Java 集合类简介
集合概览
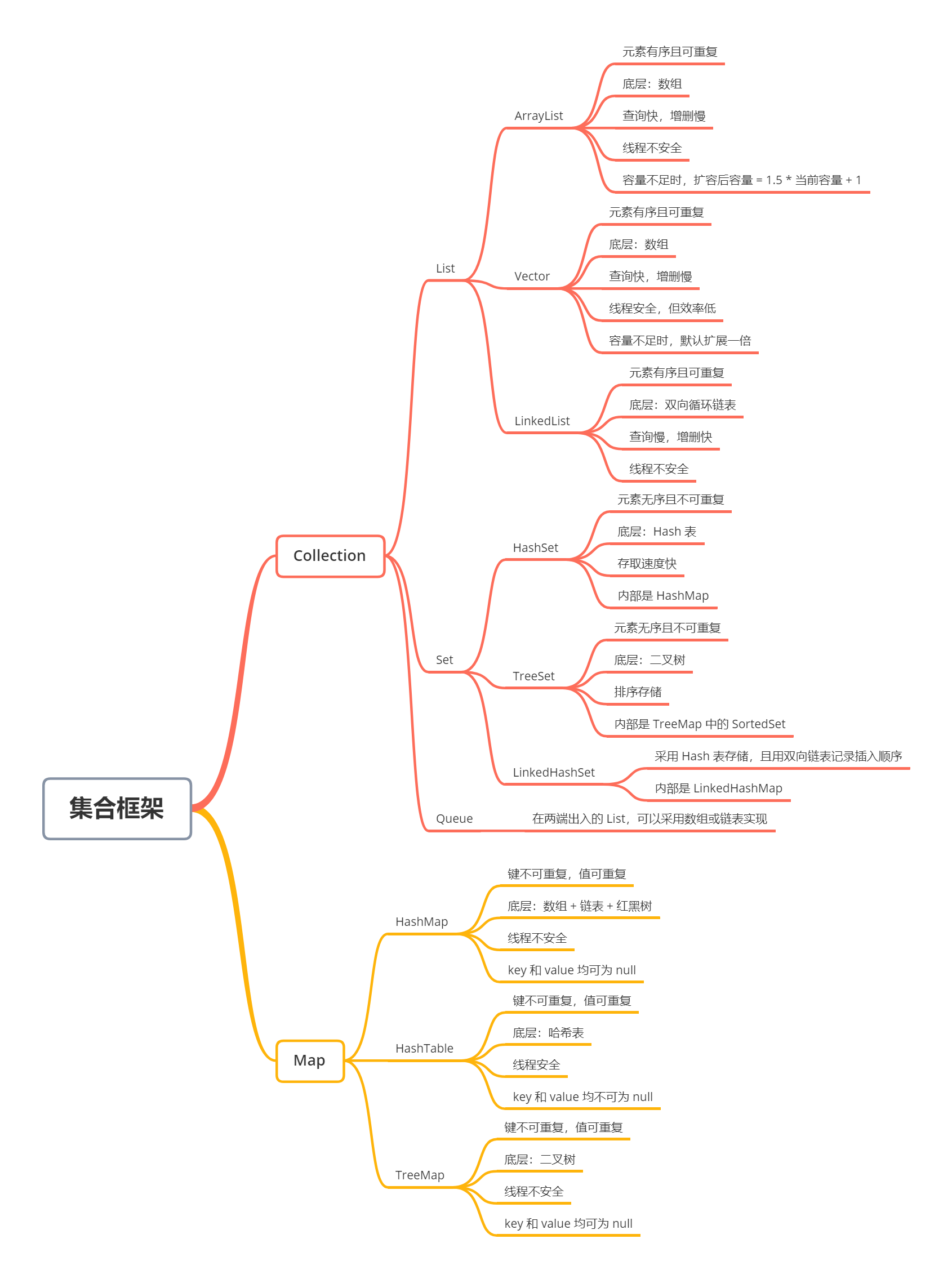
Java 集合类主要都是从 Collection 和 Map 两个接口派生而成,其中 Collection 又包含 List、Set 和 Queue,如下图。Java 集合就像容器,能够将多个同类型的对象装进该容器中,所以又叫容器。其中各集合含义如下:
- Map:代表具有映射关系的集合,通过
key-value存储,其中key是不可重复的,用于标识集合中的每项数据,每个key最多只能映射一个value; - List:代表有序、可重复的集合;
- Set:代表无序、不可重复的集合;
- Queue:队列集合实现;
集合选用技巧
主要根据集合的特点来进行选择:
- 如果需要存放元素值:
- 要保证元素唯一,选用实现
Set接口的集合HashSet或TreeSet; - 不用保证元素唯一,选择实现
List接口的集合ArrayList或LinkedList;
- 要保证元素唯一,选用实现
- 如果需要存放键值对:
- 需要排序:选用
Map接口下的TreeMap; - 无需排序:选用
Map接口下的HashMap; - 保证线程安全:选用
Map接口下的ConcurrentHashMap;
- 需要排序:选用
集合特点
- 对象封装数据,对象多了也需要存储,集合用于存储对象;
- 对象个数确定能够使用数组,但是个数不确定时可以用集合,因为集合是可变长度的;
List、Set、Map 之间的区别
| 元素有序 | 允许元素重复 | ||
|---|---|---|---|
List |
是 | 是 | |
AbstractSet |
否 | 否 | |
Set |
HashSet |
否 | 否 |
TreeSet |
是(二叉树排序) | 否 | |
AbstractMap |
否 | key唯一, value可重复 |
|
Map |
HashMap |
否 | key唯一, value可重复 |
TreeMap |
是(二叉树排序) | key唯一, value可重复 |
集合 vs 数组
集合和数组都是 Java 中重要的数据结构,两者之间的区别主要有如下两点:
| 不同点 | 数组 | 集合 |
|---|---|---|
| 容量 | 初始化时指定,只能存储定长数据 | 保存不定长的数据 |
| 存储的数据类型 | 基本数据类型,对象均可 | 只能是对象(基本数据类型要转换为封装类),而且可以保存 key-value数据 |
| 存储元素类型 | 元素必须是同一数据类型 | 存储的对象可以是不同数据类型 |
Collection
Collection 声明
// // jdk 1.8 中 Collection 的源码public interface Collection<E> extends Iterable<E> {int size();boolean isEmpty();boolean contains(Object o);Iterator<E> iterator();Object[] toArray();<T> T[] toArray(T[] a);boolean add(E e);boolean remove(Object o);boolean containsAll(java.util.Collection<?> c);boolean addAll(java.util.Collection<? extends E> c);boolean removeAll(java.util.Collection<?> c);... //省略了其他方法}
Collection 常用方法
Collection 是 Set、List、Queue 的父接口,主要提供了如下方法供子类实现,从而实现数据操作。
其中 iterator() 方法的返回值 Iterator 接口类叫做 迭代器,主要用于遍历集合元素,定义了如下两个方法:
| 方法 | 说明 |
|---|---|
boolean hasNext() |
若仍有元素可以迭代,则返回 true |
E next() |
返回迭代的下一元素 |
void remove() |
删除指定元素 |
public class Main(){public static void main(String[] args){Collection<Integer> list = new ArrayList<>();for(int i = 0; i < 10; i++){list.add(i);}// 获取迭代器Iterator<Integer> iterator = list.iterator();// 遍历集合while(iterator.hasNext()){Integer value = iterator.next();System.out.print("\t" + value);}}}
Collection 和 Collections
Collection:是一个集合接口,提供了对集合对象进行基本操作的通用接口方法,是所有集合的父类;Collections:是一个包装好的工具类,包含许多静态方法,无法被实例化,比如我们最常用的排序方法Collections.sort(list);
Collection 之 Set
Set 集合继承于 Collection,拥有 Collection 有的所有方法,未提供额外方法。Set 不允许包含重复元素,如果试图将两个相同元素加入同一 Set 中,将导致失败。对象的相等性本质是通过对象的 HashCode 来进行判断,若想要让两个不同的对象视为相等的,就必须覆盖 **Object** 的 **hashCode()** 和 **equals()** 方法。主要可分为如下几类以及他们的底层数据结构为:
- HashSet:无序唯一,基于 HashMap,底层采用 HashMap 保存元素
- LinkedHashSet:继承于 HashSet,内部通过 LinkedHashMap 实现
- TreeSet:有序唯一,基于红黑树实现
HashSet 类
- HashSet 的特点
- 无法保证元素的排列顺序;
HashSet不是同步的(非线程安全),若多个线程同时访问一个HashSet,则必须通过代码来保证其同步;- 集合元素值可以是
null;
- LinkedHashSet
LinkedHashSet 是 HashSet 的子类,同样是根据元素的 hashCode 来决定元素的存储位置,同时用链表维护元素顺序,从而保证元素以插入的顺序来保存。
- HashSet 中判断集合元素相等
不同的对象进行比较,可以有如下四种情况:
- 若两元素通过
equal()方法比较返回false,但两者的hashCode()返回不相等,则将其存储在不同位置; - 若两元素通过
equal()方法比较返回true,但两者的hashCode()返回不相等,则将其存储在不同位置; - 若两元素通过
equal()方法比较返回false,但两者的hashCode()返回相等,则将其存储在相同位置,在这个位置以链表式结构来保存多个对象。因为向HashSet集合中存入一个元素时,HashSet将调用对象的hashCode()获取其hash值,然后根据hash值来决定对象在HashSet中的存储位置; - 若两元素通过
equal()方法比较返回true,且两者的hashCode()返回相等,则不添加到HashSet;
- HashSet 实现原理
基于 HashMap 实现,HashSet 的值存放在 HashMap 的 key 上,其 value 统一为 PRESENT。因此其实现基本都是直接调用底层 HashMap 的相关方法来实现。
- HashMap vs HashSet
| 对比项 | HashMap | HashSet |
| —- | —- | —- |
| 实现的接口 |
Map|Set| | 存储的元素 | 键值对 | 对象 | | 添加元素的方法 |put(key, value)|add()| | HashCode 计算方式 | 利用键key
计算 | 用成员对象进行计算HashCode
值 | | 效率 | 相对较快 | 相对较慢 |
TreeSet 类
- 使用二叉树的原理对新
add()的对象按指定顺序排序,每增加一个对象就会进行排序,将对象插入二叉树指定位置。一组有序的集合,若未指定排序规则Comparator,则按照自然排序; Integer和String对象会按照默认的顺序进行排序,但是自定义的对象是不可以的,自定义的类必须实现**Comparable**接口,且覆写相应的**ComparaTo()**方法,才能正常使用;- 比较一个对象与指定对象的顺序时,若该对象 小于、等于或大于 指定对象,则分别返回 负整数、零或正整数;
HashSet vs LinkedHashSet vs TreeSet
| Set 类型 | 使用场景 | 底层数据结构 |
|---|---|---|
HashSet |
无序无重合,快速查找,元素必须定义 hashCode(),线程不安全,能够存储 null值 |
链表 |
LinkedHashSet |
维护次序的 HashSet,元素必须定义 hashCode(),能按照添加的顺序遍历 |
链表 |
TreeSet |
保持元素大小次序,元素必须实现 Comparable接口,有自然排序和定制排序 |
红黑树 |
Collection 之 List
List 下主要可以分为如下三种,以及他们的底层数据结构分别是:
- ArrayList:Object 数组
- LinkedList:双向循环链表
- Vector:Object 数组
List 常用方法
List 是一个元素有序、可重复的集合,其中的每个元素均有对应的顺序索引,允许使用重复元素,通过索引来访问指定位置的集合元素,继承自 Collection,拥有其所有方法,此外还有其他一些根据索引来操作元素的方法,如下:
| 方法 | 说明 |
|---|---|
void add(int index, Object element) |
在列表的指定位置插入指定元素 |
boolean addAll(int index, Collection<? extends E> c) |
将集合 c中的所有元素都插入到列表中的指定位置 index处 |
Object get(index) |
返回列表中指定位置的元素 |
int indexOf(Object o) |
返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1 |
int lastIndexOf(Object o) |
返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1 |
Object remove(int index) |
移除列表中指定位置的元素 |
Object set(int index, Object element) |
用指定元素替换列表中指定位置的元素 |
List subList(int fromIndex, int toIndex) |
返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的所有集合元素组成的子集 |
Object[] toArray() |
返回按适当顺序包含列表中的所有元素的数组(从第一个元素到最后一个元素) |
void replaceAll(UnaryOperator operator) |
根据 operator指定的计算规则重新设置 List集合的所有元素 |
void sort(Comparator c) |
根据 Comparator参数对 List集合的元素排序 |
ArrayList(数组)
- ArrayList 特点
- 实现了
List接口的可变数组; - 可以插入
null; - 非
synchronized; - 其
size(),isEmpty(),get(),set(),iterator(),add()等方法的时间复杂度均为#card=math&code=O%281%29&id=tdBLj);
- 实现了
- ArrayList 优点
- 底层以数组实现,是一种随机访问模式,实现了
RandomAccess接口,查找时非常快; ArrayList在顺序添加一个元素时非常方便;
- 底层以数组实现,是一种随机访问模式,实现了
- ArrayList 的缺点
- 删除元素时,需要做一次元素复制操作,若复制的元素较多,则性能较慢;
- 插入元素时,也需要做一次元素复制操作,一旦复制元素较多,则会导致性能低下;
- 数组和 List 的相互转换
- 数组 -> List:
Arrays.asList(array)进行转换; - List -> 数组: 利用
List的toArray()进行转换;
- 数组 -> List:
Vector(数组 + 线程同步)
同 ArrayList 一样,底层是通过数组来实现,但是它 支持线程同步,即某一时刻只有一个线程能够读写 **Vector**,从而避免了多线程同时写而引起的不一致性,但实现同步所消耗的代价较高,所以其访问效率比 ArrayList 低;
LinkedList(链表)
LinkedList 是一个链表维护的序列容器,和 ArrayList 最大的区别在于其底层实现,前者使用链表,后者使用数组,所以选用时可以根据数组和链表的特性来进行选择,主要不同有如下几点:
- 数组查找效率高,能够通过索引直接查找出对应元素,但链表却需要每次都从头开始;
- 链表插入和删除元素比较高效,只需要在插入或删除位置断链后重组链即可,但数组需要重新复制一份将所有数据后移或前移;
- 动态申请内存时,链表只需要动态创建,但数组达到初始申请长度后,需要重新申请一个更大的数组,并将原来数组的数据迁移过去;
ArrayList vs LinkedList
| 对比项目 | ArrayList | LinkedList |
|---|---|---|
| 数据结构实现 | 数组 | 双向链表 |
| 随机访问效率 | 高 | 移动指针从前往后依次查找,效率低 |
| 增删效率 | 低 | 高 |
| 内存空间占用 | 低,但是需要连续空间 | 高,除开数据,还有两个引用 |
| 线程安全 | 不安全 | 不安全 |
ArrayList 和 Vector
- 相同点
- 均基于索引,内部由一个数组支持;
- 两者维护插入的顺序,可以根据插入顺序来获取元素;
ArrayList和Vector的迭代器实现都是fail-fast;ArrayList和Vector均允许null值,也可以使用索引值对元素进行随机访问;
- 不同点
Vector是同步的,而ArrayList不是;ArrayList比Vector快,因为有同步,不会过载;ArrayList更加通用,能使用Collections工具类实现轻松操作列表;
List vs Set
- 各自特点
- Set 特点:一个无序容器,不能存储重复元素,只允许存入一个
null,必须保证元素唯一性,该接口的常用实现类为HashSet、TreeSet、LinkedHashSet; - List 特点: 一个有序容器,元素可以重复,允许存入多个
null,元素均有索引,常用实现类为ArrayList、LinkedList、Vector;
- Set 特点:一个无序容器,不能存储重复元素,只允许存入一个
- 两者对比
- Set: 检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置变化;
- List: 类似于数组,能够动态扩展,查找元素效率高,插入和删除元素效率低,因为会导致其他元素位置改变;
Collection 之 Queue
Queue 常用方法
Queue 用于模拟队列这种数据结构,是一种 先进先出(FIFO,**first-in-first-out**) 的容器。队列头部是队列中存放时间最长的元素,尾部元素是队列中存放时间最短的元素。新的元素插入(offer())到队列尾部,访问元素(poll)操作将返回队列头部元素,通常接口中提供了如下方法 :
| 方法 | 说明 |
|---|---|
boolean add(E e) |
将指定元素插入队尾,成功返回 true,空间不足时抛出 IllegalStateException |
E element() |
获取队首元素但不移除 |
boolean offer(E e) |
将指定元素插入队尾,适用于有容量限制的队列(优于 add(E e)) |
E peek() |
获取队首元素但不移除,队列为空返回 null |
E poll() |
获取并移除队首元素,队列为空返回 null |
E remove() |
获取并移除队首元素 |
BlockingQueue
java.util.concurrent.BlcokingQueue 是一个队列,在进行检索或移除一个元素时,都会等待队列变为非空。挡在添加一个元素时,会等待队列中的可用空间。属于 Java 集合框架中的一部分,主要用于实现 生产者-消费者模式。无需担心等待生产者有可用空间或消费者有可用对象。因为在 BlockingQueue 的实现类中都已经进行了处理。主要提供了 ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue 等几种实现方式。
poll() vs remove()
- 相同点:均返回队列第一个元素,并在队列中删除返回的对象;
- 不同的:
Queue中没有元素时poll()将返回null,而remove()将直接抛出NoSuchElementException异常;
Map
// jdk 1.8 中 Map 源码,其中内部接口 Entry<K, V> 对应 Map 的键值对public interface Map<K,V> {int size();boolean containsKey(Object key);boolean containsValue(Object value);V get(Object key);V put(K key, V value);V remove(Object key);void putAll(java.util.Map<? extends K, ? extends V> m);void clear();Set<K> keySet();Collection<V> values();Set<java.util.Map.Entry<K, V>> entrySet();interface Entry<K,V> {K getKey();V getValue();V setValue(V value);boolean equals(Object o);int hashCode();...}boolean equals(Object o);int hashCode();}
Map 可分为如下如下几种,以及他们的底层实现分别是:
- HashMap:JDK 1.8 前由 数组 + 链表组成,其中数组是主体,链表则是为了解决哈希冲突而存在;JDK 1.8 后,当链表长度大于阈值(默认为 8)后,链表将转换为红黑树,从而减少搜索时间;
- LinkedHashMap:继承于 HashMap,底层同 HashMap,在它的基础上增加了一条双向链表;
- HashTable:数组 + 链表,数组是 HashMap 的主体,链表则是为了解决哈希冲突而存在;
- TreeMap:红黑树;
Map 常用方法
Map 用于保存具有映射关系的数据,所以通常保存着两组数,一组保存 key,一组保存 value 。两者都可以是任意引用类型的数据,但是 key 不允许重复。接口中通常提供了如下方法:
| 方法 | 说明 |
|---|---|
void clear() |
从映射中移除所有映射关系 |
boolean containsKey(Object key) |
若映射中包含指定 key的映射关系,返回 true |
boolean containsValue(Object value) |
若映射将一个或多个 key映射到指定值,返回 true |
Set<Map.Entry<K,V>> entrySet() |
返回映射中包含的映射关系的 Set视图 |
boolean equals(Object o) |
比较指定的对象与此映射是否相等 |
V get(Objcet key) |
返回指定建所映射的值;若该映射不含该键的映射关系,则返回 null |
int hashCode() |
返回映射的 hash值 |
boolean isEmpty() |
若映射为包含 key-value映射关系,则返回 true |
Set<K> keySet() |
返回映射中包含的键的 Set视图 |
V put(K key, V value) |
将指定的值与此映射中的指定键关联 |
void putAll(Map<? extends K, ? extends V> m) |
从指定映射中将所有映射关系复制到此映射中 |
V remove(Object key) |
若存在一个键的映射关系,则将其从映射中移除 |
int size() |
返回映射中的 key-value关系数 |
Collection<V> values() |
返回映射中包含的值的 Collection视图 |
HashMap
最基础常用的一种 Map,无序且以散列表的方式进行存储。HashSet 其实就是基于 HashMap,将其 key 作为单个元素进行存储。关于 HashMap 的更多知识,可以参看 HashMap 知多少。
LinkedHashMap
HashMap 的一个子类,和 HashMap 最大的区别在于 LinkedHashMap 遍历时是有序的,可以保存插入时的顺序,使用 Iterator 遍历时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序,同时还可以设置根据最近访问的元素放在最前面(即 LRU);
TreeMap(可排序)
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 **Comparator**进行排序,具体取决于使用的构造方法。TreeMap 的基本操作 containsKey、get、put和 remove 的时间复杂度是 #card=math&code=log%28n%29&id=saTYJ) 。
另外,TreeMap是非同步的。 它的 iterator方法返回的迭代器是 fail-fast 的。
WeakHashMap
除了自身有对 key 的引用之外,若 key 没有其他引用指向它,此时就会自动丢弃该值。
HashMap 和 HashTable 的区别
HashMap允许key和value为null,但HashTable不可以;HashTable是同步的,但HashMap不是,所以HashMap适合单线程,HashTable适合多线程;- JDK 1.4 中引入
LinkedHashMap,是HashMap的子类,要顺序遍历时能轻易从HashMap转向LinkedHashMap,但HashTable中的顺序是不可知的; HashMap提供对key的Set进行遍历,因此它是fail-fast的,但HashTable提供对key的Enumeration进行遍历,不支持fail-fast;
各 Map 类型对比
| Map类型 | 使用场景 | 底层实现 |
|---|---|---|
HashMap |
快速查询 | 散列表 |
LinkedHashMap |
迭代遍历具有顺序(插入顺序 or最近最少使用) |
链表 |
TreeMap |
具有排序,唯一可以返回子树的 Map(subMap()) |
红-黑树 |
WeakHashMap |
弱键映射,映射之外无引用的键,可以被垃圾回收 | 散列表 |
ConcurrentHashMap |
线程安全的 Map |
链表 |
IdentityHashMap |
用 ==代替 equals()对键进行排序,专位解决特殊问题 |
链表 |
其他
线程安全的集合类
- Vector:比 ArrayList 多了个同步化机制,但是效率较低,现在不太建议使用;
- Stack: 堆栈类,先进后出;
- HashTable: 相当于 HashMap 多了个线程安全;
- Enumeration: 枚举,相当于迭代器;
迭代器 Iterator
Iterator 接口提供了遍历任何 Collection 的接口,我们能够从一个 Collection 中使用迭代器方法来获取迭代器实例,它取代了 Java 集合框架中的 Enumeration,允许我们在迭代过程中移除元素;
List<Integer> list = new ArrayList<>();Iterator<Integer> iter = list.iterator();while(iter.hashNext()){// 打印遍历元素System.out.println(iter.next());// 移除元素iter.remove();}

若有收获,就点个赞吧
0 人点赞
