React-Router 是 React 场景下的路由解决方案,本讲将学习 React-Router 的实现机制,并基于此提取和探讨通用的前端路由解决方案。
【注】:没有使用过 React-Router 的可以点击这里 完成快速上手。
1、认识 React-Router
本着尽快进入主题的原则,这里用一个尽可能简单的 Demo 作为引子来帮助大家快速地把握 React-Router 的核心功能。请看下面代码(解析在注释里):
import React from "react";// 引入 React-Router 中的相关组件import { BrowserRouter as Router, Route, Link } from "react-router-dom";// 导出目标组件const BasicExample = () => (// 组件最外层用 Router 包裹<Router><div><ul><li>// 具体的标签用 Link 包裹<Link to="/">Home</Link></li><li>// 具体的标签用 Link 包裹<Link to="/about">About</Link></li><li>// 具体的标签用 Link 包裹<Link to="/dashboard">Dashboard</Link></li></ul><hr />// Route 是用于声明路由映射到应用程序的组件层<Route exact path="/" component={Home} /><Route path="/about" component={About} /><Route path="/dashboard" component={Dashboard} /></div></Router>);// Home 组件的定义const Home = () => (<div><h2>Home</h2></div>);// About 组件的定义const About = () => (<div><h2>About</h2></div>);// Dashboard 的定义const Dashboard = () => (<div><h2>Dashboard</h2></div>);export default BasicExample;
这个 Demo 渲染出的页面效果如下图所示: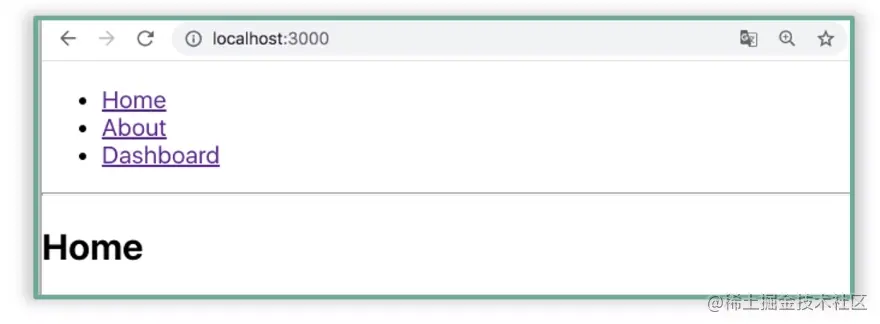
当点击不同的链接时,ul 元素内部就会展示不同的组件内容。比如点击“About”链接时,就会展示 About 组件的内容,效果如下图所示: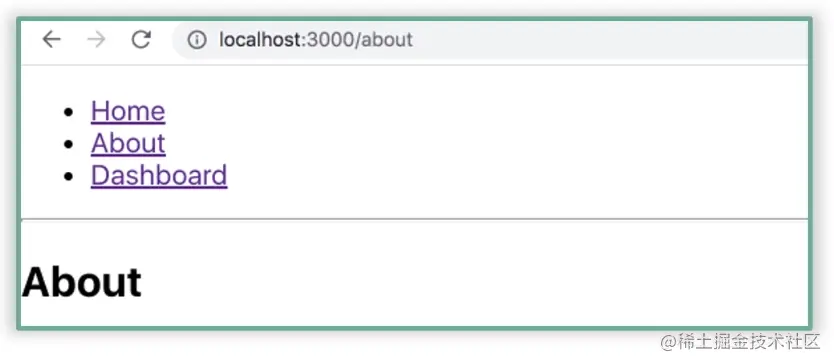
注意,点击 About 后,界面中发生变化的地方有两处(见下图标红处),除了 ul 元素的内容改变了之外,路由信息也改变了。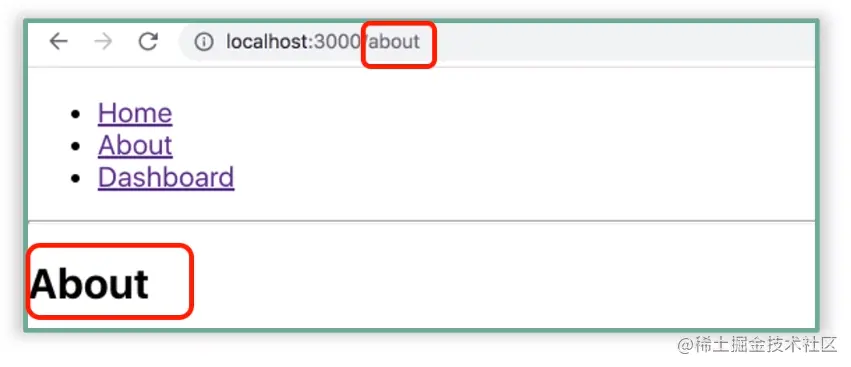
在 React-Router 中,各种细碎的功能点有不少,但作为 React 框架的前端路由解决方案,它最基本也是最核心的能力——路由的跳转。这也是接下来讨论的重点。
接下来就结合 React-Router 的源码,一起来看看“跳转”这个动作是如何实现的。
2、React-Router 是如何实现路由跳转的?
首先需要回顾下 Demo 中的第一行代码:
import { BrowserRouter as Router, Route, Link } from “react-router-dom”; 复制代码
这行代码是为了:实现一个简单的路由跳转效果,一共从 React-Router 中引入了以下 3 个组件:
- BrowserRouter
- Route
- Link
这 3 个组件也就代表了 React-Router 中的 3 个核心角色:
- 路由器,比如 BrowserRouter 和 HashRouter
- 路由,比如 Route 和 Switch
- 导航,比如 Link、NavLink、Redirect
路由(以 Route 为代表)负责定义路径与组件之间的映射关系,而导航(以 Link 为代表)负责触发路径的改变,路由器(包括 BrowserRouter 和 HashRouter)则会根据 Route 定义出来的映射关系,为新的路径匹配它对应的逻辑。
以上便是 3 个角色“打配合”的过程。这其中,最需要注意的是【路由器】这个角色,React Router 曾在说明文档中官宣它是“React Router 应用程序的核心”。因此学习 React Router,最要紧的是搞明白路由器的工作机制。
3、路由器:BrowserRouter 和 HashRouter
路由器负责感知路由的变化并作出反应,它是整个路由系统中最为重要的一环。 React-Router 支持我们使用 hash(对应 HashRouter)和 browser(对应 BrowserRouter) 两种路由规则,这里把两种规则都讲一下。
HashRouter、BrowserRouter,这两个路由规则名字相像,那底层逻辑会不会区别不大呢?的确如此。首先来看一看 HashRouter 的源码: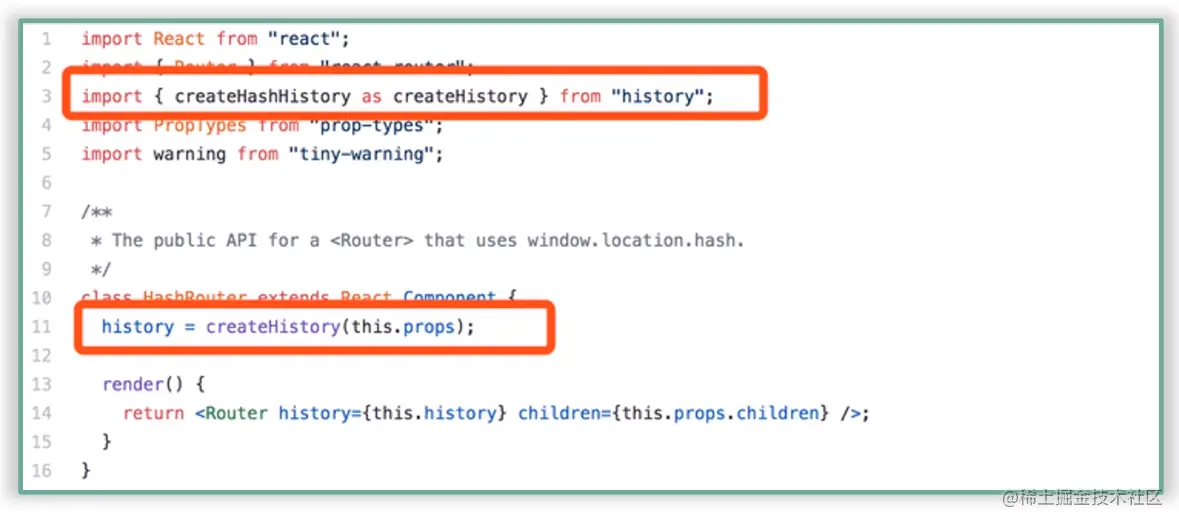
再瞟一眼 BrowserRouter 的源码: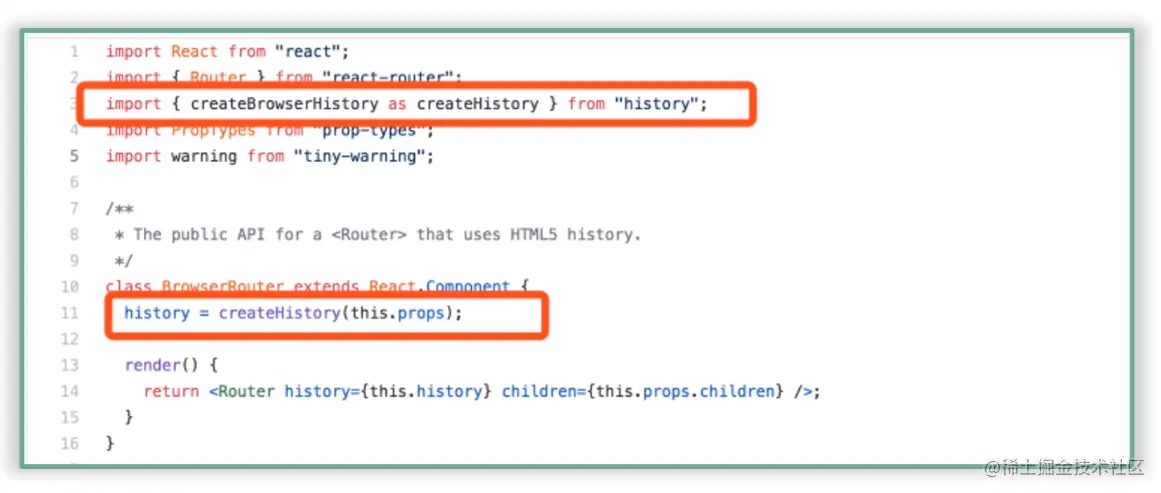

对比之下你会发现这两个文件惊人的相似,而最关键的区别也已经在图中分别标出,即它们调用的 history 实例化方法不同:HashRouter 调用了 createHashHistory,BrowserRouter 调用了 createBrowserHistory。
这两个 history 的实例化方法均来源于 history 这个独立的代码库,这里不必纠结于它的实现细节。对于 createHashHistory 和 createBrowserHistory 这两个 API,重点是掌握它们各自的特征。
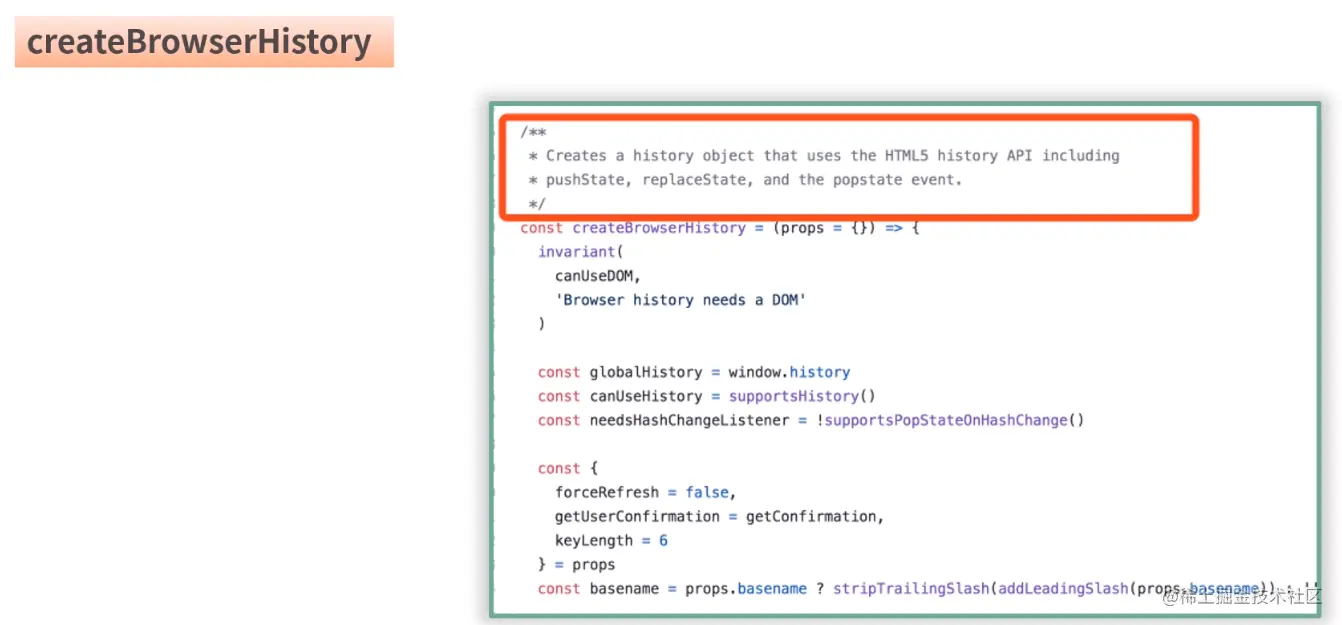
- createBrowserHistory:它将在浏览器中使用 HTML5 history API 来处理 URL(见下图标红处的说明),它能够处理形如这样的 URL,example.com/some/path。由此可得,BrowserRouter 是使用 HTML 5 的 history API 来控制路由跳转的。
- createHashHistory:它是使用 hash tag (#) 处理 URL 的方法,能够处理形如这样的 URL,example.com/#/some/path。可以看到它的源码中对各种方法的定义基本都围绕 hash 展开(如下图所示),由此可得,HashRouter 是通过 URL 的 hash 属性来控制路由跳转的。

【注】:关于 hash 和 history 这两种模式,在下文中还会持续探讨。
现在,见识了表面现象,了解了背后机制。不妨回到故事的原点,再多问自己一个问题:为什么我们需要 React-Router?
或者把这个问题稍微拔高一点:为什么我们需要前端路由?
这一切的一切,都要从很久以前说起。
4、理解前端路由——是什么?解决什么问题?
1)背景——问题的产生
在前端技术早期,一个 URL 对应一个页面,如果你要从 A 页面切换到 B 页面,那么必然伴随着页面的刷新。这个体验并不好,不过在最初也是无奈之举——毕竟用户只有在刷新页面的情况下,才可以重新去请求数据。
后来,改变发生了——Ajax 出现了,它允许人们在不刷新页面的情况下发起请求;与之共生的,还有“不刷新页面即可更新页面内容”这种需求。在这样的背景下,出现了SPA(单页面应用)。
SPA 极大地提升了用户体验,它允许页面在不刷新的情况下更新页面内容,使内容的切换更加流畅。但是在 SPA 诞生之初,人们并没有考虑到“定位”这个问题——在内容切换前后,页面的 URL 都是一样的,这就带来了两个问题:
- SPA 其实并不知道当前的页面“进展到了哪一步”,可能你在一个站点下经过了反复的“前进”才终于唤出了某一块内容,但是此时只要刷新一下页面,一切就会被清零,你必须重复之前的操作才可以重新对内容进行定位——SPA 并不会“记住”你的操作;
- 由于有且仅有一个 URL 给页面做映射,这对 SEO(搜索引擎优化) 也不够友好,搜索引擎无法收集全面的信息。
2)前端路由——SPA“定位”解决方案
前端路由可以帮助我们在仅有一个页面的情况下,“记住”用户当前走到了哪一步——为 SPA 中的各个视图匹配一个唯一标识。这意味着用户前进、后退触发的新内容,都会映射到不同的 URL 上去。此时即便他刷新页面,因为当前的 URL 可以标识出他所处的位置,因此内容也不会丢失。
那么如何实现这个目的呢?首先要解决以下两个问题。
- 当用户刷新页面时,浏览器会默认根据当前 URL 对资源进行重新定位(发送请求)。这个动作对 SPA 是不必要的,因为 SPA 作为单页面,无论如何也只会有一个资源与之对应。此时若走正常的请求-刷新流程,反而会使用户的前进后退操作无法被记录。
- 单页面应用对服务端来说,就是一个 URL、一套资源,那么如何做到用“不同的 URL”来映射不同的视图内容呢?
从这两个问题来看,服务端已经解救不了 SPA 这个场景了。所以要靠前端自力更生,不然怎么叫“前端路由”呢?作为前端,可以提供以下这样的解决思路。
- 拦截用户的刷新操作,避免服务端盲目响应、返回不符合预期的资源内容,把刷新这个动作完全放到前端逻辑里消化掉;
感知 URL 的变化。这里并非要改造 URL或者说是凭空制造出 N 个 URL ;而是说 URL 还是原来的URL,只不过对它进行一些微小的处理,这些处理并不会影响 URL 本身的性质,不会影响服务器对它的识别,只有前端能感知到。一旦感知到了,前端就根据这些变化、用 JS 去给它生成不同的内容。
3)实践思路——hash 与 history
接下来就是重点:现在前端界对前端路由有哪些实现思路?——这里需要掌握的两个实践就是 hash 与 history。
(1)hash 模式
hash 模式是指通过改变 URL 后面以“#”分隔的字符串(这货其实就是 URL 上的哈希值),从而让页面感知到路由变化的一种实现方式。举个例子,比如这样的一个 URL:
https://www.imooc.com/
可以通过增加和改变哈希值,来让这个 URL 变得有那么一点点不一样:
// 主页 https://www.imooc.com/#index// 活动页 https://www.imooc.com/#activePage
这个“不一样”是前端完全可感知的——JS 可以帮我们捕获到哈希值的内容。在 hash 模式下,实现路由的思路可以概括如下:
①hash 的改变:可以通过 location 暴露出来的属性,直接去修改当前 URL 的 hash 值:
window.location.hash = 'index';
②hash 的感知:通过监听 “hashchange”事件,可以用 JS 来捕捉 hash 值的变化,进而决定页面内容是否需要更新:
// 监听hash变化,点击浏览器的前进后退会触发window.addEventListener('hashchange', function(event){// 根据 hash 的变化更新内容},false)
(2)history 模式
大家知道,在浏览器的左上角,往往有这样的操作点:
通过点击前进后退箭头,就可以实现页面间的跳转。这样的行为,其实是可以通过 API 来实现的。
浏览器的 history API 赋予了我们这样的能力,在 HTML 4 时,就可以通过下面的接口来操作浏览历史、实现跳转动作: ```jsx window.history.forward() // 前进到下一页 window.history.back() // 后退到上一页 window.history.go(2) // 前进两页 window.history.go(-2) // 后退两页
很有趣吧?遗憾的是,在这个阶段,只是实现页面“切换”,而不能做到“改变”。但是在**从 HTML 5 开始,浏览器支持了 pushState 和 replaceState 两个 API,允许对浏览历史进行修改和新增**:```jsxhistory.pushState(data[,title][,url]); // 向浏览历史中追加一条记录history.replaceState(data[,title][,url]); // 修改(替换)当前页在浏览历史中的信息
这样可进行修改动作,那么就要有对修改的感知能力。在 history 模式下,可以通过监听 popstate 事件来达到对修改的感知的目的:
window.addEventListener('popstate', function(e) {console.log(e)});
每当浏览历史发生变化,popstate 事件都会被触发。
【注】:go、forward 和 back 等方法的调用确实会触发 popstate,但是pushState 和 replaceState 不会。不过我们可以通过自定义事件和全局事件总线来手动触发事件。
5、总结
本讲以 React-Router 为切入点,结合源码剖析了 React-Router 中“跳转”这一动作的实现原理,由此牵出了针对“前端路由方案”这个知识点相对系统的探讨。至此,详细大家的脑海里对React 周边生态所涉及的重难点知识也有了深刻的记忆。
那么下一讲将围绕“React 设计模式与最佳实践”以及“React 性能优化”两条主线展开学习。彼时,站在“生产实践”这个全新的视角去认识 React 后,相信对react的理解定会更上一层楼!

若有收获,就点个赞吧
0 人点赞
