目标
爬取当前时间段豆瓣电影中正在上映的电影的相关信息,如电影名、导演、演员表、上映时间、制作方等信息,然后再通过字典的方式,将其保存在本地文件当中,以便我们查询;
Code
#!/usr/bin/python3# -*- coding:utf-8 -*-# @Time : 2018-11-15 8:24# @Author : Manu# @Site :# @File : doubanMovie.py# @Software: PyCharmimport pprintimport requestsfrom lxml import etree'''爬取豆瓣电影上当前正在上映的电影信息,并保存到文件中'''HEADERS = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36','Refer':'https://movie.douban.com/'}url = 'https://movie.douban.com/cinema/nowplaying/'response = requests.get(url, headers=HEADERS)print(response.text)text = response.texthtml = etree.HTML(text)ul = html.xpath("//ul[@class='lists']")[0]lis = ul.xpath('./li')movies = []for li in lis:title = li.xpath('@data-title')[0]score = li.xpath('@data-score')[0]release = li.xpath('@data-release')[0]duration = li.xpath('@data-duration')[0]region = li.xpath('@data-region')[0]director = li.xpath('@data-director')[0]actors = li.xpath('@data-actors')[0]thumbnail = li.xpath('.//img/@src')[0]movie = {'电影名':title,'评分':score,"上映时间":release,'片长':duration,'制片国家':region,'导演':director,'演员表':actors,'海报':thumbnail}movies.append(movie)pprint.pprint(movies)with open('豆瓣正在上映.txt', 'w', encoding='utf-8') as movie_file:for movie in movies:movie_file.write('电影名:' + movie['电影名'] + '\n')movie_file.write('评分:' + movie['评分'] + '\n')movie_file.write('上映时间:' + movie['上映时间'] + '\n')movie_file.write('片长:' + movie['片长'] + '\n')movie_file.write('制片国家:' + movie['制片国家'] + '\n')movie_file.write('导演:' + movie['导演'] + '\n')movie_file.write('演员表:' + movie['演员表'] + '\n')movie_file.write('海报:' + movie['海报'] + '\n')movie_file.write('\n')
结果
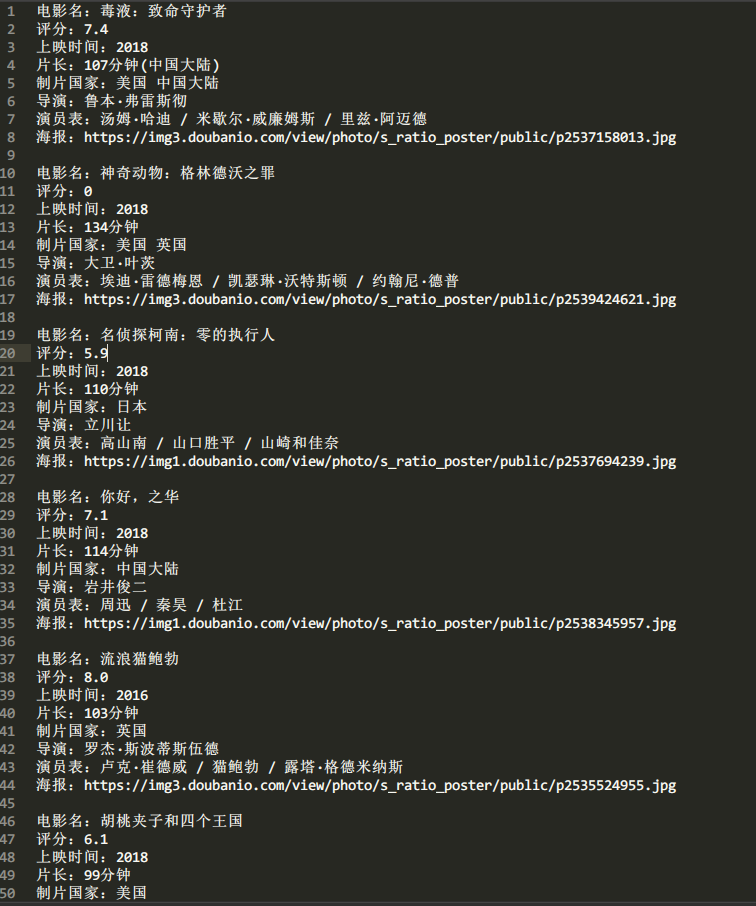

若有收获,就点个赞吧
0 人点赞
