数据可视化的本质就是将数据映射到图形,但是不同类型的数据适合的图形属性不同,可视化的结果也会因此不同。通过了解数据分类以及 G2 的数据分类设计可以帮助你更好得使用 G2 进行图表创作。
数据类型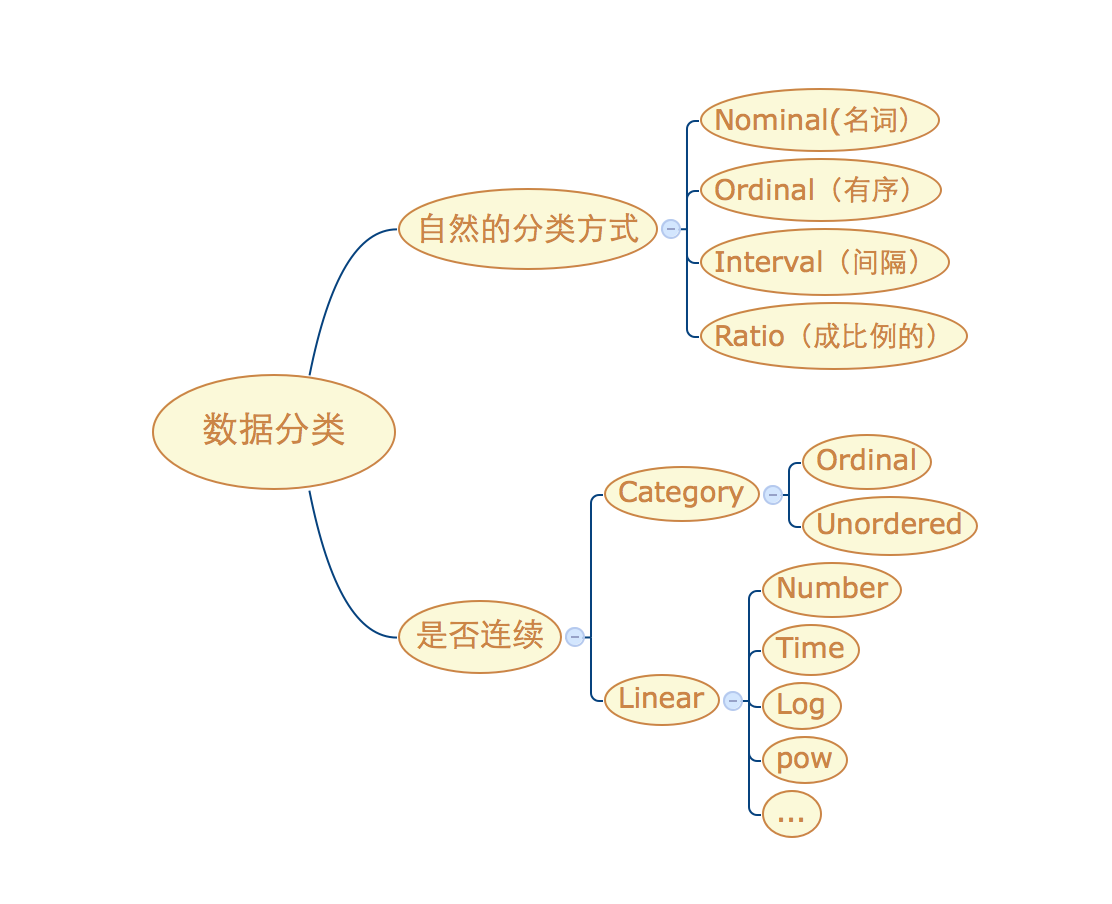
数据的类型可以按照两种分类方式:
数据自然的分类
数据是否连续
数据自然的分类
按照数据的自然分类,可以将数值类型分为:
名词:常见的名词,不关心顺序,比如国家的名称;
有序:有序的分类,例如警报信息,从低到高分为黄色警告、橙色警告和红色警告;
间隔:有间隔的数字,不考虑 0 的意义。例如温度,0 度不代表没有温度;
比例:表示字段之间存在比例关系,0 必须有意义。
数据是否连续
按照数据是否连续划分的方式:
分类(定性)数据,又分为有序的分类和无序的分类;
连续(定量)数据,连续不间断的数值,时间也是一种连续的数据类型。
首先我们来看下面的这组数据:
[{ month: '一月', temperature: 7, city: 'tokyo' },{ month: '二月', temperature: 6.9, city: 'newYork' },{ month: '三月', temperature: 9.5, city: 'tokyo' },{ month: '四月', temperature: 14.5, city: 'tokyo' },{ month: '五月', temperature: 18.2, city: 'berlin' }]
其中:month 代表月份,temperature 代表温度,city 代表城市。
上面数据中
month和city都是离散的分类,但是又有所差异。month是有序的分类类型,而city是无序的分类类型。temperature是连续的数字。
数据类型与度量 scale
我们在 G2 中将数据类型按照是否连续来划分,每种分类设计成不同的度量(Scale),度量用于完成以下功能:
将数据转换到 0-1 范围内,方便将数据映射到位置、颜色、大小等图形属性;
将转换过的数据从 0-1 的范围内反转到原始值。例如
分类a转换成 0.2,那此时 0.2 反转回来的值就是分类a;将数据划分,用于在坐标轴上、图例上显示数值的范围、分类等信息,如下:
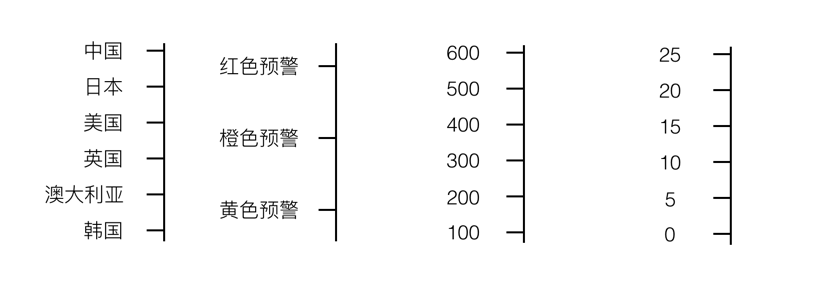
(1)分类信息展示在图例上
(2)确定显示在坐标轴上坐标点 30,40,50,60,70
所以每种度量必须包含以下信息:
定义域(domain),分类度量指的是各种分类值,连续度量则需要指定最小值、最大值;
值域(range),将分类、连续数据映射到范围,默认 0-1;
坐标点(ticks),用于显示在图例或者坐标轴上,对于分类度量,坐标点就是分类类型;连续的数据类型,需要计算出对人比较友好的坐标点、友好的坐标间距,例如:
1,2,3,4,5
0, 5,10,15,20
0.001, 0.005,0.010
而不是:1.1,2.1,3.1,4.1
12,22,32,42,52
G2 的度量类型
G2 中提供了下面几种度量
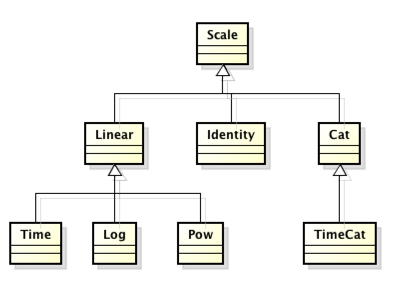
identity,常量类型的数值,也就是说数据的某个字段是不变的常量;
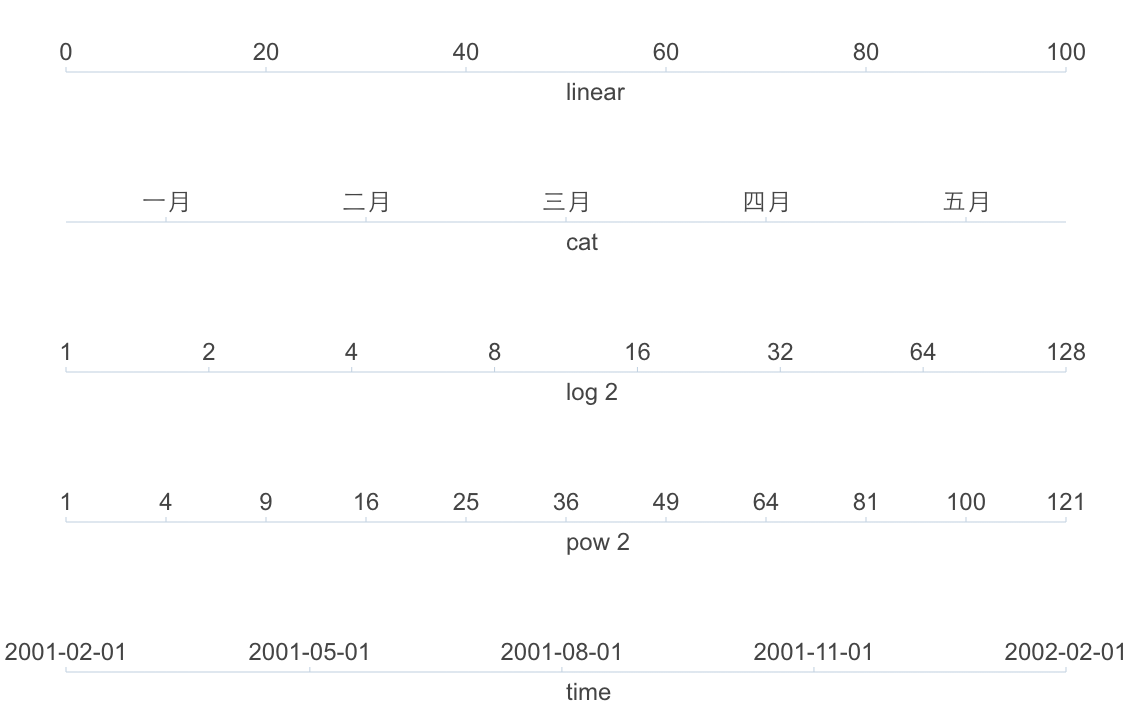
linear,连续的数字 [1, 2, 3, 4, 5];
cat,分类, [‘男’, ‘女’];
time,连续的时间类型;
log,连续非线性的 Log 数据 将 [1, 10, 100, 1000] 转换成 [0, 1, 2, 3];
pow,连续非线性的 pow 数据 将 [2, 4, 8, 16, 32] 转换成 [1, 2, 3, 4, 5];
timeCat,非连续的时间,比如股票的时间不包括周末或者未开盘的日期。

属性和接口设计
度量共有的属性:
| 属性名 | 说明 |
|---|---|
| type | 度量类型 |
| range | 度量转换的值域,默认是[0,1] |
| alias | 别名,大多数数据集合的字段名都是英文,有时候需要定义中文名称,便于在图例、提示信息上显示 |
| ticks | 支持的坐标点,可以在图例、坐标轴上显示,坐标点的计算后面详细介绍 |
| tickCount | 坐标点的个数,不同类型的度量默认值不同 |
| formatter | 输出字段时的格式化函数,会影响数据在坐标轴、图例、提示信息(tooltip)上的显示 |
linear
连续的数据类型的基类,包含以下特殊的属性
| 属性名 | 说明 |
|---|---|
| min | 定义域的最小值 |
| max | 定义域的最大值 |
| tickCount | 连续类型的度量,默认生成坐标点的个数是5 |
| tickInterval | 用于指定坐标轴各个标度点的间距,是原始数据之间的间距差值,tickCount 和 tickInterval 同时声明时以 tickCount 为准 |
| nice | 是否根据人对数字识别的友好度,来调整min和max。例如 min:3,max: 97,如果nice: true,那么会自动调整为:min: 0,max: 100 |
cat
分类类型度量的特殊属性
| 属性名 | 说明 |
|---|---|
| values | 当前字段的分类值 |
G2创建图表的时候,values字段一般会自动从数据中取得,但是以下2中情形下需要用户手动指定
- 需要指定分类的顺序时,例如:type 字段有’最大’,’最小’和’适中’3种类型,我们想指定这些分类在坐标轴或者图例上的顺序时:
[{ a: 'a1', b:'b1', type: '最小' },{ a: 'a2', b:'b2', type: '最大' },{ a: 'a3', b:'b3', type: '适中' }]const defs = {'type': { type: 'cat', values: [ '最小', '适中', '最大' ] }};
如果不声明度量的values字段,那么默认的顺序是:‘最小’,‘最大’,‘适中’
- 如果数据中的分类类型使用枚举的方式表示,那也也需要指定values
[{ a: 'a1', b:'b1', type: 0 },{ a: 'a2', b:'b2', type: 2 },{ a: 'a3', b:'b3', type: 1 }]const defs = {'type': { type: 'cat', values: [ '最小', '适中', '最大' ] }};
必须指定’cat’类型,values的值按照索引跟枚举类型一一对应
time
time类型是一种特殊的连续型数值,所以我们将time类型的度量定义为linear的子类,除了支持所有通用的属性和linear度量的属性外,还有自己特殊的属性:
| 属性名 | 说明 |
|---|---|
| mask | 数据的格式化格式 默认:’YYYY-MM-DD’ |
目前支持 2 种类型的时间(time)类型:
时间戳的数字形式, 1436237115500 // new Date().getTime()
时间字符串: ‘2015-03-01’, ‘2015-03-01 12:01:40’, ‘2015/01/05’,’2015-03-01T16:00:00.000Z’
格式化日期时mask的占位符,参考 fecha
| Token | Output | |
|---|---|---|
| Month | M | 1 2 … 11 12 |
| MM | 01 02 … 11 12 | |
| MMM | Jan Feb … Nov Dec | |
| MMMM | January February … November December | |
| Day of Month | D | 1 2 … 30 31 |
| Do | 1st 2nd … 30th 31st | |
| DD | 01 02 … 30 31 | |
| Day of Week | d | 0 1 … 5 6 |
| ddd | Sun Mon … Fri Sat | |
| dddd | Sunday Monday … Friday Saturday | |
| Year | YY | 70 71 … 29 30 |
| YYYY | 1970 1971 … 2029 2030 | |
| AM/PM | A | AM PM |
| a | am pm | |
| Hour | H | 0 1 … 22 23 |
| HH | 00 01 … 22 23 | |
| h | 1 2 … 11 12 | |
| hh | 01 02 … 11 12 | |
| Minute | m | 0 1 … 58 59 |
| mm | 00 01 … 58 59 | |
| Second | s | 0 1 … 58 59 |
| ss | 00 01 … 58 59 | |
| Fractional Second | S | 0 1 … 8 9 |
| SS | 0 1 … 98 99 | |
| SSS | 0 1 … 998 999 | |
| Timezone | ZZ | -0700 -0600 … +0600 +0700 |
log
log类型的数据可以将非常大范围的数据映射到一个均匀的范围内,这种度量是linear的子类,支持所有通用的属性和linear度量的属性,特有的属性:
| 属性名 | 说明 |
|---|---|
| base | Log 的基数,默认是2 |
以下情形下建议使用log度量
散点图时数据的分布非常广,同时数据分散在几个区间内。例如 分布在 0-100, 10000 - 100000, 1千万 - 1亿内,这时候适合使用log 度量
使用热力图时,数据分布不均匀时也会出现只有非常高的数据点附近才有颜色,此时需要使用log度量,对数据进行log处理。
pow
pow类型的数据也是linear类型的一个子类,除了支持所有通用的属性和linear度量的属性外也有自己的属性:
| 属性名 | 说明 |
|---|---|
| exponent | 指数,默认是2 |
timeCat
timeCat类型的数据,是一种日期数据,但是不是连续的日期。例如代表存在股票交易的日期,此时如果使用time类型,那么节假日没有数据,折线图、k线图会断裂,所以此时使用timeCat的度量表示分类的日期,默认会对数据做排序。
| 属性名 | 说明 |
|---|---|
| tickCount | 此时需要设置坐标点的个数 |
| mask | 数据的格式化格式 |
度量坐标点的计算
度量的信息需要在图例、坐标轴上显示时,不可能全部显示所有的数据,那么就需要选取一些代表性的数据显示在图例、坐标轴上,我们称这些数据为ticks(坐标点),不同的类型的度量计算ticks(坐标点)的算法各不一样,我们这里提供3类度量ticks(坐标点)的计算:
分类度量,包括 cat,timeCat
连续类型度量,包括linear,log,pow
时间类型度量,包括time
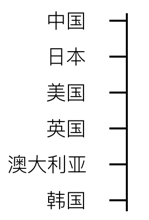
分类度量的计算
分类度量一般情况下不需要计算ticks,直接将所有的分类在图例、坐标轴上显示出来即可
但是当分类类型的数值过多,同时分类间有顺序关系时可以省略掉一些分类例如:
计算时需要使用到的属性:
values: 当前度量的分类值,如果未指定,则直接从数据源中提取
tickCount: 保留几个坐标点
分类的ticks计算非常简单:
均匀的从values中取tickCount个坐标点
为了保证values第一个和最后一个value都在ticks中,取值的间隔是 (values.length - 1) / (tickCount - 1),则保证values第一个和最后一个value都在ticks中
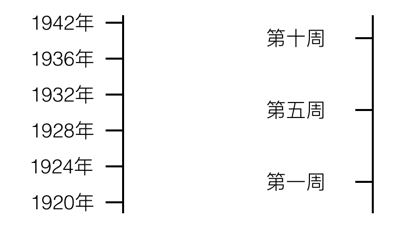
整除的场景:
const values= [ '第一周', '第二周', '第三周', '第四周', '第五周', '第六周', '第七周', '第八周', '第九周' ];const tickCount = 5;// 由于 values.length = 9;// 平均间隔 step = (9 - 1) / (5 - 1) = 2;const ticks = [ '第一周', '第三周', '第五周', '第七周', '第九周' ]
不能整除:
const values= [ '第一周', '第二周', '第三周', '第四周', '第五周' ];const tickCount = 4;// 由于 values.length = 5;// 平均间隔 step = (5 - 1) / (4 - 1) = 4/3; 取整 step = 1;// 舍弃了第四周const ticks = [ '第一周', '第二周', '第三周', '第五周' ]
连续数据度量的计算
连续数据类型计算坐标点需要考虑以下问题:
坐标点必须是对人友好的数据(nice numbers),不能简单的均分的方式计算坐标点。
例如 min: 3,max: 97,tickCount: 6,如果平均划分则会生成 ticks: [3, 21.888,…,78.111,97],我们理想的方式是ticks: [0, 20, 40, 60, 80, 100]计算的数值范围不确定,有可能是 0, 100, 1000 也有可能是 0.01,0.02,0.03
连续数据坐标点的计算方式如下:
指定一个逼近数组 [0,2,5,10],用于计算对人友好的tickInterval
根据传入的min,max,tickCount 计算 tickInterval,将tickInterval的值转换到 0-10之间,保留转换的系数,例如 min: 0, max: 10003, tickCount = 4,那么计算的 tickInterval = 3001 变成 3.001,系数是1000,然后在逼近数组中找到一个逼近值,以 3.001为示例
可以选择向上逼近(最终生成的坐标点个数小于tickCount),得出逼近值 5
或者选择向下逼近(最终生成的坐标点的个数大于tickCount),得出逼近值 2
或者四舍五入(有可能会多,有可能会少),得出逼近值5
将得到的逼近值乘以前面求得的系数1000,
如果逼近值是5,tickInterval = 1000 * 5 = 5000, 将min,和max取tickInterval的倍数,最终计算出来的ticks : [0, 5000, 10000, 15000]
如果逼近值是2,tickInterval = 1000 * 2 = 2000, 将min,和max取tickInterval的倍数,最终计算出来的ticks :[0, 2000, 4000, 6000, 8000, 1000, 12000]
伪代码如下:
const snapArray = [ 0, 2, 5, 10 ];const min = 0;const max = 10003;const tickCount = 4;const tickInterval = (max - min) / (tickCount - 1); // 3001;const factor = getFactor(tickInterval); // 1000,如果value > 10 则不断除以10 直到除数 1<value<10,如果value < 1,则不断乘以10, 直到 1< value < 10const snapValue = snap(snapArray, tickInterval / factor, 'ceil'); // 向上逼近,逼近值5const tickInterval = snapValue * factor;const min = snapMultiple(tickInterval, min, 'floor'); // 向下取tickInterval的整数倍,0const max = snapMultiple(tickInterval, max, 'ceil'); // 向上取tickInterval的整数倍,15000const ticks = [];for(let i = min; i <= max; i += tickInterval){ticks.push(i);}return ticks;
注意事项
snapArray 可以进行调整,数组内部值越多,间距越小,计算出来的tickCount跟预期的差距越小
min,必须向下取tickInterval的倍数,max ,必须向上取tickInterval的倍数
时间类型的度量计算坐标点
时间类型的数据是连续数据,但是不适合连续数据度量的计算方式原因在于:
时间戳的数值比较大,包含毫秒信息,取对人友好的数值格式化出来的时间不一定对人友好,如 1466677570000,是 ’2016 18:26:10‘
对于日期的间隔大于月份,大于年的数据集,没法取得固定的tickInterval,因为月份和年的时间间隔并不相等
所以时间类型的度量需要自己的算法,算法如下:
根据min,max 和 tickCount计算tickInterval;
计算tickInterval 占一年的比例,yfactor = interval / yms(一年的毫秒数)
如果yfactor > 0.51,也就是时间间隔大于半年,取min和max的年份,按照年计算ticks
例如: min: 2001-05-02, max: 2015-10-12, tickCount = 6,此时ticks = [2001-01-01,2004-01-01 2007-01-01,2010-01-01, 2013-01-01, 2016-01-01]如果0.0834 < yfactor < 0.51,时间间隔大于一个月,那么就按月的倍数来计算ticks
例如: min: 2001-05-02,max: 2002-04-03, tickCount = 5, 此时ticks = [2001-05-01, 2001-07-01, 2001-09-01, 2001-11-01, 2002-02-01, 2002-04-01, 2001-06-01]如果时间间隔大于1天,按照天的倍数计算;如果时间间隔大于一个小时,按照小时的倍数计算。。。。然后按照分、秒、毫秒计算ticks
注意事项:
tickCount的值也无法确定最终生成的ticks的个数
必须保证计算出来的ticks的第一个值小于min,最后一个值大于max

若有收获,就点个赞吧
0 人点赞
