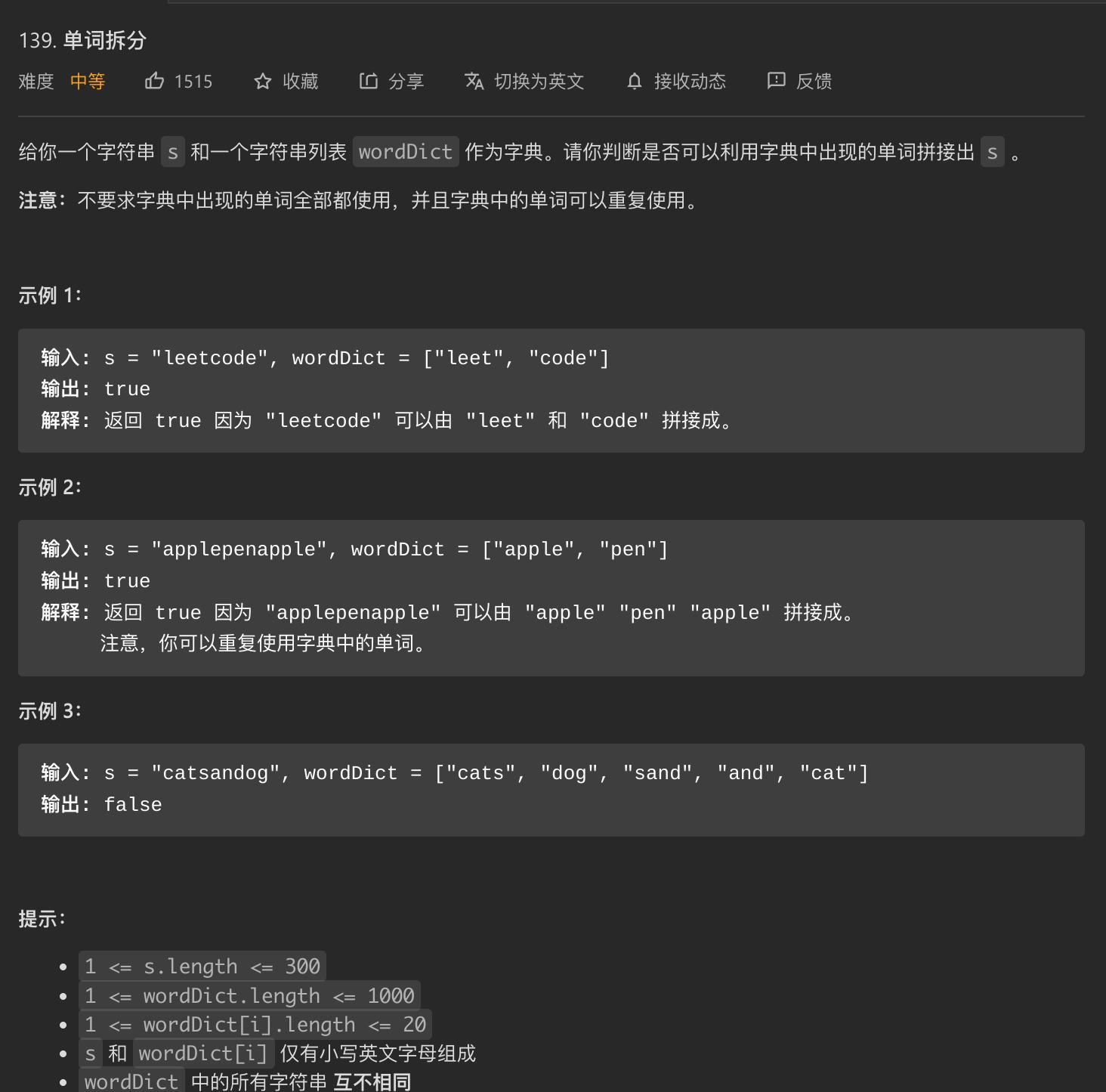
思路:字典树 + 回溯 + 记忆化搜索
- 此题的正解应该是动态规划,但是字典树也可以做
- 对于
wordDict中的每一个word,都需要直通根节点地放置在字典树当中。每个单词的地位是平等的。 - 对于目标字符串
s而言,如果读到了isEnd标志,意味着当前单词读完了,就重新从根节点开始找起,找下一个单词,不断重复这个操作,似乎可以找完整棵树。 - 但是如果出现前缀相同的情况,比如
app apple,先读到app的终结标志,直接就开始找下一个字符了,显然不对,所以需要回溯。 - 但是回溯时间复杂度指数级增长,所以需要用
failCase[i]来表示以第i位的字符开头,必然无法找到需要的单词,防止重复回溯。
代码:
class TrieNode:def __init__(self):self.isEnd = Falseself.children = [None for _ in range(26)]def insert(self, wordDict: List[str]) -> None:# 把所有的字符串放到同一个字典当中# 根节点 - leet && 根节点 -- codetrieRoot = selffor word in wordDict:curNode = trieRootfor ch in word:chNum = ord(ch) - ord('a')if curNode.children[chNum] == None:curNode.children[chNum] = TrieNode()curNode = curNode.children[chNum]curNode.isEnd = Trueclass Solution:def __init__(self):# 为记忆化搜索做准备self.failedCase = [False for _ in range(310)]def search(self, rootNode: TrieNode(), s: str, beginPos: int) -> bool:# 记忆化搜索,以beginPos开头的必然不在字典中,所以下次遍历到这个位置的时候直接返回if self.failedCase[beginPos]:return Falseif beginPos == len(s):return TruecurNode = rootNodewhile beginPos < len(s):chNum = ord(s[beginPos]) - ord('a')if curNode.children[chNum] == None:return FalsecurNode = curNode.children[chNum]# 回溯if curNode.isEnd:if (self.search(rootNode, s, beginPos + 1)):return Trueelse:self.failedCase[beginPos + 1] = TruebeginPos += 1return Falsedef wordBreak(self, s: str, wordDict: List[str]) -> bool:rootNode = TrieNode()rootNode.insert(wordDict)return self.search(rootNode, s, 0)

若有收获,就点个赞吧
0 人点赞
