散列的独特之处:线性表和查找树的查找都是建立在「比较」的基础上的,而散列直接「将关键字映射到存储地址」。

散列函数的选择
直接定址法:
Hash(key) = a * key + b
除留余数法:Hash(key) = key % p
假定  是散列表长,那么
是散列表长,那么  是不大于
是不大于  的最大质数。
的最大质数。
冲突的处理办法
开放定址法
将散列表的空闲位开放给同义词
设  为处理冲突时第
为处理冲突时第  次探测的到地址,
次探测的到地址, 是一个序列,则:
是一个序列,则:
不同的  序列选择可以得到不同的冲突处理方法。
序列选择可以得到不同的冲突处理方法。
线性探测法:
会导致相邻的一段地址上散列大量堆积起来
平方探测法:
散列表的长度需要时素数,且可以表示为  的形式
的形式
这种方法无法探测完所有单元,但是至少可以探测完一半空间。不会造成堆积。
双散列法:
伪随机序列法: 是一个伪随机数的序列
是一个伪随机数的序列
拉链法
将同义词存放在一个链表中。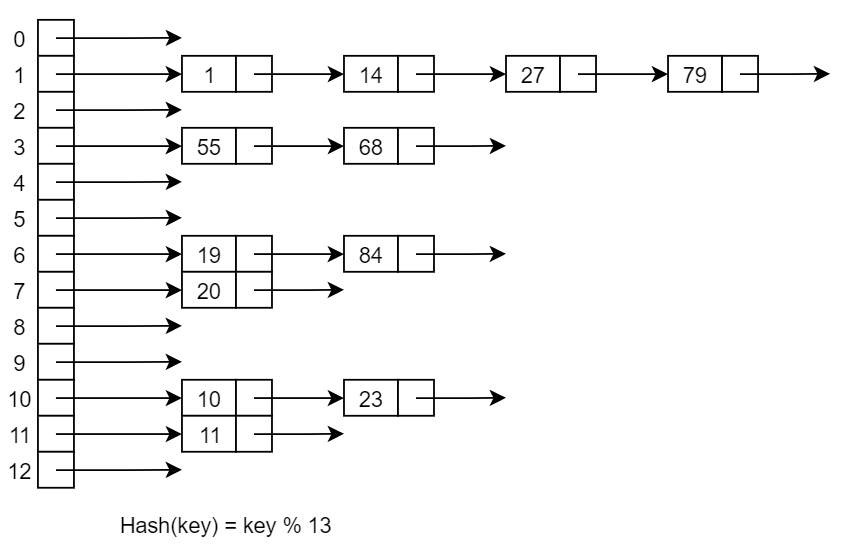
删除元素
如果采用「开放定址法」处理冲突,不能直接删除元素,否则可能会引起搜索中断。
合适的处理方法为:在元素上面做删除标记。
散列查找的效率
由于冲突不可避免,因此散列的查找仍然需要进行「比较」。
散列的查找效率取决于装填因子:

若有收获,就点个赞吧
0 人点赞
