handle instanceof net.Socket) {message.type = 'net.Socket';} else if (handle instanceof net.Server) {message.type = 'net.Server';} else if (handle instanceof TCP || handle instanceof Pipe) {message.type = 'net.Native';} else if (handle instanceof dgram.Socket) {message.type = 'dgram.Socket';} else if (handle instanceof UDP) {message.type = 'dgram.Native';} else {throw new ERR_INVALID_HANDLE_TYPE();}// 根据类型转换对象obj = handleConversion[message.type];// 把JS层使用的对象转成C++层对象handle=handleConversion[message.type].send.call(target,message,handle,options);}// 发送const req = new WriteWrap();// 发送给对端const err = writeChannelMessage(channel, req, message, handle);}
Node.js在发送一个封装了文件描述符的对象之前,首先会把JS层使用的对象转成C++层使用的对象。如TCP
send(message, server, options) {return server._handle;}
我们接着看writeChannelMessage。
// channel是new Pipe(PipeConstants.IPC);writeChannelMessage(channel, req, message, handle) {const string = JSONStringify(message) + '\n';return channel.writeUtf8String(req, string, handle);}
我们看一下writeUtf8String
template <enum encoding enc>int StreamBase::WriteString(const FunctionCallbackInfo<Value>& args) {Environment* env = Environment::GetCurrent(args);// new WriteWrap()Local<Object> req_wrap_obj = args[0].As<Object>();Local<String> string = args[1].As<String>();Local<Object> send_handle_obj;// 需要发送文件描述符,C++层对象if (args[2]->IsObject())send_handle_obj = args[2].As<Object>();uv_stream_t* send_handle = nullptr;// 是Unix域并且支持传递文件描述符if (IsIPCPipe() && !send_handle_obj.IsEmpty()) {HandleWrap* wrap;/*send_handle_obj是由C++层创建在JS层使用的对象,解包出真正在C++层使用的对象*/ASSIGN_OR_RETURN_UNWRAP(&wrap, send_handle_obj, UV_EINVAL);// 拿到Libuv层的handle结构体send_handle = reinterpret_cast<uv_stream_t*>(wrap->GetHandle());/*Reference LibuvStreamWrap instance to prevent itfrom being garbage,collected before`AfterWrite` iscalled.*/req_wrap_obj->Set(env->context(),env->handle_string(),send_handle_obj).Check();}Write(&buf, 1, send_handle, req_wrap_obj);}
Write会调用Libuv的uvwrite,uvwrite会把Libuv层的handle中的fd取出来,使用sendmsg传递到其它进程。整个发送的过程本质是从JS层到Libuv层层层揭开要发送的对象,最后拿到一个文件描述符,然后通过操作系统提供的API把文件描述符传递给另一个进程,如图13-4所示。
图13-4
13.4.2 接收文件描述符
分析完发送,我们再看一下接收的逻辑。前面我们分析过,当文件描述符收到数据时,会把文件文件描述符封装成对应的对象。
void LibuvStreamWrap::OnUvRead(ssize_t nread, const uv_buf_t* buf) {HandleScope scope(env()->isolate());Context::Scope context_scope(env()->context());uv_handle_type type = UV_UNKNOWN_HANDLE;// 是否支持传递文件描述符并且有待处理的文件描述符,则判断文件描述符类型if (is_named_pipe_ipc() &&uv_pipe_pending_count(reinterpret_cast<uv_pipe_t*>(stream())) > 0) {type = uv_pipe_pending_type(reinterpret_cast<uv_pipe_t*>(stream()));}// 读取成功if (nread > 0) {MaybeLocal<Object> pending_obj;// 根据类型创建一个新的C++对象表示客户端,并且从服务器中摘下一个fd保存到客户端if (type == UV_TCP) {pending_obj = AcceptHandle<TCPWrap>(env(), this);} else if (type == UV_NAMED_PIPE) {pending_obj = AcceptHandle<PipeWrap>(env(), this);} else if (type == UV_UDP) {pending_obj = AcceptHandle<UDPWrap>(env(), this);} else {CHECK_EQ(type, UV_UNKNOWN_HANDLE);}// 保存到JS层使用的对象中,键是pendingHandleif (!pending_obj.IsEmpty()) {object()->Set(env()->context(),env()->pending_handle_string(),pending_obj.ToLocalChecked()).Check();}}EmitRead(nread, *buf);}
接着我们看看JS层的处理。
channel.onread = function(arrayBuffer) {// 收到的文件描述符const recvHandle = channel.pendingHandle;channel.pendingHandle = null;if (arrayBuffer) {const nread = streamBaseState[kReadBytesOrError];const offset = streamBaseState[kArrayBufferOffset];const pool = new Uint8Array(arrayBuffer, offset, nread);if (recvHandle)pendingHandle = recvHandle;// 解析收到的消息for (const message of parseChannelMessages(channel, pool)) { // 是否是内部通信事件if (isInternal(message)) {if (message.cmd === 'NODE_HANDLE') {handleMessage(message, pendingHandle, true);pendingHandle = null;} else {handleMessage(message, undefined, true);}} else {handleMessage(message, undefined, false);}}}};
这里会触发内部事件internalMessage
target.on('internalMessage', function(message, handle) {// 是否收到了handleif (message.cmd !== 'NODE_HANDLE') return;// 成功收到,发送ACKtarget._send({ cmd: 'NODE_HANDLE_ACK' }, null, true);const obj = handleConversion[message.type];/*C++对象转成JS层使用的对象。转完之后再根据里层的字段message.msg进一步处理,或者触发message事件传给用户*/obj.got.call(this, message, handle, (handle) => {handleMessage(message.msg, handle, isInternal(message.msg)); });})
我们看到这里会把C++层的对象转成JS层使用的对象。如TCP
got(message, handle, emit) {const server = new net.Server();server.listen(handle, () => {emit(server);});}
这就是文件描述符传递在Node.js中的处理流程,传递文件描述符是一个非常有用的能力,比如一个进程可以把一个TCP连接所对应的文件描述符直接发送给另一个进程处理。这也是cluser模块的原理。后续我们会看到。在Node.js中,整体的处理流程就是,发送的时候把一个JS层使用的对象一层层地剥开,变成C++对象,然后再变成fd,最后通过底层API传递给另一个进程。接收的时候就是把一个fd一层层地包裹,变成一个JS层使用的对象。

若有收获,就点个赞吧
0 人点赞
